You're encouraged to make pull requests to enhance any "holes" that you may find in the documentation.
Welcome to the LambdaStack documentation center. At this moment, the documentation is on LAMBDASTACK REPO.
This will all be updated by the day!
This the multi-page printable view of this section. Click here to print.
You're encouraged to make pull requests to enhance any "holes" that you may find in the documentation.
Welcome to the LambdaStack documentation center. At this moment, the documentation is on LAMBDASTACK REPO.
This will all be updated by the day!
LambdaStack is NOT a customized version of Kubernetes! LambdaStack IS a complete Kubernetes Automation Platform that also exercises best practices of setting up Kafka, Postgres, RabbitMQ, Elastic Search (Open Distro), HAProxy, Vault, KeyCloak, Apache Ignite, Storage, HA, DR, Multicloud and more.
LambdaStack is fully open sourced and uses the Apache-2.0 license so that you may use it as you see fit. By using the Apache-2.0 license, scans such as Blackduck show no issues for Enterprises.
LambdaStack uses Terraform, Ansible, Docker, and Python. It's also fully Data Driven. Meaning, all of the data is stored in YAML files. It's so dynamic that even some templates are auto-generated based on the YAML data files before passing through the automation engines thus allowing your to customize everything without modifying source code!
Most, if not all, competitors only setup basic automation of Kubernetes. Meaning, they may use YAML data files but they:
Enterprises and Industry are moving toward Digital Transformations but they journey is not simple or fast. There may be many product lines of legacy applications that need to be modernized and/or re-architected to take advantage of the benifits for true Microservices. Also, some industry domains are so specialized that the core group of software engineers are more domain specialist than generalist.
LambdaStack was architected to remove the burden of:
Basically, allow the development teams focus on adding business value and increasing time-to-market!
LambdaStack comes with a number of simple defaults that only require Cloud vendor Key/Secret or UserID/Password!
Information in this section helps your user try your project themselves.
What do your users need to do to start using your project? This could include downloading/installation instructions, including any prerequisites or system requirements.
Introductory “Hello World” example, if appropriate. More complex tutorials should live in the Tutorials section.
Consider using the headings below for your getting started page. You can delete any that are not applicable to your project.
LambdaStack works on OSX, Windows, and Linux. You can launch it from your desktop/laptop or from build/jump servers. The following are the basic requirements:
manifest files)If you plan to contribute to the LambdaStack project by doing development then you will need a development and build environment. LambdaStack works on OSX, Windows, and Linux. You can launch it from your desktop/laptop or from build/jump servers. The following are the basic requirements for development:
Where can your user find your project code? How can they install it (binaries, installable package, build from source)? Are there multiple options/versions they can install and how should they choose the right one for them?
Is there any initial setup users need to do after installation to try your project?
As of LambdaStack v1.3, there are two ways to get started:
docker run ... commandThe upcoming pre-relase version, LambdaStack v2.0.0beta, will have a full Admin UI that will use the default APIs/CLI to manage the full automation of Kubernetes
Most of below are actually defaults but they are explain for your reference
manifest files and your SSH key pair (private and public). For example, you may decide to launch from your laptop if you're leaving the default use_public_ips: True. So, create a directory if one does not already exist:
mkdir -p /projects/lambdastack/build/<whatever name you give it>/keys/ssh- Linux/Mac (note:buildwould also happen automatically withlambdastack init...but by creating it and<whatever name you give it>/keys/sshhere you don't have to exit thedocker container) Thelambdastack init -p <cloud provider> -n <use the name you gave it above>(e.g.,lambdastack init -p aws -n demo). Theinitcommand will automatically append the/build/<name you give it>/keys/sshif it is not already present. So, using the example,projects/lambdastack/will havebuild/demo/keys/sshappend to formprojects/lambdastack/build/demo/keys/ssh(the only hardcoded values arebuildat the beginningkeys/sshat the end. The rest are up to you)
ssh-keygen- It will prompt you for a name and a few other items. At the end it will generate a private and public key (e.g., give it the name and directory - using the example above, give it/projects/lambdastack/build/demo/keys/ssh/and it will create the key pair there). If you left the default keypair name oflambdastack-operationsthen you would seeprojects/lambdastack/build/demo/keys/ssh/lambdastack-operationsand another file calledlambdastack-operations.pubin the.../keys/ssh/directory
key and secret from the AWS settings console into the <name you give it>.yml file that was generated by lambdastack init.... Using the example from above, the name of the file would be demo.yml located in the /projects/lambdastack/build/demo directory to create /operations/lambdastack/build/demo/demo.yml. Simply exchange the XXXXXXX value for the corresponding key: and secret: valuescd <whereever the base of projects is located>/projects/lambdastack/Docker... as follows (using the example above):
docker run -it -v $PWD:/shared --rm lambdastack/lambdastack:latest.-v $PWD:/sharedis very important. It represents the drive volume you wish to associate with the container (containers can't persist data so you have to mount a volume [some drive location] to it).$PWDsimply means Present Workding Directory (Linux/Mac). The:/sharedis the name of the volume LambdaStack is looking for.-ittells the container it will be aninteractivecontainer that allows you interact at the command line of the Linux container.-rmtells the container to stop and release itself from memory after you typeexiton the container command line to exit. Thelambdastack/lambdastack:latestis the latest version of lambdastack from the public lambdastack registry athttps://hub.docker.com/lambdastack
/shared directory that shows build/demo/keys/sshIf you wish to pull down the open source repo and execute from there then simply do the following:
Fork option button in the top right in the https://github.com/lambdastack/lambdastack repo. This assumes you have GitHub account already. It will ask where you want the forked version to be copied toClone your newly forked LambdaStack repo onto your local hard drivelsio, a default clusters subdirectory will automatically get created and all of the build information for the cluster will reside there:
./lsio- this is a bash script located in the root directory and usesclustersas the required/shareddirectory needed for thedocker run -it -v $PWD/clusters:/shared --rm lambdastack/lambdastack:{tag}that gets executed by thelsiobash script. An improvement to this would be to allow for passin a parameter of specific location for LambdaStack to store the build information in - great opportunity for a Pull Request (PR)!
The Concepts section helps you learn about the parts of the LambdaStack system and the abstractions LambdaStack uses to represent your cluster, and helps you obtain a deeper understanding of how LambdaStack works.
Different configuration options for LambaStack. There is a minimal and a full option when calling lambdastack init.... Inside the /schema directory at the LambdaStack Github repo is where ALL yml configurations are managed. They are broken down into Cloud providers and on-premise (any).
The following are the breakdowns:
Links below...
This option is mainly for on-premise solutions. However, it can be used in a generic way for other clouds like Oracle Cloud, etc.
There are a number of changes to be made so that it can fit your on-premise or non-standard cloud provider environment.
prefix: staging - (optional) Change this to something else like production if you likename: operations - (optional) Change the user name to anything you likekey_path: lambdastack-operations - (optional) Change the SSH key pair name if you likehostname: ... - (optional/required) If you're good with keeping the default hostname then leave it or change it to support your environment for each host belowip: ... - (optional/required) If you're good with keeping the default 192.168.0.0 IP range then leave it or change it to support your environment for each host belowkind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: any
name: "default"
build_path: "build/path" # This gets dynamically built
specification:
name: lambdastack
prefix: staging # Can be anything you want that helps quickly identify the cluster
admin_user:
name: operations # YOUR-ADMIN-USERNAME
key_path: lambdastack-operations # YOUR-SSH-KEY-FILE-NAME
path: "/shared/build/<name of cluster>/keys/ssh/lambdastack-operations" # Will get dynamically created
components:
repository:
count: 1
machines:
- default-repository
kubernetes_master:
count: 1
machines:
- default-k8s-master1
kubernetes_node:
count: 2
machines:
- default-k8s-node1
- default-k8s-node2
logging:
count: 1
machines:
- default-logging
monitoring:
count: 1
machines:
- default-monitoring
kafka:
count: 2
machines:
- default-kafka1
- default-kafka2
postgresql:
count: 1
machines:
- default-postgresql
load_balancer:
count: 1
machines:
- default-loadbalancer
rabbitmq:
count: 1
machines:
- default-rabbitmq
---
kind: infrastructure/machine
provider: any
name: default-repository
specification:
hostname: repository # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.112 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-k8s-master1
specification:
hostname: master1 # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.101 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-k8s-node1
specification:
hostname: node1 # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.102 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-k8s-node2
specification:
hostname: node2 # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.103 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-logging
specification:
hostname: elk # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.105 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-monitoring
specification:
hostname: prometheus # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.106 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-kafka1
specification:
hostname: kafka1 # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.107 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-kafka2
specification:
hostname: kafka2 # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.108 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-postgresql
specification:
hostname: postgresql # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.109 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-loadbalancer
specification:
hostname: loadbalancer # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.110 # YOUR-MACHINE-IP
---
kind: infrastructure/machine
provider: any
name: default-rabbitmq
specification:
hostname: rabbitmq # YOUR-MACHINE-HOSTNAME
ip: 192.168.100.111 # YOUR-MACHINE-IP
This option is mainly for on-premise solutions. However, it can be used in a generic way for other clouds like Oracle Cloud, etc.
There are a number of changes to be made so that it can fit your on-premise or non-standard cloud provider environment.
prefix: staging - (optional) Change this to something else like production if you likename: operations - (optional) Change the user name to anything you likekey_path: lambdastack-operations - (optional) Change the SSH key pair name if you likekind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: any
name: "default"
build_path: "build/path" # This gets dynamically built
specification:
prefix: staging # Can be anything you want that helps quickly identify the cluster
name: lambdastack
admin_user:
name: operations # YOUR-ADMIN-USERNAME
key_path: lambdastack-operations # YOUR-SSH-KEY-FILE-NAME
path: "/shared/build/<name of cluster>/keys/ssh/lambdastack-operations" # Will get dynamically created
components:
kubernetes_master:
count: 1
machine: kubernetes-master-machine
configuration: default
kubernetes_node:
count: 2
machine: kubernetes-node-machine
configuration: default
logging:
count: 1
machine: logging-machine
configuration: default
monitoring:
count: 1
machine: monitoring-machine
configuration: default
kafka:
count: 2
machine: kafka-machine
configuration: default
postgresql:
count: 0
machine: postgresql-machine
configuration: default
load_balancer:
count: 1
machine: load-balancer-machine
configuration: default
rabbitmq:
count: 0
machine: rabbitmq-machine
configuration: default
ignite:
count: 0
machine: ignite-machine
configuration: default
opendistro_for_elasticsearch:
count: 0
machine: logging-machine
configuration: default
repository:
count: 1
machine: repository-machine
configuration: default
single_machine:
count: 0
machine: single-machine
configuration: default
As of v1.3.4, LambdaStack requires you to change the following attributes in the either the minimal or full configuration YAML. Beginning in v2.0, you will have the option to pass in these parameters to override whatever is present in the yaml file. v2.0 is in active development
All but the last two options are defaults. The last two are
AWS KeyandAWS Secret- these two are required
Attributes to change for the minimal configuration After you run `lambdastack init -p aws -n
prefix: staging - Staging is a default prefix. You can use whatever you like (e.g., production). This value can help group your AWS clusters in the same region for easier maintenancename: ubuntu - This attribute is under specification.admin_user.name. For ubuntu on AWS the default user name is ubuntu. For Redhat we default to operationskey_path: lambdastack-operations - This is the default SSH key file(s) name. This is the name of your SSH public and private key pairs. For example, in this example, one file (private one) would be named lambdastack-operations. The second file (public key) typically has a .pub suffix such as lambdastack-operations.pubuse_public_ips: True - This is the default public IP value. Important, this attribute by default allows for AWS to build your clusters with a public IP interface. We also build a private (non-public) interface using private IPs for internal communication between the nodes. With this attribute set to public it simply allows you easy access to the cluster so you can SSH into it using the name attribute value from above. This is NOT RECOMMENDED for sure not in production and not as a general rule. You should have a VPN or direct connect and route for the clusterregion: us-east-1 - This is the default region setting. This means that your cluster and storage will be created in AWS' us-east-1 region. Important - If you want to change this value in any way, you should use the full configuration and then change ALL references of region in the yaml file. If you do not then you may have services in regions you don't want and that may create problems for youkey: XXXXXXXXXX - This is very important. This, along with secret are used to access your AWS cluster programmatically which LambdaStack needs. This can be found at specification.cloud.credentials.key. This can be found under your AWS Account menu option in Security Credentialssecret: XXXXXXXXXXXXX - This is very important. This, along with key are used to access your AWS cluster programmatically which LambdaStack needs. This can be found at specification.cloud.credentials.secret. This can be found under your AWS Account menu option in Security Credentials. This can only be seen at the time you create it so use the download option and save the file somewhere safe. DO NOT save the file in your source code repo!Now that you have made your changes to the lambdastack apply -f build/<whatever you name your cluster>/<whatever you name your cluster>.yml. Now the building of a LambdaStack cluster will begin. Apply option will generate a final manifest.yml file that will be used for Terraform, Ansible and LambdaStack python code. The manifest.yml will combine the values from below plus ALL yaml configuration files for each service.
---
kind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: aws
name: "default"
build_path: "build/path" # This gets dynamically built
specification:
name: lambdastack
prefix: staging # Can be anything you want that helps quickly identify the cluster
admin_user:
name: ubuntu # YOUR-ADMIN-USERNAME
key_path: lambdastack-operations # YOUR-SSH-KEY-FILE-NAME
path: "/shared/build/<name of cluster>/keys/ssh/lambdastack-operations" # Will get dynamically created
cloud:
k8s_as_cloud_service: False
use_public_ips: True # When not using public IPs you have to provide connectivity via private IPs (VPN)
region: us-east-1
credentials:
key: XXXXXXXXXX # AWS Subscription Key
secret: XXXXXXXXX # AWS Subscription Secret
default_os_image: default
components:
repository:
count: 1
kubernetes_master:
count: 1
kubernetes_node:
count: 2
logging:
count: 1
monitoring:
count: 1
kafka:
count: 2
postgresql:
count: 1
load_balancer:
count: 1
rabbitmq:
count: 1
As of v1.3.4, LambdaStack requires you to change the following attributes in the either the minimal or full configuration YAML. Beginning in v2.0, you will have the option to pass in these parameters to override whatever is present in the yaml file. v2.0 is in active development
All but the last two options are defaults. The last two are
AWS KeyandAWS Secret- these two are required
Attributes to change for the full configuration After you run `lambdastack init -p aws -n
prefix: staging - Staging is a default prefix. You can use whatever you like (e.g., production). This value can help group your AWS clusters in the same region for easier maintenancename: ubuntu - This attribute is under specification.admin_user.name. For ubuntu on AWS the default user name is ubuntu. For Redhat we default to operationskey_path: lambdastack-operations - This is the default SSH key file(s) name. This is the name of your SSH public and private key pairs. For example, in this example, one file (private one) would be named lambdastack-operations. The second file (public key) typically has a .pub suffix such as lambdastack-operations.pubuse_public_ips: True - This is the default public IP value. Important, this attribute by default allows for AWS to build your clusters with a public IP interface. We also build a private (non-public) interface using private IPs for internal communication between the nodes. With this attribute set to public it simply allows you easy access to the cluster so you can SSH into it using the name attribute value from above. This is NOT RECOMMENDED for sure not in production and not as a general rule. You should have a VPN or direct connect and route for the clusterregion: us-east-1 - This is the default region setting. This means that your cluster and storage will be created in AWS' us-east-1 region. Important - If you want to change this value in any way, you should use the full configuration and then change ALL references of region in the yaml file. If you do not then you may have services in regions you don't want and that may create problems for youkey: XXXXXXXXXX - This is very important. This, along with secret are used to access your AWS cluster programmatically which LambdaStack needs. This can be found at specification.cloud.credentials.key. This can be found under your AWS Account menu option in Security Credentialssecret: XXXXXXXXXXXXX - This is very important. This, along with key are used to access your AWS cluster programmatically which LambdaStack needs. This can be found at specification.cloud.credentials.secret. This can be found under your AWS Account menu option in Security Credentials. This can only be seen at the time you create it so use the download option and save the file somewhere safe. DO NOT save the file in your source code repo!Now that you have made your changes to the lambdastack apply -f build/<whatever you name your cluster>/<whatever you name your cluster>.yml. Now the building of a LambdaStack cluster will begin. Apply option will generate a final manifest.yml file that will be used for Terraform, Ansible and LambdaStack python code. The manifest.yml will combine the values from below plus ALL yaml configuration files for each service.
---
kind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: aws
name: "default"
build_path: "build/path" # This gets dynamically built
specification:
prefix: staging # Can be anything you want that helps quickly identify the cluster
name: lambdastack
admin_user:
name: ubuntu # YOUR-ADMIN-USERNAME
key_path: lambdastack-operations # YOUR-SSH-KEY-FILE-NAME
path: "/shared/build/<name of cluster>/keys/ssh/lambdastack-operations" # Will get dynamically created
cloud:
k8s_as_cloud_service: False
vnet_address_pool: 10.1.0.0/20
region: us-east-1
use_public_ips: True # When not using public IPs you have to provide connectivity via private IPs (VPN)
credentials:
key: XXXXXXXXXXX # AWS Subscription Key
secret: XXXXXXXXXXXX # AWS Subscription Secret
network:
use_network_security_groups: True
default_os_image: default
components:
kubernetes_master:
count: 1
machine: kubernetes-master-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.1.0/24
- availability_zone: us-east-1b
address_pool: 10.1.2.0/24
kubernetes_node:
count: 2
machine: kubernetes-node-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.1.0/24
- availability_zone: us-east-1b
address_pool: 10.1.2.0/24
logging:
count: 1
machine: logging-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.3.0/24
monitoring:
count: 1
machine: monitoring-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.4.0/24
kafka:
count: 2
machine: kafka-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.5.0/24
postgresql:
count: 0
machine: postgresql-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.6.0/24
load_balancer:
count: 1
machine: load-balancer-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.7.0/24
rabbitmq:
count: 0
machine: rabbitmq-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.8.0/24
ignite:
count: 0
machine: ignite-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.9.0/24
opendistro_for_elasticsearch:
count: 0
machine: logging-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.10.0/24
repository:
count: 1
machine: repository-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.11.0/24
single_machine:
count: 0
machine: single-machine
configuration: default
subnets:
- availability_zone: us-east-1a
address_pool: 10.1.1.0/24
- availability_zone: us-east-1b
address_pool: 10.1.2.0/24
As of v1.3.4, LambdaStack requires you to change the following attributes in the either the minimal or full configuration YAML. Beginning in v2.0, you will have the option to pass in these parameters to override whatever is present in the yaml file. v2.0 is in active development
All options are defaults. Azure will automatically require you to login into the Azure portal before you can run LambdaStack for Azure unless you use the
service principaloption using theFullconfiguration. With theFullconfiguration you can specify your subscription name and service principal so that it can be machine-to-machine oriented not requiring any interaction
Attributes to change for the minimal configuration After you run `lambdastack init -p azure -n
prefix: staging - Staging is a default prefix. You can use whatever you like (e.g., production). This value can help group your AWS clusters in the same region for easier maintenancename: operations - This attribute is under specification.admin_user.name and the defaultkey_path: lambdastack-operations - This is the default SSH key file(s) name. This is the name of your SSH public and private key pairs. For example, in this example, one file (private one) would be named lambdastack-operations. The second file (public key) typically has a .pub suffix such as lambdastack-operations.pubuse_public_ips: True - This is the default public IP value. Important, this attribute by default allows for AWS to build your clusters with a public IP interface. We also build a private (non-public) interface using private IPs for internal communication between the nodes. With this attribute set to public it simply allows you easy access to the cluster so you can SSH into it using the name attribute value from above. This is NOT RECOMMENDED for sure not in production and not as a general rule. You should have a VPN or direct connect and route for the clusterregion: East US - This is the default region setting. This means that your cluster and storage will be created in Azure East US region. Important - If you want to change this value in any way, you should use the full configuration and then change ALL references of region in the yaml file. If you do not then you may have services in regions you don't want and that may create problems for youNow that you have made your changes to the lambdastack apply -f build/<whatever you name your cluster>/<whatever you name your cluster>.yml. Now the building of a LambdaStack cluster will begin. Apply option will generate a final manifest.yml file that will be used for Terraform, Ansible and LambdaStack python code. The manifest.yml will combine the values from below plus ALL yaml configuration files for each service.
---
kind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: azure
name: "default"
build_path: "build/path" # This gets dynamically built
specification:
name: lambdastack
prefix: staging # Can be anything you want that helps quickly identify the clusterprefix
admin_user:
name: operations # YOUR-ADMIN-USERNAME
key_path: lambdastack-operations # YOUR-SSH-KEY-FILE-NAME
path: "/shared/build/<name of cluster>/keys/ssh/lambdastack-operations" # Will get dynamically created
cloud:
k8s_as_cloud_service: False
use_public_ips: True # When not using public IPs you have to provide connectivity via private IPs (VPN)
region: East US
default_os_image: default
components:
repository:
count: 1
kubernetes_master:
count: 1
kubernetes_node:
count: 2
logging:
count: 1
monitoring:
count: 1
kafka:
count: 2
postgresql:
count: 1
load_balancer:
count: 1
rabbitmq:
count: 1
As of v1.3.4, LambdaStack requires you to change the following attributes in the either the minimal or full configuration YAML. Beginning in v2.0, you will have the option to pass in these parameters to override whatever is present in the yaml file. v2.0 is in active development
All but the last two options are defaults. The last two are
subscription_nameanduse_service_principal- these two are required
Attributes to change for the full configuration After you run `lambdastack init -p azure -n
prefix: staging - Staging is a default prefix. You can use whatever you like (e.g., production). This value can help group your AWS clusters in the same region for easier maintenancename: operations - This attribute is under specification.admin_user.namekey_path: lambdastack-operations - This is the default SSH key file(s) name. This is the name of your SSH public and private key pairs. For example, in this example, one file (private one) would be named lambdastack-operations. The second file (public key) typically has a .pub suffix such as lambdastack-operations.pubuse_public_ips: True - This is the default public IP value. Important, this attribute by default allows for AWS to build your clusters with a public IP interface. We also build a private (non-public) interface using private IPs for internal communication between the nodes. With this attribute set to public it simply allows you easy access to the cluster so you can SSH into it using the name attribute value from above. This is NOT RECOMMENDED for sure not in production and not as a general rule. You should have a VPN or direct connect and route for the clusterregion: East US - This is the default region setting. This means that your cluster and storage will be created in Azure East US region. Important - If you want to change this value in any way, you should use the full configuration and then change ALL references of region in the yaml file. If you do not then you may have services in regions you don't want and that may create problems for yousubscription_name: <whatever the sub name is> - This is very important. This, along with use_service_principal are used to access your Azure cluster programmatically which LambdaStack needs. This can be found at specification.cloud.subscrition_name. This can be found under your Azure Account menu option in settingsuse_service_principal: True - This is very important. This, along with subcription_name are used to access your Azure cluster programmatically which LambdaStack needs. This can be found at specification.cloud.use_service_principal. This can be found under your Azure Account menu option in Security Credentials.Now that you have made your changes to the lambdastack apply -f build/<whatever you name your cluster>/<whatever you name your cluster>.yml. Now the building of a LambdaStack cluster will begin. Apply option will generate a final manifest.yml file that will be used for Terraform, Ansible and LambdaStack python code. The manifest.yml will combine the values from below plus ALL yaml configuration files for each service.
---
kind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: azure
name: "default"
build_path: "build/path" # This gets dynamically built
specification:
prefix: staging # Can be anything you want that helps quickly identify the cluster
name: lambdastack
admin_user:
name: operations # YOUR-ADMIN-USERNAME
key_path: lambdastack-operations # YOUR-SSH-KEY-FILE-NAME
path: "/shared/build/<name of cluster>/keys/ssh/lambdastack-operations" # Will get dynamically created
cloud:
k8s_as_cloud_service: False
subscription_name: <YOUR-SUB-NAME>
vnet_address_pool: 10.1.0.0/20
use_public_ips: True # When not using public IPs you have to provide connectivity via private IPs (VPN)
use_service_principal: False
region: East US
network:
use_network_security_groups: True
default_os_image: default
components:
kubernetes_master:
count: 1
machine: kubernetes-master-machine
configuration: default
subnets:
- address_pool: 10.1.1.0/24
kubernetes_node:
count: 2
machine: kubernetes-node-machine
configuration: default
subnets:
- address_pool: 10.1.1.0/24
logging:
count: 1
machine: logging-machine
configuration: default
subnets:
- address_pool: 10.1.3.0/24
monitoring:
count: 1
machine: monitoring-machine
configuration: default
subnets:
- address_pool: 10.1.4.0/24
kafka:
count: 2
machine: kafka-machine
configuration: default
subnets:
- address_pool: 10.1.5.0/24
postgresql:
count: 0
machine: postgresql-machine
configuration: default
subnets:
- address_pool: 10.1.6.0/24
load_balancer:
count: 1
machine: load-balancer-machine
configuration: default
subnets:
- address_pool: 10.1.7.0/24
rabbitmq:
count: 0
machine: rabbitmq-machine
configuration: default
subnets:
- address_pool: 10.1.8.0/24
ignite:
count: 0
machine: ignite-machine
configuration: default
subnets:
- address_pool: 10.1.9.0/24
opendistro_for_elasticsearch:
count: 0
machine: logging-machine
configuration: default
subnets:
- address_pool: 10.1.10.0/24
repository:
count: 1
machine: repository-machine
configuration: default
subnets:
- address_pool: 10.1.11.0/24
single_machine:
count: 0
machine: single-machine
configuration: default
subnets:
- address_pool: 10.1.1.0/24
ALL yaml configuration options listed in this section are for the internal use of LambdaStack only
The content of the applications.yml file is listed for reference only
---
kind: configuration/applications
title: "Kubernetes Applications Config"
name: default
specification:
applications:
## --- ignite ---
- name: ignite-stateless
enabled: false
image_path: "lambdastack/ignite:2.9.1" # it will be part of the image path: {{local_repository}}/{{image_path}}
use_local_image_registry: true
namespace: ignite
service:
rest_nodeport: 32300
sql_nodeport: 32301
thinclients_nodeport: 32302
replicas: 1
enabled_plugins:
- ignite-kubernetes # required to work on K8s
- ignite-rest-http
# Abstract these configs to separate default files and add
# the ability to add custom application roles.
## --- rabbitmq ---
- name: rabbitmq
enabled: false
image_path: rabbitmq:3.8.9
use_local_image_registry: true
#image_pull_secret_name: regcred # optional
service:
name: rabbitmq-cluster
port: 30672
management_port: 31672
replicas: 2
namespace: queue
rabbitmq:
#amqp_port: 5672 #optional - default 5672
plugins: # optional list of RabbitMQ plugins
- rabbitmq_management
- rabbitmq_management_agent
policies: # optional list of RabbitMQ policies
- name: ha-policy2
pattern: ".*"
definitions:
ha-mode: all
custom_configurations: #optional list of RabbitMQ configurations (new format -> https://www.rabbitmq.com/configure.html)
- name: vm_memory_high_watermark.relative
value: 0.5
cluster:
#is_clustered: true #redundant in in-Kubernetes installation, it will always be clustered
#cookie: "cookieSetFromDataYaml" #optional - default value will be random generated string
## --- auth-service ---
- name: auth-service # requires PostgreSQL to be installed in cluster
enabled: false
image_path: lambdastack/keycloak:14.0.0
use_local_image_registry: true
#image_pull_secret_name: regcred
service:
name: as-testauthdb
port: 30104
replicas: 2
namespace: namespace-for-auth
admin_user: auth-service-username
admin_password: PASSWORD_TO_CHANGE
database:
name: auth-database-name
#port: "5432" # leave it when default
user: auth-db-user
password: PASSWORD_TO_CHANGE
## --- pgpool ---
- name: pgpool # this service requires PostgreSQL to be installed in cluster
enabled: false
image:
path: bitnami/pgpool:4.2.4
debug: false # ref: https://github.com/bitnami/minideb-extras/#turn-on-bash-debugging
use_local_image_registry: true
namespace: postgres-pool
service:
name: pgpool
port: 5432
replicas: 3
pod_spec:
affinity:
podAntiAffinity: # prefer to schedule replicas on different nodes
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pgpool
topologyKey: kubernetes.io/hostname
nodeSelector: {}
tolerations: {}
resources: # Adjust to your configuration, see https://www.pgpool.net/docs/41/en/html/resource-requiremente.html
limits:
# cpu: 900m # Set according to your env
memory: 310Mi
requests:
cpu: 250m # Adjust to your env, increase if possible
memory: 310Mi
pgpool:
# https://github.com/bitnami/bitnami-docker-pgpool#configuration + https://github.com/bitnami/bitnami-docker-pgpool#environment-variables
env:
PGPOOL_BACKEND_NODES: autoconfigured # you can use custom value like '0:pg-node-1:5432,1:pg-node-2:5432'
# Postgres users
PGPOOL_POSTGRES_USERNAME: ls_pgpool_postgres_admin # with SUPERUSER role to use connection slots reserved for superusers for K8s liveness probes, also for user synchronization
PGPOOL_SR_CHECK_USER: ls_pgpool_sr_check # with pg_monitor role, for streaming replication checks and health checks
# ---
PGPOOL_ADMIN_USERNAME: ls_pgpool_admin # Pgpool administrator (local pcp user)
PGPOOL_ENABLE_LOAD_BALANCING: true # set to 'false' if there is no replication
PGPOOL_MAX_POOL: 4
PGPOOL_CHILD_LIFE_TIME: 300 # Default value, read before you change: https://www.pgpool.net/docs/42/en/html/runtime-config-connection-pooling.html
PGPOOL_POSTGRES_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_postgres_password
PGPOOL_SR_CHECK_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_sr_check_password
PGPOOL_ADMIN_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_admin_password
secrets:
pgpool_postgres_password: PASSWORD_TO_CHANGE
pgpool_sr_check_password: PASSWORD_TO_CHANGE
pgpool_admin_password: PASSWORD_TO_CHANGE
# https://www.pgpool.net/docs/41/en/html/runtime-config.html
pgpool_conf_content_to_append: |
#------------------------------------------------------------------------------
# CUSTOM SETTINGS (appended by LambdaStack to override defaults)
#------------------------------------------------------------------------------
# num_init_children = 32
connection_life_time = 900
reserved_connections = 1
# https://www.pgpool.net/docs/42/en/html/runtime-config-connection.html
pool_hba_conf: autoconfigured
## --- pgbouncer ---
- name: pgbouncer
enabled: false
image_path: bitnami/pgbouncer:1.16.0
init_image_path: bitnami/pgpool:4.2.4
use_local_image_registry: true
namespace: postgres-pool
service:
name: pgbouncer
port: 5432
replicas: 2
resources:
requests:
cpu: 250m
memory: 128Mi
limits:
cpu: 500m
memory: 128Mi
pgbouncer:
env:
DB_HOST: pgpool.postgres-pool.svc.cluster.local
DB_LISTEN_PORT: 5432
MAX_CLIENT_CONN: 150
DEFAULT_POOL_SIZE: 25
RESERVE_POOL_SIZE: 25
POOL_MODE: session
CLIENT_IDLE_TIMEOUT: 0
## --- istio ---
- name: istio
enabled: false
use_local_image_registry: true
namespaces:
operator: istio-operator # namespace where operator will be deployed
watched: # list of namespaces which operator will watch
- istio-system
istio: istio-system # namespace where istio control plane will be deployed
istio_spec:
profile: default # Check all possibilities https://istio.io/latest/docs/setup/additional-setup/config-profiles/
name: istiocontrolplane
The content of the backup.yml file is listed for reference only
---
kind: configuration/backup
title: Backup Config
name: default
specification:
components:
load_balancer:
enabled: false
logging:
enabled: false
monitoring:
enabled: false
postgresql:
enabled: false
rabbitmq:
enabled: false
# Kubernetes recovery is not supported by LambdaStack at this point.
# You may create backup by enabling this below, but recovery should be done manually according to Kubernetes documentation.
kubernetes:
enabled: false
The content of the elasticsearch-curator.yml file is listed for reference only
---
kind: configuration/elasticsearch-curator
title: Elasticsearch Curator
name: default
specification:
delete_indices_cron_jobs:
- description: Delete indices older than N days
cron:
hour: 1
minute: 0
enabled: true
filter_list:
- filtertype: age
unit_count: 30
unit: days
source: creation_date
direction: older
- description: Delete the oldest indices to not consume more than N gigabytes of disk space
cron:
minute: 30
enabled: true
filter_list:
- filtertype: space
disk_space: 20
use_age: True
source: creation_date
The content of the feature-mapping.yml file is listed for reference only
---
kind: configuration/feature-mapping
title: "Feature mapping to roles"
name: default
specification:
available_roles:
- name: repository
enabled: true
- name: firewall
enabled: true
- name: image-registry
enabled: true
- name: kubernetes-master
enabled: true
- name: kubernetes-node
enabled: true
- name: helm
enabled: true
- name: logging
enabled: true
- name: opendistro-for-elasticsearch
enabled: true
- name: elasticsearch-curator
enabled: true
- name: kibana
enabled: true
- name: filebeat
enabled: true
- name: logstash
enabled: true
- name: prometheus
enabled: true
- name: grafana
enabled: true
- name: node-exporter
enabled: true
- name: jmx-exporter
enabled: true
- name: zookeeper
enabled: true
- name: kafka
enabled: true
- name: rabbitmq
enabled: true
- name: kafka-exporter
enabled: true
- name: postgresql
enabled: true
- name: postgres-exporter
enabled: true
- name: haproxy
enabled: true
- name: haproxy-exporter
enabled: true
- name: vault
enabled: true
- name: applications
enabled: true
- name: ignite
enabled: true
roles_mapping:
kafka:
- zookeeper
- jmx-exporter
- kafka
- kafka-exporter
- node-exporter
- filebeat
- firewall
rabbitmq:
- rabbitmq
- node-exporter
- filebeat
- firewall
logging:
- logging
- kibana
- node-exporter
- filebeat
- firewall
load_balancer:
- haproxy
- haproxy-exporter
- node-exporter
- filebeat
- firewall
monitoring:
- prometheus
- grafana
- node-exporter
- filebeat
- firewall
postgresql:
- postgresql
- postgres-exporter
- node-exporter
- filebeat
- firewall
custom:
- repository
- image-registry
- kubernetes-master
- node-exporter
- filebeat
- rabbitmq
- postgresql
- prometheus
- grafana
- node-exporter
- logging
- firewall
single_machine:
- repository
- image-registry
- kubernetes-master
- helm
- applications
- rabbitmq
- postgresql
- firewall
- vault
kubernetes_master:
- kubernetes-master
- helm
- applications
- node-exporter
- filebeat
- firewall
- vault
kubernetes_node:
- kubernetes-node
- node-exporter
- filebeat
- firewall
ignite:
- ignite
- node-exporter
- filebeat
- firewall
opendistro_for_elasticsearch:
- opendistro-for-elasticsearch
- node-exporter
- filebeat
- firewall
repository:
- repository
- image-registry
- firewall
- filebeat
- node-exporter
The content of the filebeat.yml file is listed for reference only
---
kind: configuration/filebeat
title: Filebeat
name: default
specification:
kibana:
dashboards:
index: filebeat-*
enabled: auto
disable_helm_chart: false
postgresql_input:
multiline:
pattern: >-
'^\d{4}-\d{2}-\d{2} '
negate: true
match: after
The content of the firewall.yml file is listed for reference only
---
kind: configuration/firewall
title: OS level firewall
name: default
specification:
Debian: # On RHEL on Azure firewalld is already in VM image (pre-installed)
install_firewalld: false # false to avoid random issue "No route to host" even when firewalld service is disabled
firewall_service_enabled: false # for all inventory hosts
apply_configuration: false # if false only service state is managed
managed_zone_name: LambdaStack
rules:
applications:
enabled: false
ports:
- 30104/tcp # auth-service
- 30672/tcp # rabbitmq-amqp
- 31672/tcp # rabbitmq-http (management)
- 32300-32302/tcp # ignite
common: # for all inventory hosts
enabled: true
ports:
- 22/tcp
grafana:
enabled: true
ports:
- 3000/tcp
haproxy:
enabled: true
ports:
- 443/tcp
- 9000/tcp # stats
haproxy_exporter:
enabled: true
ports:
- 9101/tcp
ignite:
enabled: true
ports:
- 8080/tcp # REST API
- 10800/tcp # thin client connection
- 11211/tcp # JDBC
- 47100/tcp # local communication
- 47500/tcp # local discovery
image_registry:
enabled: true
ports:
- 5000/tcp
jmx_exporter:
enabled: true
ports:
- 7071/tcp # Kafka
- 7072/tcp # ZooKeeper
kafka:
enabled: true
ports:
- 9092/tcp
# - 9093/tcp # encrypted communication (if TLS/SSL is enabled)
kafka_exporter:
enabled: true
ports:
- 9308/tcp
kibana:
enabled: true
ports:
- 5601/tcp
kubernetes_master:
enabled: true
ports:
- 6443/tcp # API server
- 2379-2380/tcp # etcd server client API
- 8472/udp # flannel (vxlan backend)
- 10250/tcp # Kubelet API
- 10251/tcp # kube-scheduler
- 10252/tcp # kube-controller-manager
kubernetes_node:
enabled: true
ports:
- 8472/udp # flannel (vxlan backend)
- 10250/tcp # Kubelet API
logging:
enabled: true
ports:
- 9200/tcp
node_exporter:
enabled: true
ports:
- 9100/tcp
opendistro_for_elasticsearch:
enabled: true
ports:
- 9200/tcp
postgresql:
enabled: true
ports:
- 5432/tcp
- 6432/tcp #PGBouncer
prometheus:
enabled: true
ports:
- 9090/tcp
- 9093/tcp # Alertmanager
rabbitmq:
enabled: true
ports:
- 4369/tcp # peer discovery service used by RabbitMQ nodes and CLI tools
# - 5671/tcp # encrypted communication (if TLS/SSL is enabled)
- 5672/tcp # AMQP
# - 15672/tcp # HTTP API clients, management UI and rabbitmqadmin (only if the management plugin is enabled)
- 25672/tcp # distribution server
zookeeper:
enabled: true
ports:
- 2181/tcp # client connections
- 2888/tcp # peers communication
- 3888/tcp # leader election
The content of the grafana.yml file is listed for reference only
---
kind: configuration/grafana
title: "Grafana"
name: default
specification:
grafana_logs_dir: "/var/log/grafana"
grafana_data_dir: "/var/lib/grafana"
grafana_address: "0.0.0.0"
grafana_port: 3000
# Should the provisioning be kept synced. If true, previous provisioned objects will be removed if not referenced anymore.
grafana_provisioning_synced: false
# External Grafana address. Variable maps to "root_url" in grafana server section
grafana_url: "https://0.0.0.0:3000"
# Additional options for grafana "server" section
# This section WILL omit options for: http_addr, http_port, domain, and root_url, as those settings are set by variables listed before
grafana_server:
protocol: https
enforce_domain: false
socket: ""
cert_key: "/etc/grafana/ssl/grafana_key.key"
cert_file: "/etc/grafana/ssl/grafana_cert.pem"
enable_gzip: false
static_root_path: public
router_logging: false
# Variables correspond to ones in grafana.ini configuration file
# Security
grafana_security:
admin_user: admin
admin_password: PASSWORD_TO_CHANGE
# secret_key: ""
# login_remember_days: 7
# cookie_username: grafana_user
# cookie_remember_name: grafana_remember
# disable_gravatar: true
# data_source_proxy_whitelist:
# Database setup
grafana_database:
type: sqlite3
# host: 127.0.0.1:3306
# name: grafana
# user: root
# password: ""
# url: ""
# ssl_mode: disable
# path: grafana.db
# max_idle_conn: 2
# max_open_conn: ""
# log_queries: ""
# Default dashboards predefined and available in online & offline mode
grafana_external_dashboards: []
# # Kubernetes cluster monitoring (via Prometheus)
# - dashboard_id: '315'
# datasource: 'Prometheus'
# # Node Exporter Server Metrics
# - dashboard_id: '405'
# datasource: 'Prometheus'
# # Postgres Overview
# - dashboard_id: '455'
# datasource: 'Prometheus'
# # Node Exporter Full
# - dashboard_id: '1860'
# datasource: 'Prometheus'
# # RabbitMQ Monitoring
# - dashboard_id: '4279'
# datasource: 'Prometheus'
# # Kubernetes Cluster
# - dashboard_id: '7249'
# datasource: 'Prometheus'
# # Kafka Exporter Overview
# - dashboard_id: '7589'
# datasource: 'Prometheus'
# # PostgreSQL Database
# - dashboard_id: '9628'
# datasource: 'Prometheus'
# # RabbitMQ cluster monitoring (via Prometheus)
# - dashboard_id: '10991'
# datasource: 'Prometheus'
# # 1 Node Exporter for Prometheus Dashboard EN v20201010
# - dashboard_id: '11074'
# datasource: 'Prometheus'
# Get dashboards from https://grafana.com/dashboards. Only for online mode
grafana_online_dashboards: []
# - dashboard_id: '4271'
# revision_id: '3'
# datasource: 'Prometheus'
# - dashboard_id: '1860'
# revision_id: '4'
# datasource: 'Prometheus'
# - dashboard_id: '358'
# revision_id: '1'
# datasource: 'Prometheus'
# Deployer local folder with dashboard definitions in .json format
grafana_dashboards_dir: "dashboards" # Replace with your dashboard directory if you have dashboards to include
# User management and registration
grafana_welcome_email_on_sign_up: false
grafana_users:
allow_sign_up: false
# allow_org_create: true
# auto_assign_org: true
auto_assign_org_role: Viewer
# login_hint: "email or username"
default_theme: dark
# external_manage_link_url: ""
# external_manage_link_name: ""
# external_manage_info: ""
# grafana authentication mechanisms
grafana_auth: {}
# disable_login_form: false
# disable_signout_menu: false
# anonymous:
# org_name: "Main Organization"
# org_role: Viewer
# ldap:
# config_file: "/etc/grafana/ldap.toml"
# allow_sign_up: false
# basic:
# enabled: true
grafana_ldap: {}
# verbose_logging: false
# servers:
# host: 127.0.0.1
# port: 389 # 636 for SSL
# use_ssl: false
# start_tls: false
# ssl_skip_verify: false
# root_ca_cert: /path/to/certificate.crt
# bind_dn: "cn=admin,dc=grafana,dc=org"
# bind_password: grafana
# search_filter: "(cn=%s)" # "(sAMAccountName=%s)" on AD
# search_base_dns:
# - "dc=grafana,dc=org"
# group_search_filter: "(&(objectClass=posixGroup)(memberUid=%s))"
# group_search_base_dns:
# - "ou=groups,dc=grafana,dc=org"
# attributes:
# name: givenName
# surname: sn
# username: sAMAccountName
# member_of: memberOf
# email: mail
# group_mappings:
# - name: Main Org.
# id: 1
# groups:
# - group_dn: "cn=admins,ou=groups,dc=grafana,dc=org"
# org_role: Admin
# - group_dn: "cn=editors,ou=groups,dc=grafana,dc=org"
# org_role: Editor
# - group_dn: "*"
# org_role: Viewer
# - name: Alternative Org
# id: 2
# groups:
# - group_dn: "cn=alternative_admins,ou=groups,dc=grafana,dc=org"
# org_role: Admin
grafana_session: {}
# provider: file
# provider_config: "sessions"
grafana_analytics: {}
# reporting_enabled: true
# google_analytics_ua_id: ""
# Set this for mail notifications
grafana_smtp: {}
# host:
# user:
# password:
# from_address:
# Enable grafana alerting mechanism
grafana_alerting:
execute_alerts: true
# error_or_timeout: 'alerting'
# nodata_or_nullvalues: 'no_data'
# concurrent_render_limit: 5
# Grafana logging configuration
grafana_log: {}
# mode: 'console file'
# level: info
# Internal grafana metrics system
grafana_metrics: {}
# interval_seconds: 10
# graphite:
# address: "localhost:2003"
# prefix: "prod.grafana.%(instance_name)s"
# Distributed tracing options
grafana_tracing: {}
# address: "localhost:6831"
# always_included_tag: "tag1:value1,tag2:value2"
# sampler_type: const
# sampler_param: 1
grafana_snapshots: {}
# external_enabled: true
# external_snapshot_url: "https://snapshots-origin.raintank.io"
# external_snapshot_name: "Publish to snapshot.raintank.io"
# snapshot_remove_expired: true
# snapshot_TTL_days: 90
# External image store
grafana_image_storage: {}
# provider: gcs
# key_file:
# bucket:
# path:
#######
# Plugins from https://grafana.com/plugins
grafana_plugins: []
# - raintank-worldping-app
#
# Alert notification channels to configure
grafana_alert_notifications: []
# - name: "Email Alert"
# type: "email"
# isDefault: true
# settings:
# addresses: "example@example.com"
# Datasources to configure
grafana_datasources:
- name: "Prometheus"
type: "prometheus"
access: "proxy"
url: "http://localhost:9090"
basicAuth: false
basicAuthUser: ""
basicAuthPassword: ""
isDefault: true
editable: true
jsonData:
tlsAuth: false
tlsAuthWithCACert: false
tlsSkipVerify: true
# API keys to configure
grafana_api_keys: []
# - name: "admin"
# role: "Admin"
# - name: "viewer"
# role: "Viewer"
# - name: "editor"
# role: "Editor"
# Logging options to configure
grafana_logging:
log_rotate: true
daily_rotate: true
max_days: 7
The content of the haproxy-exporter.yml file is listed for reference only
---
kind: configuration/haproxy-exporter
title: "HAProxy exporter"
name: default
specification:
description: "Service that runs HAProxy Exporter"
web_listen_port: "9101"
config_for_prometheus: # configuration that will be written to Prometheus to allow scraping metrics from this exporter
exporter_listen_port: "9101"
prometheus_config_dir: /etc/prometheus
file_sd_labels:
- label: "job"
value: "haproxy-exporter"
The content of the haproxy.yml file is listed for reference only
---
kind: configuration/haproxy
title: "HAProxy"
name: default
specification:
logs_max_days: 60
self_signed_certificate_name: self-signed-fullchain.pem
self_signed_private_key_name: self-signed-privkey.pem
self_signed_concatenated_cert_name: self-signed-test.tld.pem
haproxy_log_path: "/var/log/haproxy.log"
stats:
enable: true
bind_address: 127.0.0.1:9000
uri: "/haproxy?stats"
user: operations
password: your-haproxy-stats-pwd
frontend:
- name: https_front
port: 443
https: true
backend:
- http_back1
backend: # example backend config below
- name: http_back1
server_groups:
- kubernetes_node
# servers: # Definition for server to that hosts the application.
# - name: "node1"
# address: "lambdastack-vm1.domain.com"
port: 30104
The content of the helm-charts.yml file is listed for reference only
---
kind: configuration/helm-charts
title: "Helm charts"
name: default
specification:
apache_lsrepo_path: "/var/www/html/lsrepo"
The content of the helm.yml file is listed for reference only
---
kind: configuration/helm
title: "Helm"
name: default
specification:
apache_lsrepo_path: "/var/www/html/lsrepo"
The content of the ignite.yml file is listed for reference only
---
kind: configuration/ignite
title: "Apache Ignite stateful installation"
name: default
specification:
enabled_plugins:
- ignite-rest-http
config: |
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="grid.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!-- Set the page size to 4 KB -->
<property name="pageSize" value="#{4 * 1024}"/>
<!--
Sets a path to the root directory where data and indexes are
to be persisted. It's assumed the directory is on a separated SSD.
-->
<property name="storagePath" value="/var/lib/ignite/persistence"/>
<!--
Sets a path to the directory where WAL is stored.
It's assumed the directory is on a separated HDD.
-->
<property name="walPath" value="/wal"/>
<!--
Sets a path to the directory where WAL archive is stored.
The directory is on the same HDD as the WAL.
-->
<property name="walArchivePath" value="/wal/archive"/>
</bean>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
IP_LIST_PLACEHOLDER
</property>
</bean>
</property>
<property name="localPort" value="47500"/>
<!-- Limit number of potentially used ports from 100 to 10 -->
<property name="localPortRange" value="10"/>
</bean>
</property>
<property name="communicationSpi">
<bean class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi">
<property name="localPort" value="47100"/>
<!-- Limit number of potentially used ports from 100 to 10 -->
<property name="localPortRange" value="10"/>
</bean>
</property>
<property name="clientConnectorConfiguration">
<bean class="org.apache.ignite.configuration.ClientConnectorConfiguration">
<property name="port" value="10800"/>
<!-- Limit number of potentially used ports from 100 to 10 -->
<property name="portRange" value="10"/>
</bean>
</property>
<property name="connectorConfiguration">
<bean class="org.apache.ignite.configuration.ConnectorConfiguration">
<property name="port" value="11211"/>
<!-- Limit number of potentially used ports from 100 to 10 -->
<property name="portRange" value="10"/>
</bean>
</property>
</bean>
</beans>
The content of the image-registry.yml file is listed for reference only
---
kind: configuration/image-registry
title: "LambdaStack image registry"
name: default
specification:
description: "Local registry with Docker images"
registry_image:
name: "registry:2"
file_name: registry-2.tar
images_to_load:
x86_64:
generic:
- name: "lambdastack/keycloak:14.0.0"
file_name: keycloak-14.0.0.tar
- name: "rabbitmq:3.8.9"
file_name: rabbitmq-3.8.9.tar
- name: "lambdastack/ignite:2.9.1"
file_name: ignite-2.9.1.tar
- name: "kubernetesui/dashboard:v2.3.1"
file_name: dashboard-v2.3.1.tar
- name: "kubernetesui/metrics-scraper:v1.0.7"
file_name: metrics-scraper-v1.0.7.tar
- name: "vault:1.7.0"
file_name: vault-1.7.0.tar
- name: "hashicorp/vault-k8s:0.10.0"
file_name: vault-k8s-0.10.0.tar
- name: "istio/proxyv2:1.8.1"
file_name: proxyv2-1.8.1.tar
- name: "istio/pilot:1.8.1"
file_name: pilot-1.8.1.tar
- name: "istio/operator:1.8.1"
file_name: operator-1.8.1.tar
# postgres
- name: bitnami/pgpool:4.2.4
file_name: pgpool-4.2.4.tar
- name: bitnami/pgbouncer:1.16.0
file_name: pgbouncer-1.16.0.tar
current:
- name: "haproxy:2.2.2-alpine"
file_name: haproxy-2.2.2-alpine.tar
# K8s v1.20.12 - LambdaStack 1.3 (transitional version)
# https://github.com/kubernetes/kubernetes/blob/v1.20.12/build/dependencies.yaml
- name: "k8s.gcr.io/kube-apiserver:v1.20.12"
file_name: kube-apiserver-v1.20.12.tar
- name: "k8s.gcr.io/kube-controller-manager:v1.20.12"
file_name: kube-controller-manager-v1.20.12.tar
- name: "k8s.gcr.io/kube-proxy:v1.20.12"
file_name: kube-proxy-v1.20.12.tar
- name: "k8s.gcr.io/kube-scheduler:v1.20.12"
file_name: kube-scheduler-v1.20.12.tar
- name: "k8s.gcr.io/coredns:1.7.0"
file_name: coredns-1.7.0.tar
- name: "k8s.gcr.io/etcd:3.4.13-0"
file_name: etcd-3.4.13-0.tar
- name: "k8s.gcr.io/pause:3.2"
file_name: pause-3.2.tar
# flannel
- name: "quay.io/coreos/flannel:v0.14.0-amd64"
file_name: flannel-v0.14.0-amd64.tar
- name: "quay.io/coreos/flannel:v0.14.0"
file_name: flannel-v0.14.0.tar
# canal & calico
- name: "calico/cni:v3.20.2"
file_name: cni-v3.20.2.tar
- name: "calico/kube-controllers:v3.20.2"
file_name: kube-controllers-v3.20.2.tar
- name: "calico/node:v3.20.2"
file_name: node-v3.20.2.tar
- name: "calico/pod2daemon-flexvol:v3.20.2"
file_name: pod2daemon-flexvol-v3.20.2.tar
legacy:
# K8s v1.18.6 - LambdaStack 0.7.1 - 1.2
- name: "k8s.gcr.io/kube-apiserver:v1.18.6"
file_name: kube-apiserver-v1.18.6.tar
- name: "k8s.gcr.io/kube-controller-manager:v1.18.6"
file_name: kube-controller-manager-v1.18.6.tar
- name: "k8s.gcr.io/kube-proxy:v1.18.6"
file_name: kube-proxy-v1.18.6.tar
- name: "k8s.gcr.io/kube-scheduler:v1.18.6"
file_name: kube-scheduler-v1.18.6.tar
- name: "k8s.gcr.io/coredns:1.6.7"
file_name: coredns-1.6.7.tar
- name: "k8s.gcr.io/etcd:3.4.3-0"
file_name: etcd-3.4.3-0.tar
# flannel
- name: "quay.io/coreos/flannel:v0.12.0-amd64"
file_name: flannel-v0.12.0-amd64.tar
- name: "quay.io/coreos/flannel:v0.12.0"
file_name: flannel-v0.12.0.tar
# canal & calico
- name: "calico/cni:v3.15.0"
file_name: cni-v3.15.0.tar
- name: "calico/kube-controllers:v3.15.0"
file_name: kube-controllers-v3.15.0.tar
- name: "calico/node:v3.15.0"
file_name: node-v3.15.0.tar
- name: "calico/pod2daemon-flexvol:v3.15.0"
file_name: pod2daemon-flexvol-v3.15.0.tar
aarch64:
generic:
- name: "lambdastack/keycloak:14.0.0"
file_name: keycloak-14.0.0.tar
- name: "rabbitmq:3.8.9"
file_name: rabbitmq-3.8.9.tar
- name: "lambdastack/ignite:2.9.1"
file_name: ignite-2.9.1.tar
- name: "kubernetesui/dashboard:v2.3.1"
file_name: dashboard-v2.3.1.tar
- name: "kubernetesui/metrics-scraper:v1.0.7"
file_name: metrics-scraper-v1.0.7.tar
- name: "vault:1.7.0"
file_name: vault-1.7.0.tar
- name: "hashicorp/vault-k8s:0.10.0"
file_name: vault-k8s-0.10.0.tar
current:
- name: "haproxy:2.2.2-alpine"
file_name: haproxy-2.2.2-alpine.tar
# K8s v1.20.12 - LambdaStack 1.3 (transition version)
- name: "k8s.gcr.io/kube-apiserver:v1.20.12"
file_name: kube-apiserver-v1.20.12.tar
- name: "k8s.gcr.io/kube-controller-manager:v1.20.12"
file_name: kube-controller-manager-v1.20.12.tar
- name: "k8s.gcr.io/kube-proxy:v1.20.12"
file_name: kube-proxy-v1.20.12.tar
- name: "k8s.gcr.io/kube-scheduler:v1.20.12"
file_name: kube-scheduler-v1.20.12.tar
- name: "k8s.gcr.io/coredns:1.7.0"
file_name: coredns-1.7.0.tar
- name: "k8s.gcr.io/etcd:3.4.13-0"
file_name: etcd-3.4.13-0.tar
- name: "k8s.gcr.io/pause:3.2"
file_name: pause-3.2.tar
# flannel
- name: "quay.io/coreos/flannel:v0.14.0-arm64"
file_name: flannel-v0.14.0-arm64.tar
- name: "quay.io/coreos/flannel:v0.14.0"
file_name: flannel-v0.14.0.tar
# canal & calico
- name: "calico/cni:v3.20.2"
file_name: cni-v3.20.2.tar
- name: "calico/kube-controllers:v3.20.2"
file_name: kube-controllers-v3.20.2.tar
- name: "calico/node:v3.20.2"
file_name: node-v3.20.2.tar
- name: "calico/pod2daemon-flexvol:v3.20.2"
file_name: pod2daemon-flexvol-v3.20.2.tar
legacy:
# K8s v1.18.6 - LambdaStack 0.7.1 - 1.2
- name: "k8s.gcr.io/kube-apiserver:v1.18.6"
file_name: kube-apiserver-v1.18.6.tar
- name: "k8s.gcr.io/kube-controller-manager:v1.18.6"
file_name: kube-controller-manager-v1.18.6.tar
- name: "k8s.gcr.io/kube-proxy:v1.18.6"
file_name: kube-proxy-v1.18.6.tar
- name: "k8s.gcr.io/kube-scheduler:v1.18.6"
file_name: kube-scheduler-v1.18.6.tar
- name: "k8s.gcr.io/coredns:1.6.7"
file_name: coredns-1.6.7.tar
- name: "k8s.gcr.io/etcd:3.4.3-0"
file_name: etcd-3.4.3-0.tar
# flannel
- name: "quay.io/coreos/flannel:v0.12.0-arm64"
file_name: flannel-v0.12.0-arm64.tar
- name: "quay.io/coreos/flannel:v0.12.0"
file_name: flannel-v0.12.0.tar
# canal & calico
- name: "calico/cni:v3.15.0"
file_name: cni-v3.15.0.tar
- name: "calico/kube-controllers:v3.15.0"
file_name: kube-controllers-v3.15.0.tar
- name: "calico/node:v3.15.0"
file_name: node-v3.15.0.tar
- name: "calico/pod2daemon-flexvol:v3.15.0"
file_name: pod2daemon-flexvol-v3.15.0.tar
The content of the jmx-exporter.yml file is listed for reference only
---
kind: configuration/jmx-exporter
title: "JMX exporter"
name: default
specification:
file_name: "jmx_prometheus_javaagent-0.14.0.jar"
jmx_path: /opt/jmx-exporter/jmx_prometheus_javaagent.jar # Changing it requires also change for same variable in Kafka and Zookeeper configs. # Todo Zookeeper and Kafka to use this variable
jmx_jars_directory: /opt/jmx-exporter/jars
jmx_exporter_user: jmx-exporter
jmx_exporter_group: jmx-exporter
The content of the kafka-exporter.yml file is listed for reference only
kind: configuration/kafka-exporter
title: "Kafka exporter"
name: default
specification:
description: "Service that runs Kafka Exporter"
web_listen_port: "9308"
config_flags:
- "--web.listen-address=:9308" # Address to listen on for web interface and telemetry.
- '--web.telemetry-path=/metrics' # Path under which to expose metrics.
- '--log.level=info'
- '--topic.filter=.*' # Regex that determines which topics to collect.
- '--group.filter=.*' # Regex that determines which consumer groups to collect.
#- '--tls.insecure-skip-tls-verify' # If true, the server's certificate will not be checked for validity. This will make your HTTPS connections insecure.
- '--kafka.version=2.0.0'
#- '--sasl.enabled' # Connect using SASL/PLAIN.
#- '--sasl.handshake' # Only set this to false if using a non-Kafka SASL proxy
#- '--sasl.username=""'
#- '--sasl.password=""'
#- '--tls.enabled' # Connect using TLS
#- '--tls.ca-file=""' # The optional certificate authority file for TLS client authentication
#- '--tls.cert-file=""' # The optional certificate file for client authentication
#- '--tls.key-file=""' # The optional key file for client authentication
config_for_prometheus: # configuration that will be written to Prometheus to allow scraping metrics from this exporter
exporter_listen_port: "9308"
prometheus_config_dir: /etc/prometheus
file_sd_labels:
- label: "job"
value: "kafka-exporter"
The content of the kafka.yml file is listed for reference only
---
kind: configuration/kafka
title: "Kafka"
name: default
specification:
kafka_var:
enabled: True
admin: kafka
admin_pwd: LambdaStack
# javax_net_debug: all # uncomment to activate debugging, other debug options: https://colinpaice.blog/2020/04/05/using-java-djavax-net-debug-to-examine-data-flows-including-tls/
security:
ssl:
enabled: False
port: 9093
server:
local_cert_download_path: kafka-certs
keystore_location: /var/private/ssl/kafka.server.keystore.jks
truststore_location: /var/private/ssl/kafka.server.truststore.jks
cert_validity: 365
passwords:
keystore: PasswordToChange
truststore: PasswordToChange
key: PasswordToChange
endpoint_identification_algorithm: HTTPS
client_auth: required
encrypt_at_rest: False
inter_broker_protocol: PLAINTEXT
authorization:
enabled: False
authorizer_class_name: kafka.security.auth.SimpleAclAuthorizer
allow_everyone_if_no_acl_found: False
super_users:
- tester01
- tester02
users:
- name: test_user
topic: test_topic
authentication:
enabled: False
authentication_method: certificates
sasl_mechanism_inter_broker_protocol:
sasl_enabled_mechanisms: PLAIN
sha: "b28e81705e30528f1abb6766e22dfe9dae50b1e1e93330c880928ff7a08e6b38ee71cbfc96ec14369b2dfd24293938702cab422173c8e01955a9d1746ae43f98"
port: 9092
min_insync_replicas: 1 # Minimum number of replicas (ack write)
default_replication_factor: 1 # Minimum number of automatically created topics
offsets_topic_replication_factor: 1 # Minimum number of offsets topic (consider higher value for HA)
num_recovery_threads_per_data_dir: 1 # Minimum number of recovery threads per data dir
num_replica_fetchers: 1 # Minimum number of replica fetchers
replica_fetch_max_bytes: 1048576
replica_socket_receive_buffer_bytes: 65536
partitions: 8 # 100 x brokers x replicas for reasonable size cluster. Small clusters can be less
log_retention_hours: 168 # The minimum age of a log file to be eligible for deletion due to age
log_retention_bytes: -1 # -1 is no size limit only a time limit (log_retention_hours). This limit is enforced at the partition level, multiply it by the number of partitions to compute the topic retention in bytes.
offset_retention_minutes: 10080 # Offsets older than this retention period will be discarded
heap_opts: "-Xmx2G -Xms2G"
opts: "-Djavax.net.debug=all"
jmx_opts:
max_incremental_fetch_session_cache_slots: 1000
controlled_shutdown_enable: true
group: kafka
user: kafka
conf_dir: /opt/kafka/config
data_dir: /var/lib/kafka
log_dir: /var/log/kafka
socket_settings:
network_threads: 3 # The number of threads handling network requests
io_threads: 8 # The number of threads doing disk I/O
send_buffer_bytes: 102400 # The send buffer (SO_SNDBUF) used by the socket server
receive_buffer_bytes: 102400 # The receive buffer (SO_RCVBUF) used by the socket server
request_max_bytes: 104857600 # The maximum size of a request that the socket server will accept (protection against OOM)
zookeeper_set_acl: false
zookeeper_hosts: "{{ groups['zookeeper']|join(':2181,') }}:2181"
jmx_exporter_user: jmx-exporter
jmx_exporter_group: jmx-exporter
prometheus_jmx_path: /opt/jmx-exporter/jmx_prometheus_javaagent.jar
prometheus_jmx_exporter_web_listen_port: 7071
prometheus_jmx_config: /opt/kafka/config/jmx-kafka.config.yml
prometheus_config_dir: /etc/prometheus
prometheus_kafka_jmx_file_sd_labels:
"job": "jmx-kafka"
The content of the kibana.yml file is listed for reference only
---
kind: configuration/kibana
title: "Kibana"
name: default
specification:
kibana_log_dir: /var/log/kibana
The content of the kubernetes-master.yml file is listed for reference only
---
kind: configuration/kubernetes-master
title: Kubernetes Control Plane Config
name: default
specification:
version: 1.20.12
cni_version: 0.8.7
cluster_name: "kubernetes-lambdastack"
allow_pods_on_master: False
storage:
name: lambdastack-cluster-volume # name of the Kubernetes resource
path: / # directory path in mounted storage
enable: True
capacity: 50 # GB
data: {} #AUTOMATED - data specific to cloud provider
advanced: # modify only if you are sure what value means
api_server_args: # https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/
profiling: false
enable-admission-plugins: "AlwaysPullImages,DenyEscalatingExec,NamespaceLifecycle,ServiceAccount,NodeRestriction"
audit-log-path: "/var/log/apiserver/audit.log"
audit-log-maxbackup: 10
audit-log-maxsize: 200
secure-port: 6443
controller_manager_args: # https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/
profiling: false
terminated-pod-gc-threshold: 200
scheduler_args: # https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/
profiling: false
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
plugin: flannel # valid options: calico, flannel, canal (due to lack of support for calico on Azure - use canal)
imageRepository: k8s.gcr.io
certificates:
expiration_days: 365 # values greater than 24855 are not recommended
renew: false
etcd_args:
encrypted: true
kubeconfig:
local:
api_server:
# change if you want a custom hostname (you can use jinja2/ansible expressions here, for example "{{ groups.kubernetes_master[0] }}")
hostname: 127.0.0.1
# change if you want a custom port
port: 6443
# image_registry_secrets:
# - email: emaul@domain.com
# name: secretname
# namespace: default
# password: docker-registry-pwd
# server_url: docker-registry-url
# username: docker-registry-user
The content of the kubernetes-nodes.yml file is listed for reference only
---
kind: configuration/kubernetes-node
title: Kubernetes Node Config
name: default
specification:
version: 1.20.12
cni_version: 0.8.7
node_labels: "node-type=lambdastack"
The content of the logging.yml file is listed for reference only
---
kind: configuration/logging
title: Logging Config
name: default
specification:
cluster_name: LambdaStackElastic
admin_password: PASSWORD_TO_CHANGE
kibanaserver_password: PASSWORD_TO_CHANGE
kibanaserver_user_active: true
logstash_password: PASSWORD_TO_CHANGE
logstash_user_active: true
demo_users_to_remove:
- kibanaro
- readall
- snapshotrestore
paths:
data: /var/lib/elasticsearch
repo: /var/lib/elasticsearch-snapshots
logs: /var/log/elasticsearch
jvm_options:
Xmx: 1g # see https://www.elastic.co/guide/en/elasticsearch/reference/7.9/heap-size.html
opendistro_security:
ssl:
transport:
enforce_hostname_verification: true
The content of the logstash.yml file is listed for reference only
---
kind: configuration/logstash
title: "Logstash"
name: default
specification: {}
The content of the node-exporter.yml file is listed for reference only
---
kind: configuration/node-exporter
title: "Node exporter"
name: default
specification:
disable_helm_chart: false
helm_chart_values:
service:
port: 9100
targetPort: 9100
files:
node_exporter_helm_chart_file_name: node-exporter-1.1.2.tgz
enabled_collectors:
- conntrack
- diskstats
- entropy
- filefd
- filesystem
- loadavg
- mdadm
- meminfo
- netdev
- netstat
- sockstat
- stat
- textfile
- time
- uname
- vmstat
- systemd
config_flags:
- "--web.listen-address=:9100"
- '--log.level=info'
- '--collector.diskstats.ignored-devices=^(ram|loop|fd)\d+$'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|run)($|/)'
- '--collector.netdev.device-blacklist="^$"'
- '--collector.textfile.directory="/var/lib/prometheus/node-exporter"'
- '--collector.systemd.unit-whitelist="(kafka\.service|zookeeper\.service)"'
web_listen_port: "9100"
web_listen_address: ""
config_for_prometheus: # configuration that will be written to Prometheus to allow scraping metrics from this exporter
exporter_listen_port: "9100"
prometheus_config_dir: /etc/prometheus
file_sd_labels:
- label: "job"
value: "node"
The content of the opendistro-for-elasticsearch.yml file is listed for reference only
---
kind: configuration/opendistro-for-elasticsearch
title: Open Distro for Elasticsearch Config
name: default
specification:
cluster_name: LambdaStackElastic
clustered: true
admin_password: PASSWORD_TO_CHANGE
kibanaserver_password: PASSWORD_TO_CHANGE
kibanaserver_user_active: false
logstash_password: PASSWORD_TO_CHANGE
logstash_user_active: false
demo_users_to_remove:
- kibanaro
- readall
- snapshotrestore
- logstash
- kibanaserver
paths:
data: /var/lib/elasticsearch
repo: /var/lib/elasticsearch-snapshots
logs: /var/log/elasticsearch
jvm_options:
Xmx: 1g # see https://www.elastic.co/guide/en/elasticsearch/reference/7.9/heap-size.html
opendistro_security:
ssl:
transport:
enforce_hostname_verification: true
The content of the postgres-exporter.yml file is listed for reference only
---
kind: configuration/postgres-exporter
title: Postgres exporter
name: default
specification:
config_flags:
- --log.level=info
- --extend.query-path=/opt/postgres_exporter/queries.yaml
- --auto-discover-databases
# Please see optional flags: https://github.com/prometheus-community/postgres_exporter/tree/v0.9.0#flags
config_for_prometheus:
exporter_listen_port: '9187'
prometheus_config_dir: /etc/prometheus
file_sd_labels:
- label: "job"
value: "postgres-exporter"
The content of the postgresql.yml file is listed for reference only
---
kind: configuration/postgresql
title: PostgreSQL
name: default
specification:
config_file:
parameter_groups:
- name: CONNECTIONS AND AUTHENTICATION
subgroups:
- name: Connection Settings
parameters:
- name: listen_addresses
value: "'*'"
comment: listen on all addresses
- name: Security and Authentication
parameters:
- name: ssl
value: 'off'
comment: to have the default value also on Ubuntu
- name: RESOURCE USAGE (except WAL)
subgroups:
- name: Kernel Resource Usage
parameters:
- name: shared_preload_libraries
value: AUTOCONFIGURED
comment: set by automation
- name: ERROR REPORTING AND LOGGING
subgroups:
- name: Where to Log
parameters:
- name: log_directory
value: "'/var/log/postgresql'"
comment: to have standard location for Filebeat and logrotate
- name: log_filename
value: "'postgresql.log'"
comment: to use logrotate with common configuration
- name: WRITE AHEAD LOG
subgroups:
- name: Settings
parameters:
- name: wal_level
value: replica
when: replication
# Changes to archive_mode require a full PostgreSQL server restart,
# while archive_command changes can be applied via a normal configuration reload.
# See https://repmgr.org/docs/repmgr.html#CONFIGURATION-POSTGRESQL
- name: Archiving
parameters:
- name: archive_mode
value: 'on'
when: replication
- name: archive_command
value: "'/bin/true'"
when: replication
- name: REPLICATION
subgroups:
- name: Sending Server(s)
parameters:
- name: max_wal_senders
value: 10
comment: maximum number of simultaneously running WAL sender processes
when: replication
- name: wal_keep_size
value: 500
comment: the size of WAL files held for standby servers (MB)
when: replication
- name: Standby Servers # ignored on master server
parameters:
- name: hot_standby
value: 'on'
comment: must be 'on' for repmgr needs, ignored on primary but recommended in case primary becomes standby
when: replication
extensions:
pgaudit:
enabled: false
shared_preload_libraries:
- pgaudit
config_file_parameters:
log_connections: 'off'
log_disconnections: 'off'
log_statement: 'none'
log_line_prefix: "'%m [%p] %q%u@%d,host=%h '"
# pgaudit specific, see https://github.com/pgaudit/pgaudit/tree/REL_13_STABLE#settings
pgaudit.log: "'write, function, role, ddl, misc_set'"
pgaudit.log_catalog: 'off # to reduce overhead of logging' # default is 'on'
# the following first 2 parameters are set to values that make it easier to access audit log per table
# change their values to the opposite if you need to reduce overhead of logging
pgaudit.log_relation: 'on # separate log entry for each relation' # default is 'off'
pgaudit.log_statement_once: 'off' # same as default
pgaudit.log_parameter: 'on' # default is 'off'
pgbouncer:
enabled: false
replication:
enabled: false
replication_user_name: ls_repmgr
replication_user_password: PASSWORD_TO_CHANGE
privileged_user_name: ls_repmgr_admin
privileged_user_password: PASSWORD_TO_CHANGE
repmgr_database: ls_repmgr
shared_preload_libraries:
- repmgr
logrotate:
pgbouncer:
period: weekly
rotations: 5
# Configuration partly based on /etc/logrotate.d/postgresql-common provided by 'postgresql-common' package from Ubuntu repo.
# PostgreSQL from Ubuntu repo:
# By default 'logging_collector' is disabled, so 'log_directory' parameter is ignored.
# Default log path is /var/log/postgresql/postgresql-$version-$cluster.log.
# PostgreSQL from SCL repo (RHEL):
# By default 'logging_collector' is enabled and there is up to 7 files named 'daily' (e.g. postgresql-Wed.log)
# and thus they can be overwritten by built-in log facility to provide rotation.
# To have similar configuration for both distros (with logrotate), 'log_filename' parameter is modified.
postgresql: |-
/var/log/postgresql/postgresql*.log {
maxsize 10M
daily
rotate 6
copytruncate
# delaycompress is for Filebeat
delaycompress
compress
notifempty
missingok
su root root
nomail
# to have multiple unique filenames per day when dateext option is set
dateformat -%Y%m%dH%H
}
The content of the prometheus.yml file is listed for reference only
---
kind: configuration/prometheus
title: "Prometheus"
name: default
specification:
config_directory: "/etc/prometheus"
storage:
data_directory: "/var/lib/prometheus"
config_flags: # Parameters that Prometheus service will be started with.
- "--config.file=/etc/prometheus/prometheus.yml" # Directory should be the same as "config_directory"
- "--storage.tsdb.path=/var/lib/prometheus" # Directory should be the same as "storage.data_directory"
- "--storage.tsdb.retention.time=180d" # Data retention time for metrics
- "--storage.tsdb.retention.size=20GB" # Data retention size for metrics
- "--web.console.libraries=/etc/prometheus/console_libraries" # Directory should be the same as "config_directory"
- "--web.console.templates=/etc/prometheus/consoles" # Directory should be the same as "config_directory"
- "--web.listen-address=0.0.0.0:9090" # Address that Prometheus console will be available
- "--web.enable-admin-api" # Enables administrative HTTP API
metrics_path: "/metrics"
scrape_interval : "15s"
scrape_timeout: "10s"
evaluation_interval: "10s"
remote_write: []
remote_read: []
alertmanager:
enable: false # To make Alertmanager working, you have to enable it and define receivers and routes
alert_rules:
common: true
container: false
kafka: false
node: false
postgresql: false
prometheus: false
# config: # Configuration for Alertmanager, it will be passed to Alertmanager service.
# # Full list of configuration fields https://prometheus.io/docs/alerting/configuration/
# global:
# resolve_timeout: 5m
# smtp_from: "alert@test.com"
# smtp_smarthost: "smtp-url:smtp-port"
# smtp_auth_username: "your-smtp-user@domain.com"
# smtp_auth_password: "your-smtp-password"
# smtp_require_tls: True
# route:
# group_by: ['alertname']
# group_wait: 10s
# group_interval: 10s
# repeat_interval: 1h
# receiver: 'email' # Default receiver, change if another is set to default
# routes: # Example routes, names need to match 'name' field of receiver
# - match_re:
# severity: critical
# receiver: opsgenie
# continue: true
# - match_re:
# severity: critical
# receiver: pagerduty
# continue: true
# - match_re:
# severity: info|warning|critical
# receiver: slack
# continue: true
# - match_re:
# severity: warning|critical
# receiver: email
# receivers: # example configuration for receivers # api_url: https://prometheus.io/docs/alerting/configuration/#receiver
# - name: 'email'
# email_configs:
# - to: "test@domain.com"
# - name: 'slack'
# slack_configs:
# - api_url: "your-slack-integration-url"
# - name: 'pagerduty'
# pagerduty_configs:
# - service_key: "your-pagerduty-service-key"
# - name: 'opsgenie'
# opsgenie_config:
# api_key: <secret> | default = global.opsgenie_api_key
# api_url: <string> | default = global.opsgenie_api_url
The content of the rabbitmq.yml file is listed for reference only
---
kind: configuration/rabbitmq
title: "RabbitMQ"
name: default
specification:
rabbitmq_user: rabbitmq
rabbitmq_group: rabbitmq
stop_service: false
logrotate_period: weekly
logrotate_number: 10
ulimit_open_files: 65535
amqp_port: 5672
rabbitmq_use_longname: AUTOCONFIGURED # true/false/AUTOCONFIGURED
rabbitmq_policies: []
rabbitmq_plugins: []
custom_configurations: []
cluster:
is_clustered: false
The content of the recovery.yml file is listed for reference only
---
kind: configuration/recovery
title: Recovery Config
name: default
specification:
components:
load_balancer:
enabled: false
snapshot_name: latest
logging:
enabled: false
snapshot_name: latest
monitoring:
enabled: false
snapshot_name: latest
postgresql:
enabled: false
snapshot_name: latest
rabbitmq:
enabled: false
snapshot_name: latest
The content of the repository.yml file is listed for reference only
---
kind: configuration/repository
title: "LambdaStack requirements repository"
name: default
specification:
description: "Local repository of binaries required to install LambdaStack"
download_done_flag_expire_minutes: 120
apache_lsrepo_path: "/var/www/html/lsrepo"
teardown:
disable_http_server: true # whether to stop and disable Apache HTTP Server service
remove:
files: false
helm_charts: false
images: false
packages: false
The content of the shared-config.yml file is listed for reference only
---
kind: configuration/shared-config
title: "Shared configuration that will be visible to all roles"
name: default
specification:
custom_repository_url: '' # leave it empty to use local repository or provide url to your repo
custom_image_registry_address: '' # leave it empty to use local registry or provide address of your registry (hostname:port). This registry will be used to populate K8s control plane and should contain all required images.
download_directory: /tmp # directory where files and images will be stored just before installing/loading
vault_location: '' # if empty "BUILD DIRECTORY/vault" will be used
vault_tmp_file_location: SET_BY_AUTOMATION
use_ha_control_plane: False
promote_to_ha: False
The content of the vault.yml file is listed for reference only
---
kind: configuration/vault
title: Vault Config
name: default
specification:
vault_enabled: false
vault_system_user: vault
vault_system_group: vault
enable_vault_audit_logs: false
enable_vault_ui: false
vault_script_autounseal: true
vault_script_autoconfiguration: true
tls_disable: false
kubernetes_integration: true
kubernetes_configuration: true
kubernetes_namespace: default
enable_vault_kubernetes_authentication: true
app_secret_path: devwebapp
revoke_root_token: false
secret_mount_path: secret
vault_token_cleanup: true
vault_install_dir: /opt/vault
vault_log_level: info
override_existing_vault_users: false
certificate_name: fullchain.pem
private_key_name: privkey.pem
selfsigned_certificate:
country: US
state: state
city: city
company: company
common_name: "*"
vault_tls_valid_days: 365
vault_users:
- name: admin
policy: admin
- name: provisioner
policy: provisioner
files:
vault_helm_chart_file_name: v0.11.0.tar.gz
vault_helm_chart_values:
injector:
image:
repository: "{{ image_registry_address }}/hashicorp/vault-k8s"
agentImage:
repository: "{{ image_registry_address }}/vault"
server:
image:
repository: "{{ image_registry_address }}/vault"
The content of the zookeeper.yml file is listed for reference only
---
kind: configuration/zookeeper
title: "Zookeeper"
name: default
specification:
static_config_file:
# This block is injected to $ZOOCFGDIR/zoo.cfg
configurable_block: |
# Limits the number of concurrent connections (at the socket level) that a single client, identified by IP address,
# may make to a single member of the ZooKeeper ensemble. This is used to prevent certain classes of DoS attacks,
# including file descriptor exhaustion. The default is 60. Setting this to 0 removes the limit.
maxClientCnxns=0
# --- AdminServer configuration ---
# By default the AdminServer is enabled. Disabling it will cause automated test failures.
admin.enableServer=true
# The address the embedded Jetty server listens on. Defaults to 0.0.0.0.
admin.serverAddress=127.0.0.1
# The port the embedded Jetty server listens on. Defaults to 8080.
admin.serverPort=8008
WIP - Comming Soon!
LambdaStack provides solution to create full or partial backup and restore for some components, like:
Backup is created directly on the machine where component is running, and it is moved to the repository host via
rsync. On the repository host backup files are stored in location /lsbackup/mounted mounted on a local
filesystem. See How to store backup chapter.
Copy default configuration for backup from defaults/configuration/backup.yml into newly created backup.yml config file, and enable backup for chosen components by setting up enabled parameter to true.
This config may also be attached to cluster-config.yml or whatever you named your cluster yaml file.
kind: configuration/backup
title: Backup Config
name: default
specification:
components:
load_balancer:
enabled: true
logging:
enabled: false
monitoring:
enabled: true
postgresql:
enabled: true
rabbitmq:
enabled: false
# Kubernes recovery is not supported at this point.
# You may create backup by enabling this below, but recovery should be done manually according to Kubernetes documentation.
kubernetes:
enabled: false
Run lambdastack backup command:
lambdastack backup -f backup.yml -b build_folder
If backup config is attached to cluster-config.yml, use this file instead of backup.yml.
Backup location is defined in backup role as backup_destination_host and backup_destination_dir. Default
backup location is defined on repository host in location /lsbackup/mounted/. Use mounted location as mount
point and mount storage you want to use. This might be:
Ensure that mounted location has enough space, is reliable and is well protected against disaster.
NOTE
If you don't attach any storage into the mount point location, be aware that backups will be stored on the local machine. This is not recommended.
Copy existing default configuration from defaults/configuration/recovery.yml into newly created recovery.yml config file, and set enabled parameter for component to recovery. It's possible to choose snapshot name by passing date and time part of snapshot name. If snapshot name is not provided, the latest one will be restored.
This config may also be attached to cluster-config.yml
kind: configuration/recovery
title: Recovery Config
name: default
specification:
components:
load_balancer:
enabled: true
snapshot_name: latest #restore latest backup
logging:
enabled: true
snapshot_name: 20200604-150829 #restore selected backup
monitoring:
enabled: false
snapshot_name: latest
postgresql:
enabled: false
snapshot_name: latest
rabbitmq:
enabled: false
snapshot_name: latest
Run lambdastack recovery command:
lambdastack recovery -f recovery.yml -b build_folder
If recovery config is attached to cluster-config.yml, use this file instead of recovery.yml.
Load balancer backup includes:
/etc/haproxy//etc/ssl/haproxy/Recovery includes all backed up files
Logging backup includes:
/etc/elasticsearch//etc/kibana/Only single-node Elasticsearch backup is supported. Solution for multi-node Elasticsearch cluster will be added in future release.
Monitoring backup includes:
/etc/prometheus/Recovery includes all backed up configurations and snapshots.
Postgresql backup includes:
pg_dumpall*.confWhen multiple node configuration is used, and failover action has changed database cluster status (one node down,
switchover) it's still possible to create backup. But before database restore, cluster needs to be recovered by
running lambdastack apply and next lambdastack recovery to restore database data. By default, we don't support recovery
database configuration from backup since this needs to be done using lambdastack apply or manually by copying backed up
files accordingly to cluster state. The reason of this is that is very risky to restore configuration files among
different database cluster configurations.
RabbitMQ backup includes:
/etc/rabbitmq/Backup does not include RabbitMQ messages.
Recovery includes all backed up files and configurations.
LambdaStack backup provides:
/etc/kubernetes/pkiFollowing features are not supported yet (use related documentation to do that manually):
Enable for Ubuntu (default):
Enable "repository" component:
repository:
count: 1
Enable for RHEL on Azure:
Enable "repository" component:
repository:
count: 1
machine: repository-machine-rhel
Add repository VM definition to main config file:
kind: infrastructure/virtual-machine
name: repository-machine-rhel
provider: azure
based_on: repository-machine
specification:
storage_image_reference:
publisher: RedHat
offer: RHEL
sku: 7-LVM
version: "7.9.2021051701"
Enable for RHEL on AWS:
Enable "repository" component:
repository:
count: 1
machine: repository-machine-rhel
Add repository VM definition to main config file:
kind: infrastructure/virtual-machine
title: Virtual Machine Infra
name: repository-machine-rhel
provider: aws
based_on: repository-machine
specification:
os_full_name: RHEL-7.9_HVM-20210208-x86_64-0-Hourly2-GP2
Enable for CentOS on Azure:
Enable "repository" component:
repository:
count: 1
machine: repository-machine-centos
Add repository VM definition to main config file:
kind: infrastructure/virtual-machine
name: repository-machine-centos
provider: azure
based_on: repository-machine
specification:
storage_image_reference:
publisher: OpenLogic
offer: CentOS
sku: "7_9"
version: "7.9.2021071900"
Enable for CentOS on AWS:
Enable "repository" component:
repository:
count: 1
machine: repository-machine-centos
Add repository VM definition to main config file:
kind: infrastructure/virtual-machine
title: Virtual Machine Infra
name: repository-machine-centos
provider: aws
based_on: repository-machine
specification:
os_full_name: "CentOS 7.9.2009 x86_64"
Disable:
Disable "repository" component:
repository:
count: 0
Prepend "kubernetes_master" mapping (or any other mapping if you don't deploy Kubernetes) with:
kubernetes_master:
- repository
- image-registry
Please read first prerequisites related to hostname requirements.
LambdaStack has the ability to set up a cluster on infrastructure provided by you. These can be either bare metal machines or VMs and should meet the following requirements:
Note. Hardware requirements are not listed since this depends on use-case, component configuration etc.
repository role) has Internet access in order to download dependencies.
If there is no Internet access, you can use air gap feature (offline mode).admin_user) has passwordless root privileges through sudo.To set up the cluster do the following steps from the provisioning machine:
First generate a minimal data yaml file:
lambdastack init -p any -n newcluster
The any provider will tell LambdaStack to create a minimal data config which does not contain any cloud provider related information. If you want full control you can add the --full flag which will give you a configuration with all parts of a cluster that can be configured.
Open the configuration file and set up the admin_user data:
admin_user:
key_path: id_rsa
name: user_name
path: # Dynamically built
Here you should specify the path to the SSH keys and the admin user name which will be used by Ansible to provision the cluster machines.
Define the components you want to install and link them to the machines you want to install them on:
Under the components tag you will find a bunch of definitions like this one:
kubernetes_master:
count: 1
machines:
- default-k8s-master
The count specifies how many machines you want to provision with this component. The machines tag is the array of machine names you want to install this component on. Note that the count and the number of machines defined must match. If you don't want to use a component you can set the count to 0 and remove the machines tag. Finally, a machine can be used by multiple component since multiple components can be installed on one machine of desired.
You will also find a bunch of infrastructure/machine definitions like below:
kind: infrastructure/machine
name: default-k8s-master
provider: any
specification:
hostname: master
ip: 192.168.100.101
Each machine name used when setting up the component layout earlier must have such a configuration where the name tag matches with the defined one in the components. The hostname and ip fields must be filled to match the actual cluster machines you provide. Ansible will use this to match the machine to a component which in turn will determine which roles to install on the machine.
Finally, start the deployment with:
lambdastack apply -f newcluster.yml --no-infra
This will create the inventory for Ansible based on the component/machine definitions made inside the newcluster.yml and let Ansible deploy it. Note that the --no-infra is important since it tells LambdaStack to skip the Terraform part.
Please read first prerequisites related to hostname requirements.
LambdaStack has the ability to set up a cluster on air-gapped infrastructure provided by you. These can be either bare metal machines or VMs and should meet the following requirements:
Note. Hardware requirements are not listed since this depends on use-case, component configuration etc.
admin_user) has passwordless root privileges through sudo.To set up the cluster do the following steps:
First we need to get the tooling to prepare the requirements. On the provisioning machine run:
lambdastack prepare --os OS
Where OS should be centos-7, redhat-7, ubuntu-18.04. This will create a directory called prepare_scripts with the needed files inside.
The scripts in the prepare_scripts will be used to download all requirements. To do that copy the prepare_scripts folder over to the requirements machine and run the following command:
download-requirements.sh /requirementsoutput/
This will start downloading all requirements and put them in the /requirementsoutput/ folder. Once run successfully the /requirementsoutput/ needs to be copied to the provisioning machine to be used later on.
Then generate a minimal data yaml file on the provisioning machine:
lambdastack init -p any -n newcluster
The any provider will tell LambdaStack to create a minimal data config which does not contain any cloud provider related information. If you want full control you can add the --full flag which will give you a configuration with all parts of a cluster that can be configured.
Open the configuration file and set up the admin_user data:
admin_user:
key_path: id_rsa
name: user_name
path: # Dynamically built
Here you should specify the path to the SSH keys and the admin user name which will be used by Ansible to provision the cluster machines.
Define the components you want to install and link them to the machines you want to install them on:
Under the components tag you will find a bunch of definitions like this one:
kubernetes_master:
count: 1
machines:
- default-k8s-master
The count specifies how many machines you want to provision with this component. The machines tag is the array of machine names you want to install this component on. Note that the count and the number of machines defined must match. If you don't want to use a component you can set the count to 0 and remove the machines tag. Finally, a machine can be used by multiple component since multiple components can be installed on one machine of desired.
You will also find a bunch of infrastructure/machine definitions like below:
kind: infrastructure/machine
name: default-k8s-master
provider: any
specification:
hostname: master
ip: 192.168.100.101
Each machine name used when setting up the component layout earlier must have such a configuration where the name tag matches with the defined one in the components. The hostname and ip fields must be filled to match the actual cluster machines you provide. Ansible will use this to match the machine to a component which in turn will determine which roles to install on the machine.
Finally, start the deployment with:
lambdastack apply -f newcluster.yml --no-infra --offline-requirements /requirementsoutput/
This will create the inventory for Ansible based on the component/machine definitions made inside the newcluster.yml and let Ansible deploy it. Note that the --no-infra is important since it tells LambdaStack to skip the Terraform part. The --offline-requirements tells LambdaStack it is an air-gapped installation and to use the /requirementsoutput/ requirements folder prepared in steps 1 and 2 as source for all requirements.
LambdaStack has the ability to use external repository and image registry during lambdastack apply execution.
Custom urls need to be specified inside the configuration/shared-config document, for example:
kind: configuration/shared-config
title: Shared configuration that will be visible to all roles
name: default
specification:
custom_image_registry_address: "10.50.2.1:5000"
custom_repository_url: "http://10.50.2.1:8080/lsrepo"
use_ha_control_plane: true
The repository and image registry implementation must be compatible with already existing Ansible code:
Note. If both custom repository/registry and offline installation are configured then the custom repository/registry is preferred.
Note. You can switch between custom repository/registry and offline/online installation methods. Keep in mind this will cause "imageRegistry" change in Kubernetes which in turn may cause short downtime.
By default, LambdaStack creates "repository" virtual machine for cloud environments. When custom repository and registry are used there is no need for additional empty VM. The following config snippet can illustrate how to mitigate this problem:
kind: lambdastack-cluster
title: LambdaStack Cluster Config
provider: <provider>
name: default
specification:
...
components:
repository:
count: 0
kubernetes_master:
count: 1
kubernetes_node:
count: 2
---
kind: configuration/feature-mapping
title: "Feature mapping to roles"
provider: <provider>
name: default
specification:
roles_mapping:
kubernetes_master:
- repository
- image-registry
- kubernetes-master
- helm
- applications
- node-exporter
- filebeat
- firewall
- vault
---
kind: configuration/shared-config
title: Shared configuration that will be visible to all roles
provider: <provider>
name: default
specification:
custom_image_registry_address: "<ip-address>:5000"
custom_repository_url: "http://<ip-address>:8080/lsrepo"
Disable "repository" component:
repository:
count: 0
Prepend "kubernetes_master" mapping (or any other mapping if you don't deploy Kubernetes) with:
kubernetes_master:
- repository
- image-registry
Specify custom repository/registry in configuration/shared-config:
specification:
custom_image_registry_address: "<ip-address>:5000"
custom_repository_url: "http://<ip-address>:8080/lsrepo"
Please read first prerequisites related to hostname requirements.
LambdaStack has the ability to set up a cluster on one of the following cloud providers:
Under the hood it uses Terraform to create the virtual infrastructure before it applies our Ansible playbooks to provision the VMs.
You need the following prerequisites:
aws, azure or gcp.Note. To run LambdaStack check the Prerequisites
To set up the cluster do the following steps from the provisioning machine:
First generate a minimal data yaml file:
lambdastack init -p aws/azure -n newcluster
The provider flag should be either aws or azure and will tell LambdaStack to create a data config which contains the specifics for that cloud provider. If you want full control you can add the --full flag which will give you a config with all parts of a cluster that can be configured.
Open the configuration file and set up the admin_user data:
admin_user:
key_path: id_rsa
name: user_name
path: # Dynamically built
Here you should specify the path to the SSH keys and the admin user name which will be used by Ansible to provision the cluster machines.
For AWS the admin name is already specified and is dependent on the Linux distro image you are using for the VM's:
ubuntuec2-userOn Azure the name you specify will be configured as the admin name on the VM's.
On GCP-WIP the name you specify will be configured as the admin name on the VM's.
Set up the cloud specific data:
To let Terraform access the cloud providers you need to set up some additional cloud configuration.
AWS:
cloud:
region: us-east-1
credentials:
key: aws_key
secret: aws_secret
use_public_ips: false
default_os_image: default
The region lets you chose the most optimal place to deploy your cluster. The key and secret are needed by Terraform and can be generated in the AWS console. More information about that here
Azure:
cloud:
region: East US
subscription_name: Subscribtion_name
use_service_principal: false
use_public_ips: false
default_os_image: default
The region lets you chose the most optimal place to deploy your cluster. The subscription_name is the Azure subscription under which you want to deploy the cluster.
Terraform will ask you to sign in to your Microsoft Azure subscription when it prepares to build/modify/destroy the infrastructure on azure. In case you need to share cluster management with other people you can set the use_service_principal tag to true. This will create a service principle and uses it to manage the resources.
If you already have a service principle and don't want to create a new one you can do the following. Make sure the use_service_principal tag is set to true. Then before you run lambdastack apply -f yourcluster.yml create the following folder structure from the path you are running LambdaStack:
/build/clustername/terraform
Where the clustername is the name you specified under specification.name in your cluster yaml. Then in terraform folder add the file named sp.yml and fill it up with the service principal information like so:
appId: "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx"
displayName: "app-name"
name: "http://app-name"
password: "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx"
tenant: "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx"
subscriptionId: "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx"
LambdaStack will read this file and automatically use it for authentication for resource creation and management.
GCP-WIP:
NOTE: GCP-WIP values may or may not be correct until official GCP release
cloud:
region: us-east-1
credentials:
key: gcp_key
secret: gcp_secret
use_public_ips: false
default_os_image: default
The region lets you chose the most optimal place to deploy your cluster. The key and secret are needed by Terraform and can be generated in the GCP console.
For both aws, azure, and gcp the following cloud attributes overlap:
use_public_ips: When true, the VMs will also have a direct interface to the internet. While this is easy for setting up a cluster for testing, it should not be used in production. A VPN setup should be used which we will document in a different section (TODO).default_os_image: Lets you more easily select LambdaStack team validated and tested OS images. When one is selected, it will be applied to every infrastructure/virtual-machine document in the cluster regardless of user defined ones.
The following values are accepted:
- default: Applies user defined infrastructure/virtual-machine documents when generating a new configuration.
- ubuntu-18.04-x86_64: Applies the latest validated and tested Ubuntu 18.04 image to all infrastructure/virtual-machine documents on x86_64 on Azure and AWS.
- redhat-7-x86_64: Applies the latest validated and tested RedHat 7.x image to all infrastructure/virtual-machine documents on x86_64 on Azure and AWS.
- centos-7-x86_64: Applies the latest validated and tested CentOS 7.x image to all infrastructure/virtual-machine documents on x86_64 on Azure and AWS.
- centos-7-arm64: Applies the latest validated and tested CentOS 7.x image to all infrastructure/virtual-machine documents on arm64 on AWS. Azure currently doesn't support arm64.
The images which will be used for these values will be updated and tested on regular basis.Define the components you want to install:
Under the components tag you will find a bunch of definitions like this one:
kubernetes_master:
count: 1
The count specifies how much VM's you want to provision with this component. If you don't want to use a component you can set the count to 0.
Note that for each cloud provider LambdaStack already has a default VM configuration for each component. If you need more control over the VM's, generate a config with the --full flag. Then each component will have an additional machine tag:
kubernetes_master:
count: 1
machine: kubernetes-master-machine
...
This links to a infrastructure/virtual-machine document which can be found inside the same configuration file. It gives you full control over the VM config (size, storage, provision image, security etc.). More details on this will be documented in a different section (TODO).
Finally, start the deployment with:
lambdastack apply -f newcluster.yml
LambdaStack currently supports RHEL 7 LVM partitioned images attached to standard RHEL repositories. For more details, refer to Azure documentation.
LambdaStack uses cloud-init custom data in order to merge small logical volumes (homelv, optlv, tmplv and varlv)
into the rootlv and extends it (with underlying filesystem) by the current free space in its volume group.
The usrlv LV, which has 10G, is not merged since it would require a reboot. The merging is required to deploy a cluster,
however, it can be disabled for troubleshooting since it performs some administrative tasks (such as remounting filesystems or restarting services).
NOTE: RHEL 7 LVM images require at least 64 GB for OS disk.
Example config:
kind: infrastructure/virtual-machine
specification:
storage_image_reference:
publisher: RedHat
offer: RHEL
sku: "7-LVM"
version: "7.9.2021051701"
storage_os_disk:
disk_size_gb: 64
LambdaStack supports CentOS 7 images with RAW partitioning (recommended) and LVM as well.
Example config:
kind: infrastructure/virtual-machine
specification:
storage_image_reference:
publisher: OpenLogic
offer: CentOS
sku: "7_9"
version: "7.9.2021071900"
In order to not merge logical volumes (for troubleshooting), use the following doc:
kind: infrastructure/cloud-init-custom-data
title: cloud-init user-data
provider: azure
name: default
specification:
enabled: false
LambdaStack has a delete command to remove a cluster from a cloud provider (AWS, Azure). With LambdaStack run the following:
lambdastack delete -b /path/to/cluster/build/folder
From the defined cluster build folder it will take the information needed to remove the resources from the cloud provider.
Please read first prerequisites related to hostname requirements.
NOTE
Single machine cannot be scaled up or deployed alongside other types of cluster.
Sometimes it might be desirable to run an LambdaStack cluster on a single machine. For this purpose LambdaStack ships with a single_cluster component configuration. This cluster comes with the following main components:
Note that components like logging and monitoring are missing since they do not provide much benefit in a single machine scenario. Also, RabbitMQ is included over Kafka since that is much less resource intensive.
To get started with a single machine cluster you can use the following template as a base. Note that some configurations are omitted:
kind: lambdastack-cluster
title: LambdaStack Cluster Config
name: default
built_path: # Dynamically built
specification:
prefix: dev
name: single
admin_user:
name: operations
key_path: id_rsa
path: # Dynamically built
cloud:
... # add other cloud configuration as needed
components:
kubernetes_master:
count: 0
kubernetes_node:
count: 0
logging:
count: 0
monitoring:
count: 0
kafka:
count: 0
postgresql:
count: 0
load_balancer:
count: 0
rabbitmq:
count: 0
ignite:
count: 0
opendistro_for_elasticsearch:
count: 0
single_machine:
count: 1
---
kind: configuration/applications
title: "Kubernetes Applications Config"
name: default
specification:
applications:
- name: auth-service
enabled: yes # set to yest to enable authentication service
... # add other authentication service configuration as needed
To create a single machine cluster using the "any" provider (with extra load_balancer config included) use the following template below:
kind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: any
name: single
build_path: # Dynamically built
specification:
name: single
admin_user:
name: ubuntu
key_path: id_rsa
path: # Dynamically built
components:
kubernetes_master:
count: 0
kubernetes_node:
count: 0
logging:
count: 0
monitoring:
count: 0
kafka:
count: 0
postgresql:
count: 0
load_balancer:
count: 1
configuration: default
machines: [single-machine]
rabbitmq:
count: 0
single_machine:
count: 1
configuration: default
machines: [single-machine]
---
kind: configuration/haproxy
title: "HAProxy"
provider: any
name: default
specification:
logs_max_days: 60
self_signed_certificate_name: self-signed-fullchain.pem
self_signed_private_key_name: self-signed-privkey.pem
self_signed_concatenated_cert_name: self-signed-test.tld.pem
haproxy_log_path: "/var/log/haproxy.log"
stats:
enable: true
bind_address: 127.0.0.1:9000
uri: "/haproxy?stats"
user: operations
password: your-haproxy-stats-pwd
frontend:
- name: https_front
port: 443
https: yes
backend:
- http_back1
backend: # example backend config below
- name: http_back1
server_groups:
- kubernetes_node
# servers: # Definition for server to that hosts the application.
# - name: "node1"
# address: "lambdastack-vm1.domain.com"
port: 30104
---
kind: infrastructure/machine
provider: any
name: single-machine
specification:
hostname: x1a1
ip: 10.20.2.10
LambdaStack gives you the ability to define custom components. This allows you to define a custom set of roles for a component you want to use in your cluster. It can be useful when you for example want to maximize usage of the available machines you have at your disposal.
The first thing you will need to do is define it in the configuration/feature-mapping configuration. To get this configuration you can run lambdastack init ... --full command. In the available_roles roles section you can see all the available roles that LambdaStack provides. The roles_mapping is where all the LambdaStack components are defined and were you need to add your custom components.
Below are parts of an example configuration/feature-mapping were we define a new single_machine_new component. We want to use Kafka instead of RabbitMQ and don`t need applications and postgres since we don't want a Keycloak deployment:
kind: configuration/feature-mapping
title: Feature mapping to roles
name: default
specification:
available_roles: # All entries here represent the available roles within LambdaStack
- name: repository
enabled: yes
- name: firewall
enabled: yes
- name: image-registry
...
roles_mapping: # All entries here represent the default components provided with LambdaStack
...
single_machine:
- repository
- image-registry
- kubernetes-master
- applications
- rabbitmq
- postgresql
- firewall
# Below is the new single_machine_new definition
single_machine_new:
- repository
- image-registry
- kubernetes-master
- kafka
- firewall
...
Once defined the new single_machine_new can be used inside the lambdastack-cluster configuration:
kind: lambdastack-cluster
title: LambdaStack Cluster Config
name: default
build_path: # Dynamically built
specification:
prefix: new
name: single
admin_user:
name: operations
key_path: id_rsa
path: # Dynamically built
cloud:
... # add other cloud configuration as needed
components:
... # other components as needed
single_machine_new:
count: x
Note: After defining a new component you might also need to define additional configurations for virtual machines and security rules depending on what you are trying to achieve.
Not all components are supported for this action. There is a bunch of issues referenced below in this document.
LambdaStack has the ability to automatically scale and cluster certain components on cloud providers (AWS, Azure). To upscale or downscale a component the count number must be increased or decreased:
components:
kubernetes_node:
count: ...
...
Then when applying the changed configuration using LambdaStack, additional VM's will be spawned and configured or removed. The following table shows what kind of operation component supports:
| Component | Scale up | Scale down | HA | Clustered | Known issues |
|---|---|---|---|---|---|
| Repository | :heavy_check_mark: | :heavy_check_mark: | :x: | :x: | --- |
| Monitoring | :heavy_check_mark: | :heavy_check_mark: | :x: | :x: | --- |
| Logging | :heavy_check_mark: | :heavy_check_mark: | :x: | :x: | --- |
| Kubernetes master | :heavy_check_mark: | :x: | :heavy_check_mark: | :heavy_check_mark: | #1579 |
| Kubernetes node | :heavy_check_mark: | :x: | :heavy_check_mark: | :heavy_check_mark: | #1580 |
| Ignite | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | --- |
| Kafka | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | --- |
| Load Balancer | :heavy_check_mark: | :heavy_check_mark: | :x: | :x: | --- |
| Opendistro for elasticsearch | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | --- |
| Postgresql | :x: | :x: | :heavy_check_mark: | :heavy_check_mark: | #1577 |
| RabbitMQ | :heavy_check_mark: | :heavy_check_mark: | :x: | :heavy_check_mark: | #1578, #1309 |
| RabbitMQ K8s | :heavy_check_mark: | :heavy_check_mark: | :x: | :heavy_check_mark: | #1486 |
| Keycloak K8s | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | --- |
| Pgpool K8s | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | --- |
| Pgbouncer K8s | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | --- |
| Ignite K8s | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | --- |
Additional notes:
Repository:
In standard LambdaStack deployment only one repository machine is required.
:arrow_up: Scaling up the repository component will create a new standalone VM.
:arrow_down: Scaling down will remove it in LIFO order (Last In, First Out).
However, even if you create more than one VM, by default all other components will use the first one.
Kubernetes master:
:arrow_up: When increased this will set up additional control plane nodes, but in the case of non-ha k8s cluster, the existing control plane node must be promoted first.
:arrow_down: At the moment there is no ability to downscale.
Kubernetes node:
:arrow_up: When increased this will set up an additional node and join into the Kubernetes cluster.
:arrow_down: There is no ability to downscale.
Load balancer:
:arrow_up: Scaling up the load_balancer component will create a new standalone VM.
:arrow_down: Scaling down will remove it in LIFO order (Last In, First Out).
Logging:
:arrow_up: Scaling up will create new VM with both Kibana and ODFE components inside.
ODFE will join the cluster but Kibana will be a standalone instance.
:arrow_down: When scaling down VM will be deleted.
Monitoring:
:arrow_up: Scaling up the monitoring component will create a new standalone VM.
:arrow_down: Scaling down will remove it in LIFO order (Last In, First Out).
Postgresql:
:arrow_up: At the moment does not support scaling up. Check known issues.
:arrow_down: At the moment does not support scaling down. Check known issues.
RabbitMQ:
If the instance count is changed, then additional RabbitMQ nodes will be added or removed.
:arrow_up: Will create new VM and adds it to the RabbitMQ cluster.
:arrow_down: At the moment scaling down will just remove VM. All data not processed on this VM will be purged. Check known issues.
Note that clustering requires a change in the configuration/rabbitmq document:
kind: configuration/rabbitmq
...
specification:
cluster:
is_clustered: true
...
RabbitMQ K8s: Scaling is controlled via replicas in StatefulSet. RabbitMQ on K8s uses plugin rabbitmq_peer_discovery_k8s to works in cluster.
Additional known issues:
LambdaStack can deploy HA Kubernetes clusters (since v0.6). To achieve that, it is required that:
the master count must be higher than 1 (proper values should be 1, 3, 5, 7):
kubernetes_master:
count: 3
the HA mode must be enabled in configuration/shared-config:
kind: configuration/shared-config
...
specification:
use_ha_control_plane: true
promote_to_ha: false
the regular lambdastack apply cycle must be executed
LambdaStack can promote / convert older single-master clusters to HA mode (since v0.6). To achieve that, it is required that:
the existing cluster is legacy single-master cluster
the existing cluster has been upgraded to Kubernetes 1.17 or above first
the HA mode and HA promotion must be enabled in configuration/shared-config:
kind: configuration/shared-config
...
specification:
use_ha_control_plane: true
promote_to_ha: true
the regular lambdastack apply cycle must be executed
since it is one-time operation, after successful promotion, the HA promotion must be disabled in the config:
kind: configuration/shared-config
...
specification:
use_ha_control_plane: true
promote_to_ha: false
Note: It is not supported yet to reverse HA promotion.
LambdaStack can scale-up existing HA clusters (including ones that were promoted). To achieve that, it is required that:
the existing cluster must be already running in HA mode
the master count must be higher than previous value (proper values should be 3, 5, 7):
kubernetes_master:
count: 5
the HA mode must be enabled in configuration/shared-config:
kind: configuration/shared-config
...
specification:
use_ha_control_plane: true
promote_to_ha: false
the regular lambdastack apply cycle must be executed
Note: It is not supported yet to scale-down clusters (master count cannot be decreased).
LambdaStack engine produce build artifacts during each deployment. Those artifacts contain:
service principal if deploying to Azure.Artifacts contain sensitive data, so it is important to keep it in safe place like private GIT repository or storage with limited access. Generated build is also important in case of scaling or updating cluster - you will it in build folder in order to edit your cluster.
LambdaStack creates (or use if you don't specified it to create) service principal account which can manage all resources in subscription, please store build artifacts securely.
When planning Kafka installation you have to think about number of partitions and replicas since it is strongly related to throughput of Kafka and its reliability. By default, Kafka's replicas number is set to 1 - you should change it in core/src/ansible/roles/kafka/defaults in order to have partitions replicated to many virtual machines.
...
replicas: 1 # Default to at least 1 (1 broker)
partitions: 8 # 100 x brokers x replicas for reasonable size cluster. Small clusters can be less
...
You can read more here about planning number of partitions.
NOTE: LambdaStack does not use Confluent. The above reference is simply for documentation.
To install RabbitMQ in single mode just add rabbitmq role to your data.yaml for your server and in general roles section. All configuration on RabbitMQ, e.g., user other than guest creation should be performed manually.
In your cluster yaml config declare as many as required objects of kind infrastructure/availability-set like
in the example below, change the name field as you wish.
---
kind: infrastructure/availability-set
name: kube-node # Short and simple name is preferred
specification:
# The "name" attribute is generated automatically according to LambdaStack's naming conventions
platform_fault_domain_count: 2
platform_update_domain_count: 5
managed: true
provider: azure
Then set it also in the corresponding components section of the kind: lambdastack-cluster doc.
components:
kafka:
count: 0
kubernetes_master:
count: 1
kubernetes_node:
# This line tells we generate the availability-set terraform template
availability_set: kube-node # Short and simple name is preferred
count: 2
The example below shows a complete configuration. Note that it's recommended to have a dedicated availability set for each clustered component.
# Test availability set config
---
kind: lambdastack-cluster
name: default
provider: azure
build_path: # Dynamically built
specification:
name: test-cluster
prefix: test
admin_user:
key_path: id_rsa
name: di-dev
path: # Dynamically built
cloud:
region: Australia East
subscription_name: <your subscription name>
use_public_ips: true
use_service_principal: true
components:
kafka:
count: 0
kubernetes_master:
count: 1
kubernetes_node:
# This line tells we generate the availability-set terraform template
availability_set: kube-node # Short and simple name is preferred
count: 2
load_balancer:
count: 1
logging:
count: 0
monitoring:
count: 0
postgresql:
# This line tells we generate the availability-set terraform template
availability_set: postgresql # Short and simple name is preferred
count: 2
rabbitmq:
count: 0
title: LambdaStack Cluster Config
---
kind: infrastructure/availability-set
name: kube-node # Short and simple name is preferred
specification:
# The "name" attribute (omitted here) is generated automatically according to LambdaStack's naming conventions
platform_fault_domain_count: 2
platform_update_domain_count: 5
managed: true
provider: azure
---
kind: infrastructure/availability-set
name: postgresql # Short and simple name is preferred
specification:
# The "name" attribute (omitted here) is generated automatically according to LambdaStack's naming conventions
platform_fault_domain_count: 2
platform_update_domain_count: 5
managed: true
provider: azure
This paragraph describes how to use a Docker container to download the requirements for air-gapped/offline installations. At this time we don't officially support this, and we still recommend using a full distribution which is the same as the air-gapped cluster machines/VMs.
A few points:
arm64 architecture requirements on a x86_64 machine. More information on the current state of arm64 support can be found here.For Ubuntu, you can use the following command to launch a container:
docker run -v /shared_folder:/home <--platform linux/amd64 or --platform linux/arm64> --rm -it ubuntu:18.04
As the ubuntu:18.04 image is multi-arch you can include --platform linux/amd64 or --platform linux/arm64 to run the container as the specified architecture. The /shared_folder should be a folder on your local machine containing the required scripts.
When you are inside the container run the following commands to prepare for the running of the download-requirements.sh script:
apt-get update # update the package manager
apt-get install sudo # install sudo so we can make the download-requirements.sh executable and run it as root
sudo chmod +x /home/download-requirements.sh # make the requirements script executable
After this you should be able to run the download-requirements.sh from the home folder.
For RedHat you can use the following command to launch a container:
docker run -v /shared_folder:/home <--platform linux/amd64 or --platform linux/arm64> --rm -it registry.access.redhat.com/ubi7/ubi:7.9
As the registry.access.redhat.com/ubi7/ubi:7.9 image is multi-arch you can include --platform linux/amd64 or --platform linux/arm64 to run the container as the specified architecture. The /shared_folder should be a folder on your local machine containing the requirement scripts.
For running the download-requirements.sh script you will need a RedHat developer subscription to register the running container and make sure you can access to official Redhat repos for the packages needed. More information on getting this free subscription here.
When you are inside the container run the following commands to prepare for the running of the download-requirements.sh script:
subscription-manager register # will ask for you credentials of your RedHat developer subscription and setup the container
subscription-manager attach --auto # will enable the RedHat official repositories
chmod +x /home/download-requirements.sh # make the requirements script executable
After this you should be able to run the download-requirements.sh from the home folder.
For CentOS, you can use the following command to launch a container:
arm64:
docker run -v /shared_folder:/home --platform linux/arm64 --rm -it arm64v8/centos:7.9.2009
x86_64:
docker run -v /shared_folder:/home --platform linux/amd64 --rm -it amd64/centos:7.9.2009
The /shared_folder should be a folder on your local machine containing the requirement scripts.
When you are inside the container run the following commands to prepare for the running of the download-requirements.sh script:
chmod +x /home/download-requirements.sh # make the requirements script executable
After this you should be able to run the download-requirements.sh from the home folder.
LambdaStack uses a concept called named lists in the configuration YAML. Every item in a named list has the name key to identify it and make it unique for merge operation:
...
list:
- name: item1
property1: value1
property2: value2
- name: item2
property1: value3
property2: value4
...
By default, a named list in your configuration file will completely overwrite the defaults that LambdaStack provides. This behaviour is on purpose so when you, for example, define a list of users for Kafka inside your configuration it completely overwrites the users defined in the Kafka defaults.
In some cases, however, you don't want to overwrite a named list. A good example would be the application configurations.
You don't want to re-define every item just to make sure LambdaStack has all default items needed by the Ansible automation. That is where the _merge metadata tag comes in. It will let you define whether you want to overwrite or merge a named list by setting it to true or false.
For example you want to enable the auth-service application. Instead of defining the whole configuration/applications configuration you can do the following:
kind: configuration/applications
title: "Kubernetes Applications Config"
name: default
provider: azure
specification:
applications:
- _merge: true
- name: auth-service
enabled: true
The _merge item with true will tell lambdastack to merge the application list and only change the enabled: true setting inside the auth-service and take the rests of the configuration/applications configuration from the defaults.
To configure PostgreSQL, login to server using ssh and switch to postgres user with command:
sudo -u postgres -i
Then configure database server using psql according to your needs and PostgreSQL documentation.
LambdaStack sets up MD5 password encryption. Although PostgreSQL since version 10 is able to use SCRAM-SHA-256 password encryption, LambdaStack does not support this encryption method since recommended production configuration uses more than one database host with HA configuration (repmgr) cooperating with PgBouncer and Pgpool. Pgpool is not able to parse SCRAM-SHA-256 hashes list while this encryption is enabled. Due to limited Pgpool authentication options, it is not possible to refresh the pool_passwd file automatically. For this reason, MD5 password encryption is set up and this is not configurable in LambdaStack.
PostgreSQL connection pooling in LambdaStack is served by PgBouncer application. It is available as Kubernetes ClusterIP or standalone package.
The Kubernetes based installation works together with PgPool so it supports PostgreSQL HA setup.
The standalone installation (described below) is deprecated and will be removed in the next release.
NOTE
PgBouncer extension is not supported on ARM.
PgBouncer is installed only on PostgreSQL primary node. This needs to be enabled in configuration yaml file:
kind: configuration/postgresql
specification:
extensions:
...
pgbouncer:
enabled: yes
...
PgBouncer listens on standard port 6432. Basic configuration is just template, with very limited access to database. This is because of security reasons. Configuration needs to be tailored according component documentation and stick to security rules and best practices.
NOTE 1
Replication (repmgr) extension is not supported on ARM.
NOTE 2
Changing number of PostgreSQL nodes is not supported by LambdaStack after first apply. Before cluster deployment think over what kind of configuration you need, and how many PostgreSQL nodes will be needed.
This component can be used as a part of PostgreSQL clustering configured by LambdaStack. In order to configure PostgreSQL HA replication, add to your configuration file a block similar to the one below to core section:
---
kind: configuration/postgresql
name: default
title: PostgreSQL
specification:
config_file:
parameter_groups:
...
# This block is optional, you can use it to override default values
- name: REPLICATION
subgroups:
- name: Sending Server(s)
parameters:
- name: max_wal_senders
value: 10
comment: maximum number of simultaneously running WAL sender processes
when: replication
- name: wal_keep_size
value: 500
comment: the size of WAL files held for standby servers (MB)
when: replication
- name: Standby Servers
parameters:
- name: hot_standby
value: 'on'
comment: must be 'on' for repmgr needs, ignored on primary but recommended
in case primary becomes standby
when: replication
extensions:
...
replication:
enabled: true
replication_user_name: ls_repmgr
replication_user_password: PASSWORD_TO_CHANGE
privileged_user_name: ls_repmgr_admin
privileged_user_password: PASSWORD_TO_CHANGE
repmgr_database: ls_repmgr
shared_preload_libraries:
- repmgr
...
If enabled is set to true for replication extension, LambdaStack will automatically create a cluster of primary and
secondary server with replication user with name and password specified in configuration file. This is only possible for
configurations containing two PostgreSQL servers.
Privileged user is used to perform full backup of primary instance and replicate this at the beginning to secondary node. After that for replication only replication user with limited permissions is used for WAL replication.
In order to maintenance work sometimes PostgreSQL service needs to be stopped. Before this action repmgr service needs to be paused, see manual page before. When repmgr service is paused steps from PostgreSQL manual page may be applied or stop it as a regular systemd service.
If one of database nodes has been recovered to desired state, you may want to re-attach it to database cluster. Execute these steps on node which will be attached as standby:
repmgr standby clone -h CURRENT_PRIMARY_ADDRESS -U ls_repmgr_admin -d ls_repmgr --force
repmgr standby register
You may use option --force if the node was registered in cluster before. For more options, see repmgr manual: https://repmgr.org/docs/5.2/repmgr-standby-register.html
For some reason you may want to switchover database nodes (promote standby to primary and demote existing primary to standby).
Configure passwordless SSH communication for postgres user between database nodes.
Test and run initial login between nodes to authenticate host (if host authentication is enabled).
Execute commands listed below on actual standby node
repmgr cluster show
repmgr standby switchover
This section describes how to set up connection pooling and load balancing for highly available PostgreSQL cluster. The default configuration provided by LambdaStack is meant for midrange class systems but can be customized to scale up or to improve performance.
To adjust the configuration to your needs, you can refer to the following documentation:
| Component | Documentation URL |
|---|---|
| PgBouncer | https://www.pgbouncer.org/config.html |
| PgPool: Performance Considerations | https://www.pgpool.net/docs/41/en/html/performance.html |
| PgPool: Server Configuration | https://www.pgpool.net/docs/41/en/html/runtime-config.html |
| PostgreSQL: connections | https://www.postgresql.org/docs/10/runtime-config-connection.html |
| PostgreSQL: resources management | https://www.postgresql.org/docs/10/runtime-config-resource.html |
NOTE
PgBouncer and PgPool Docker images are not supported for ARM. If these applications are enabled in configuration, installation will fail.
PgBouncer and PgPool are provided as K8s deployments. By default, they are not installed. To deploy them you need to
add configuration/applications document to your configuration yaml file, similar to the example below (enabled flags
must be set as true):
---
kind: configuration/applications
version: 1.2.0
title: "Kubernetes Applications Config"
provider: aws
name: default
specification:
applications:
...
## --- pgpool ---
- name: pgpool
enabled: true
...
namespace: postgres-pool
service:
name: pgpool
port: 5432
replicas: 3
...
resources: # Adjust to your configuration, see https://www.pgpool.net/docs/42/en/html/resource-requiremente.html
limits:
# cpu: 900m # Set according to your env
memory: 310Mi
requests:
cpu: 250m # Adjust to your env, increase if possible
memory: 310Mi
pgpool:
# https://github.com/bitnami/bitnami-docker-pgpool#configuration + https://github.com/bitnami/bitnami-docker-pgpool#environment-variables
env:
PGPOOL_BACKEND_NODES: autoconfigured # you can use custom value like '0:pg-node-1:5432,1:pg-node-2:5432'
# Postgres users
PGPOOL_POSTGRES_USERNAME: ls_pgpool_postgres_admin # with SUPERUSER role to use connection slots reserved for superusers for K8s liveness probes, also for user synchronization
PGPOOL_SR_CHECK_USER: ls_pgpool_sr_check # with pg_monitor role, for streaming replication checks and health checks
# ---
PGPOOL_ADMIN_USERNAME: ls_pgpool_admin # Pgpool administrator (local pcp user)
PGPOOL_ENABLE_LOAD_BALANCING: false # set to 'false' if there is no replication
PGPOOL_MAX_POOL: 4
PGPOOL_CHILD_LIFE_TIME: 300
PGPOOL_POSTGRES_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_postgres_password
PGPOOL_SR_CHECK_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_sr_check_password
PGPOOL_ADMIN_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_admin_password
secrets:
pgpool_postgres_password: PASSWORD_TO_CHANGE
pgpool_sr_check_password: PASSWORD_TO_CHANGE
pgpool_admin_password: PASSWORD_TO_CHANGE
# https://www.pgpool.net/docs/42/en/html/runtime-config.html
pgpool_conf_content_to_append: |
#------------------------------------------------------------------------------
# CUSTOM SETTINGS (appended by LambdaStack to override defaults)
#------------------------------------------------------------------------------
# num_init_children = 32
connection_life_time = 600
reserved_connections = 1
# https://www.pgpool.net/docs/41/en/html/auth-pool-hba-conf.html
pool_hba_conf: autoconfigured
## --- pgbouncer ---
- name: pgbouncer
enabled: true
...
namespace: postgres-pool
service:
name: pgbouncer
port: 5432
replicas: 2
resources:
requests:
cpu: 250m
memory: 128Mi
limits:
cpu: 500m
memory: 128Mi
pgbouncer:
env:
DB_HOST: pgpool.postgres-pool.svc.cluster.local
DB_LISTEN_PORT: 5432
MAX_CLIENT_CONN: 150
DEFAULT_POOL_SIZE: 25
RESERVE_POOL_SIZE: 25
POOL_MODE: session
CLIENT_IDLE_TIMEOUT: 0
This chapter describes the default setup and main parameters responsible for the performance limitations. The limitations can be divided into 3 layers: resource usage, connection limits and query caching. All the configuration parameters can be modified in the configuration yaml file.
Each of the components has hardware requirements that depend on its configuration, in particular on the number of allowed connections.
replicas: 2
resources:
requests:
cpu: 250m
memory: 128Mi
limits:
cpu: 500m
memory: 128Mi
replicas: 3
resources: # Adjust to your configuration, see https://www.pgpool.net/docs/41/en/html/resource-requiremente.html
limits:
# cpu: 900m # Set according to your env
memory: 310Mi
requests:
cpu: 250m # Adjust to your env, increase if possible
memory: 310Mi
By default, each PgPool pod requires 176 MB of memory. This value has been determined based on
PgPool docs, however after stress testing we need
to add several extra megabytes to
avoid failed to fork a child issue. You may need to
adjust resources after changing num_init_children or max_pool (PGPOOL_MAX_POOL) settings. Such changes should be
synchronized with PostgreSQL and PgBouncer configuration.
Memory related parameters have PostgreSQL default values. If your setup requires performance improvements, you may consider changing values of the following parameters:
The default settings can be overridden by LambdaStack using configuration/postgresql doc in the configuration yaml file.
There are connection limitations defined in PgBouncer configuration. Each of these parameters is defined per PgBouncer instance (pod). For example, having 2 pods (with MAX_CLIENT_CONN = 150) allows for up to 300 client connections.
pgbouncer:
env:
...
MAX_CLIENT_CONN: 150
DEFAULT_POOL_SIZE: 25
RESERVE_POOL_SIZE: 25
POOL_MODE: session
CLIENT_IDLE_TIMEOUT: 0
By default, POOL_MODE is set to session to be transparent for Pgbouncer client. This section should be adjusted depending on your desired configuration. Rotating connection modes are well described in Official Pgbouncer documentation.
If your client application doesn't manage sessions you can use CLIENT_IDLE_TIMEOUT to force session timeout.
By default, PgPool service is configured to handle up to 93 active concurrent connections to PostgreSQL (3 pods x 31). This is because of the following settings:
num_init_children = 32
reserved_connections = 1
Each pod can handle up to 32 concurrent connections but one is reserved. This means that the 32nd connection from a client will be refused. Keep in mind that canceling a query creates another connection to PostgreSQL, thus, a query cannot be canceled if all the connections are in use. Furthermore, for each pod, one connection slot must be available for K8s health checks. Hence, the real number of available concurrent connections is 30 per pod.
If you need more active concurrent connections, you can increase the number of pods (replicas), but the total number
of allowed concurrent connections should not exceed the value defined by PostgreSQL parameters: (max_connections - superuser_reserved_connections).
In order to change PgPool settings (defined in pgpool.conf), you can edit pgpool_conf_content_to_append section:
pgpool_conf_content_to_append: |
#------------------------------------------------------------------------------
# CUSTOM SETTINGS (appended by LambdaStack to override defaults)
#------------------------------------------------------------------------------
connection_life_time = 900
reserved_connections = 1
The content of pgpool.conf file is stored in K8s pgpool-config-files ConfigMap.
For detailed information about connection tuning, see "Performance Considerations" chapter in PgPool documentation.
PostgreSQL uses max_connections parameter to limit the number of client connections to database server. The default is
typically 100 connections. Generally, PostgreSQL on sufficient amount of hardware can support a few hundred connections.
Query caching is not available in PgBouncer.
Query caching is disabled by default in PgPool configuration.
PostgreSQL is installed with default settings.
Audit logging of database activities is available through the PostgreSQL Audit Extension: PgAudit. It provides session and/or object audit logging via the standard PostgreSQL log.
PgAudit may generate a large volume of logging, which has an impact on performance and log storage. For this reason, PgAudit is not enabled by default.
To install and configure PgAudit, add to your configuration yaml file a doc similar to the following:
kind: configuration/postgresql
title: PostgreSQL
name: default
provider: aws
version: 1.0.0
specification:
extensions:
pgaudit:
enabled: yes
config_file_parameters:
## postgresql standard
log_connections: 'off'
log_disconnections: 'off'
log_statement: 'none'
log_line_prefix: "'%m [%p] %q%u@%d,host=%h '"
## pgaudit specific, see https://github.com/pgaudit/pgaudit/blob/REL_10_STABLE/README.md#settings
pgaudit.log: "'write, function, role, ddl' # 'misc_set' is not supported for PG 10"
pgaudit.log_catalog: 'off # to reduce overhead of logging'
# the following first 2 parameters are set to values that make it easier to access audit log per table
# change their values to the opposite if you need to reduce overhead of logging
pgaudit.log_relation: 'on # separate log entry for each relation'
pgaudit.log_statement_once: 'off'
pgaudit.log_parameter: 'on'
If enabled property for PgAudit extension is set to yes, LambdaStack will install PgAudit package and add PgAudit
extension to be loaded
in shared_preload_libraries
. Settings defined in config_file_parameters section are populated to LambdaStack managed PostgreSQL configuration file.
Using this section, you can also set any additional parameter if needed (e.g. pgaudit.role) but keep in mind that
these settings are global.
To configure PgAudit according to your needs, see PgAudit documentation.
Once LambdaStack installation is complete, there is one manual action at database level (per each database). Connect to your database using a client (like psql) and load PgAudit extension into current database by running command:
CREATE EXTENSION pgaudit;
To remove the extension from database, run:
DROP EXTENSION IF EXISTS pgaudit;
PostgreSQL connection pooling is described in design documentaion page. Properly configured application (kubernetes service) to use fully HA configuration should be set up to connect to pgbouncer service (kubernetes) instead directly to database host. This configuration provides all the benefits of user PostgreSQL in clusteres HA mode (including database failover). Both pgbouncer and pgpool stores database users and passwords in configuration files and needs to be restarted (pods) in case of PostgreSQL authentication changes like: create, alter username or password. Pods during restart process are refreshing stored database credentials automatically.
PostgreSQL native replication is now deprecated and removed. Use PostgreSQL HA replication with repmgr instead.
OpenDistro for Elasticsearch is an Apache 2.0-licensed distribution of Elasticsearch enhanced with enterprise security, alerting, SQL. In order to start working with OpenDistro change machines count to value greater than 0 in your cluster configuration:
kind: lambdastack-cluster
...
specification:
...
components:
kubernetes_master:
count: 1
machine: aws-kb-masterofpuppets
kubernetes_node:
count: 0
...
logging:
count: 1
opendistro_for_elasticsearch:
count: 2
Installation with more than one node will always be clustered - Option to configure the non-clustered installation of more than one node for Open Distro is not supported.
kind: configuration/opendistro-for-elasticsearch
title: OpenDistro for Elasticsearch Config
name: default
specification:
cluster_name: LambdaStackElastic
By default, Kibana is deployed only for logging component. If you want to deploy Kibana
for opendistro_for_elasticsearch you have to modify feature mapping. Use below configuration in your manifest.
kind: configuration/feature-mapping
title: "Feature mapping to roles"
name: default
specification:
roles_mapping:
opendistro_for_elasticsearch:
- opendistro-for-elasticsearch
- node-exporter
- filebeat
- firewall
- kibana
Filebeat running on opendistro_for_elasticsearch hosts will always point to centralized logging hosts (./LOGGING.md).
Apache Ignite can be installed in LambdaStack if count property for ignite feature is greater than 0. Example:
kind: lambdastack-cluster
specification:
components:
load_balancer:
count: 1
ignite:
count: 2
rabbitmq:
count: 0
...
Configuration like in this example will create Virtual Machines with Apache Ignite cluster installed. There is possible to modify configuration for Apache Ignite and plugins used.
kind: configuration/ignite
title: "Apache Ignite stateful installation"
name: default
specification:
version: 2.7.6
file_name: apache-ignite-2.7.6-bin.zip
enabled_plugins:
- ignite-rest-http
config: |
<?xml version="1.0" encoding="UTF-8"?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="grid.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!-- Set the page size to 4 KB -->
<property name="pageSize" value="#{4 * 1024}"/>
<!--
Sets a path to the root directory where data and indexes are
to be persisted. It's assumed the directory is on a separated SSD.
-->
<property name="storagePath" value="/var/lib/ignite/persistence"/>
<!--
Sets a path to the directory where WAL is stored.
It's assumed the directory is on a separated HDD.
-->
<property name="walPath" value="/wal"/>
<!--
Sets a path to the directory where WAL archive is stored.
The directory is on the same HDD as the WAL.
-->
<property name="walArchivePath" value="/wal/archive"/>
</bean>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
IP_LIST_PLACEHOLDER
</property>
</bean>
</property>
</bean>
</property>
</bean>
</beans>
Property enabled_plugins contains list with plugin names that will be enabled. Property config contains xml
configuration for Apache Ignite. Important placeholder variable is IP_LIST_PLACEHOLDER which will be replaced by
automation with list of Apache Ignite nodes for self discovery.
Stateless setup of Apache Ignite is done using Kubernetes deployments. This setup uses standard applications
LambdaStack's feature (similar to auth-service, rabbitmq). To enable stateless Ignite deployment use following
document:
kind: configuration/applications
title: "Kubernetes Applications Config"
name: default
specification:
applications:
- name: ignite-stateless
image_path: "lambdastack/ignite:2.9.1" # it will be part of the image path: {{local_repository}}/{{image_path}}
namespace: ignite
service:
rest_nodeport: 32300
sql_nodeport: 32301
thinclients_nodeport: 32302
replicas: 1
enabled_plugins:
- ignite-kubernetes # required to work on K8s
- ignite-rest-http
Adjust this config to your requirements with number of replicas and plugins that should be enabled.
LambdaStack provides Helm repository for internal usage inside our Ansible codebase. Currently only the "system" repository is available, but it's not designed to be used by regular users. In fact, regular users must not reuse it for any purpose.
LambdaStack developers can find it inside this location roles/helm_charts/files/system. To add a chart to the repository it's enough just to put unarchived chart directory tree inside the location (in a separate directory) and re-run epcli apply.
When the repository Ansible role is run it copies all unarchived charts to the repository host, creates Helm repository (index.yaml) and serves all these files from Apache HTTP server.
LambdaStack developers can reuse the "system" repository from any place inside the Ansible codebase. Moreover, it's a responsibility of a particular role to call the helm upgrade --install command.
There is a helpler task file that can be reused for that purpose roles/helm/tasks/install-system-release.yml. It's only responsible for installing already existing "system" Helm charts from the "system" repository.
This helper task expects such parameters/facts:
- set_fact:
helm_chart_name: <string>
helm_chart_values: <map>
helm_release_name: <string>
helm_chart_values is a standard yaml map, values defined there replace default config of the chart (values.yaml).Our standard practice is to place those values inside the specification document of the role that deploys the Helm release in Kubernetes.
Example config:
kind: configuration/<mykind-used-by-myrole>
name: default
specification:
helm_chart_name: mychart
helm_release_name: myrelease
helm_chart_values:
service:
port: 8080
nameOverride: mychart_custom_name
Example usage:
- name: Mychart
include_role:
name: helm
tasks_from: install-system-release.yml
vars:
helm_chart_name: "{{ specification.helm_chart_name }}"
helm_release_name: "{{ specification.helm_release_name }}"
helm_chart_values: "{{ specification.helm_chart_values }}"
By default all installed "system" Helm releases are deployed inside the ls-charts namespace in Kubernetes.
To uninstall Helm release roles/helm/tasks/delete-system-release.yml can be used. For example:
- include_role:
name: helm
tasks_from: delete-system-release.yml
vars:
helm_release_name: myrelease
Open source platform which allows you to run service mesh for distributed microservice architecture. It allows to connect, manage and run secure connections between microservices and brings lots of features such as load balancing, monitoring and service-to-service authentication without any changes in service code. Read more about Istio here.
Istio in LambdaStack is provided as K8s application. By default, it is not installed. To deploy it you need to add "configuration/applications" document to your configuration yaml file, similar to the example below (enabled flag must be set as true):
Istio is installed using Istio Operator. Operator is a software extension to the Kubernetes API which has a deep knowledge how Istio deployments should look like and how to react if any problem appears. It is also very easy to make upgrades and automate tasks that would normally be executed by user/admin.
---
kind: configuration/applications
version: 0.8.0
title: "Kubernetes Applications Config"
provider: aws
name: default
specification:
applications:
...
## --- istio ---
- name: istio
enabled: true
use_local_image_registry: true
namespaces:
operator: istio-operator # namespace where operator will be deployed
watched: # list of namespaces which operator will watch
- istio-system
istio: istio-system # namespace where Istio control plane will be deployed
istio_spec:
profile: default # Check all possibilites https://istio.io/latest/docs/setup/additional-setup/config-profiles/
name: istiocontrolplane
Using this configuration file, controller will detect Istio Operator resource in first of watched namespaces and will install Istio components corresponding to the specified profile (default). Using the default profile, Istio control plane and Istio ingress gateway will be deployed in istio-system namespace.
The default Istio installation uses automcatic sidecar injection. You need to label the namespace where application will be hosted:
kubectl label namespace default istio-injection=enabled
Once the proper namespaces are labeled and Istio is deployed, you can deploy your applications or restart existing ones.
You may need to make an application accessible from outside of your Kubernetes cluster. An Istio Gateway which was deployed using default profile is used for this purpose. Define the ingress gateway deploying gateway and virtual service specification. The gateway specification describes the L4-L6 properties of a load balancer and the virtual service specification describes the L7 properties of a load balancer.
Example of the gateway and virtual service specification (You have to adapt the entire specification to the application):
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: httpbin-gateway
spec:
selector:
istio: ingressgateway # use Istio default gateway implementation
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "httpbin.example.com"
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- "httpbin.example.com"
gateways:
- httpbin-gateway
http:
- match:
- uri:
prefix: /status
- uri:
prefix: /delay
route:
- destination:
port:
number: 8000
host: httpbin
:warning: Pay attention to the network policies in your cluster if a CNI plugin is used that supports them (such as Calico or Canal). In this case, you should set up secure network policies for inter-microservice communication and communication between Envoy proxy and Istio control plane in your application's namespace. You can also just apply the following NetworkPolicy:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
namespace: <your_application_namespace>
name: allow-istio-communication
spec:
podSelector: {}
egress:
- {}
ingress:
- {}
policyTypes:
- Egress
- Ingress
Replaces using SSH Tunneling
This is currently a WIP (Work In Progress). Ansible playbook roles are being built and tested along with testing.
See Troubleshooting
You can see from the Troubleshooting link above that the default secruity setup for kubectl is to have sudo rights to run and then to specify the kubeconfig=/etc/kubernetes/admin.conf as an additional parameter to kubectl. Also, by default, this only works on the Control Plane nodes. To have it work on Worker nodes or any node in the cluster do the following. Make sure it complies with your Security strategy:
# Control Plane node - Option 2 from link above...
mkdir -p $HOME/.kube
sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Once kubectl is working as desired from a non-root user, you can simply:
./kube/config file from the Control Plane node./kube directory in the non-root user's home directory and then paste the config file copied in #1kubectl on for a given clusterLambdaStack supports following CNI plugins:
Flannel is a default setting in LambdaStack configuration.
NOTE
Calico is not supported on Azure. To have an ability to use network policies, choose Canal.
Use the following configuration to set up an appropriate CNI plugin:
kind: configuration/kubernetes-master
name: default
specification:
advanced:
networking:
plugin: flannel
Currently, LambdaStack provides the following predefined applications which may be deployed with lambdastack:
All of them have
default configuration.
The common parameters are: name, enabled, namespace, image_path and use_local_image_registry.
If you set use_local_image_registry to false in configuration manifest, you have to provide a valid docker image
path in image_path. Kubernetes will try to pull image from image_path value externally.
To see what version of the application image is in local image registry please refer
to components list.
Note: The above link points to develop branch. Please choose the right branch that suits to LambdaStackphany version you are using.
Create NodePort service type for your application in Kubernetes.
Make sure your service has statically assigned nodePort (a number between 30000-32767), for example 31234.
More info here.
Add configuration document for load_balancer/HAProxy to your main config file.
kind: configuration/haproxy
title: "HAProxy"
name: haproxy
specification:
frontend:
- name: https_front
port: 443
https: yes
backend:
- http_back1
backend:
- name: http_back1
server_groups:
- kubernetes_node
port: 31234
provider: <your-provider-here-replace-it>
Run lambdastack apply.
Kubernetes that comes with LambdaStack has an admin account created, you should consider creating more roles and accounts - especially when having many deployments running on different namespaces.
To know more about RBAC in Kubernetes use this link
Here we will get a simple app to run using Docker through Kubernetes. We assume you are using Windows 10, have an LambdaStack cluster on Azure ready and have an Azure Container Registry ready (might not be created in early version LambdaStack clusters. If you don't have one you can skip to point no 11 and test the cluster using some public app from the original Docker Registry). Steps with asterisk can be skipped.
Install Chocolatey
Use Chocolatey to install:
choco install docker-for-windows, requires Hyper-V)choco install azure-cli)Make sure Docker for Windows is running (run as admin, might require a restart)
Run docker build -t sample-app:v1 . in examples/dotnet/lambdastack-web-app.
*For test purposes, run your image locally with docker run -d -p 8080:80 --name myapp sample-app:v1 and head to localhost:8080 to check if it's working.
*Stop your local docker container with: docker stop myapp and run docker rm myapp to delete the container.
*Now that you have a working docker image we can proceed to the deployment of the app on the LambdaStack Kubernetes cluster.
Run docker login myregistry.azurecr.io -u myUsername -p myPassword to login into your Azure Container Registry. Credentials are in the Access keys tab in your registry.
Tag your image with: docker tag sample-app:v1 myregistry.azurecr.io/samples/sample-app:v1
Push your image to the repo: docker push myregistry.azurecr.io/samples/sample-app:v1
SSH into your LambdaStack clusters master node.
*Run kubectl cluster-info and kubectl config view to check if everything is okay.
Run kubectl create secret docker-registry myregistry --docker-server myregistry.azurecr.io --docker-username myusername --docker-password mypassword to create k8s secret with your registry data.
Create sample-app.yaml file with contents:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
spec:
selector:
matchLabels:
app: sample-app
replicas: 2
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: sample-app
image: myregistry.azurecr.io/samples/sample-app:v1
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 64Mi
limits:
memory: 128Mi
imagePullSecrets:
- name: myregistry
Run kubectl apply -f sample-app.yaml, and after a minute run kubectl get pods to see if it works.
Run kubectl expose deployment sample-app --type=NodePort --name=sample-app-nodeport, then run kubectl get svc sample-app-nodeport and note the second port.
Run kubectl get pods -o wide and check on which node is the app running.
Access the app through [AZURE_NODE_VM_IP]:[PORT] from the two previous points - firewall changes might be needed.
When Kubernetes schedules a Pod, it’s important that the Containers have enough resources to actually run. If you schedule a large application on a node with limited resources, it is possible for the node to run out of memory or CPU resources and for things to stop working! It’s also possible for applications to take up more resources than they should.
When you specify a Pod, it is strongly recommended to specify how much CPU and memory (RAM) each Container needs. Requests are what the Container is guaranteed to get. If a Container requests a resource, Kubernetes will only schedule it on a node that can give it that resource. Limits make sure a Container never goes above a certain value. For more details about the difference between requests and limits, see Resource QoS.
For more information, see the links below:
NOTE: Examples have been moved to their own repo but they are not visible at the moment.
Follow the previous point using examples/dotnet/LambdaStack.SampleApps/LambdaStack.SampleApps.CronApp
Create cronjob.yaml file with contents:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: sample-cron-job
spec:
schedule: "*/1 * * * *" # Run once a minute
failedJobsHistoryLimit: 5
jobTemplate:
spec:
template:
spec:
containers:
- name: sample-cron-job
image: myregistry.azurecr.io/samples/sample-cron-app:v1
restartPolicy: OnFailure
imagePullSecrets:
- name: myregistrysecret
Run kubectl apply -f cronjob.yaml, and after a minute run kubectl get pods to see if it works.
Run kubectl get cronjob sample-cron-job to get status of our cron job.
Run kubectl get jobs --watch to see job scheduled by the “sample-cron-job” cron job.
Prerequisites: LambdaStack cluster on Azure with at least a single VM with prometheus and grafana roles enabled.
Copy ansible inventory from build/lambdastack/*/inventory/ to examples/monitoring/
Run ansible-playbook -i NAME_OF_THE_INVENTORY_FILE grafana.yml in examples/monitoring
In the inventory file find the IP adress of the node of the machine that has grafana installed and head over to https://NODE_IP:3000 - you might have to head over to Portal Azure and allow traffic to that port in the firewall, also ignore the possible certificate error in your browser.
Head to Dashboards/Manage on the side panel and select Kubernetes Deployment metrics - here you can see a sample kubernetes monitoring dashboard.
Head to http://NODE_IP:9090 to see Prometheus UI - there in the dropdown you have all of the metrics you can monitor with Prometheus/Grafana.
SSH into the Kubernetes master.
Copy over chaos-sample.yaml file from the example folder and run it with kubectl apply -f chaos-sample.yaml - it takes code from github.com/linki/chaoskube so normal security concerns apply.
Run kubectl create clusterrolebinding chaos --clusterrole=cluster-admin --user=system:serviceaccount:default:default to start the chaos - random pods will be terminated with 5s ferquency, configurable inside the yaml file.
Head over to Grafana at https://NODE_IP:3000, open a new dashboard, add a panel, set Prometheus as a data source and put kubelet_running_pod_count in the query field - now you can see how Kubernetes is replacing killed pods and balancing them between the nodes.
Run kubectl get svc nginx-service and note the second port. You can access the nginx page via [ANY_CLUSTER_VM_IP]:[PORT] - it is accessible even though random pods carrying it are constantly killed at random, unless you have more vms in your cluster than deployed nginx instances and choose IP of one not carrying it.
Prerequisites: LambdaStack cluster on Azure with at least a single VM with elasticsearch, kibana and filebeat roles enabled.
Connect to kubectl using kubectl proxy or directly from Kubernetes master server
Apply from LambdaStack repository extras/kubernetes/pod-counter pod-counter.yaml with command: kubectl apply -f yourpath_to_pod_counter/pod-counter.yaml
Paths are system dependend so please be aware of applying correct separator for your operatins system.
In the inventory file find the IP adress of the node of the machine that has kibana installed and head over to http://NODE_IP:5601 - you might have to head over to Portal Azure and allow traffic to that port in the firewall.
You can right now search for data from logs in Discover section in Kibana after creating filebeat-* index pattern. To create index pattern click Discover, then in Step 1: Define index pattern as filebeat-*. Then click Next step. In Step 2: Configure settings click Create index pattern. Right now you can go to Discover section and look at output from your logs.
You can verify if CounterPod is sending messages correctly and filebeat is gathering them correctly querying for CounterPod in search field in Discover section.
For more informations refer to documentation: https://www.elastic.co/guide/en/kibana/current/index.html
SSH into server, and forward port 8001 to your machine ssh -i ls_keys/id_rsa operations@40.67.255.155 -L 8001:localhost:8001 NOTE: substitute IP with your cluster master's IP.
On remote host: get admin token bearer: kubectl describe secret $(kubectl get secrets --namespace=kube-system | grep admin-user | awk '{print $1}') --namespace=kube-system | grep -E '^token' | awk '{print $2}' | head -1 NOTE: save this token for next points.
On remote host, open proxy to the dashboard kubectl proxy
Now on your local machine navigate to http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
When prompted to put in credentials, use admin token from the previous point.
count value.kind: lambdastack-cluster
title: LambdaStack Cluster Config
provider: azure
name: default
build_path: '' # Dynamically built
specification:
components:
repository:
count: 1
kubernetes_master:
count: 1
kubernetes_node:
count: 2
postgresql:
count: 2
applications in feature-mapping in initial configuration manifest.---
kind: configuration/feature-mapping
title: Feature mapping to roles
name: default
specification:
available_roles:
- _merge: true
- name: applications
enabled: true
enabled: true and adjust other parameters in configuration/applications kind.The default applications configuration available here
Note: To get working with Pgbouncer, Keycloak requires Pgbouncer configuration parametr POOL_MODE set to session, see Installing Pgbouncer and Pgpool section. The reason is that Keycloak uses SET SQL statements. For details see SQL feature map for pooling modes.
---
kind: configuration/applications
title: Kubernetes Applications Config
name: default
specification:
applications:
- _merge: true
- name: auth-service
enabled: true
image_path: lambdastack/keycloak:14.0.0
use_local_image_registry: true
service:
name: as-testauthdb
port: 30104
replicas: 2
namespace: namespace-for-auth
admin_user: auth-service-username
admin_password: PASSWORD_TO_CHANGE
database:
name: auth-database-name
user: auth-db-user
password: PASSWORD_TO_CHANGE
To set specific database host IP address for Keyclock you have to provide additional parameter address:
database:
address: 10.0.0.2
Note: If database address is not specified, lambdastack assumes that database instance doesn't exist and will create it.
By default, if database address is not specified and if Postgres is HA mode, Keycloak uses PGBouncer ClusterIP service name as database address.
If Postgres is in standalone mode, and database address is not specified, then it uses first Postgres host address from inventory.
Run lambdastack apply on your configuration manifest.
Log into GUI
Note: Accessing the Keycloak GUI depends on your configuration.
By default, LambdaStack provides the following K8s Services for Keycloak: Headless and NodePort.
The simplest way for reaching GUI is to use ssh tunnel with forwarding NodePort.
Example:
ssh -L 30104:localhost:30104 user@target_host -i ssh_key
If you need your GUI accesible outside, you would have to change your firewall rules.
GUI should be reachable at: https://localhost:30104/auth
For centralized logging LambdaStack uses OpenDistro for Elasticsearch.
In order to enable centralized logging, be sure that count property for logging feature is greater than 0 in your
configuration manifest.
kind: lambdastack-cluster
...
specification:
...
components:
kubernetes_master:
count: 1
kubernetes_node:
count: 0
...
logging:
count: 1
...
...
logging:
- logging
- kibana
- node-exporter
- filebeat
- firewall
...
Optional feature (role) available for logging: logstash more details here: link
The logging role replaced elasticsearch role. This change was done to enable Elasticsearch usage also for data
storage - not only for logs as it was till 0.5.0.
Default configuration of logging and opendistro_for_elasticsearch roles is identical (
./DATABASES.md#how-to-start-working-with-opendistro-for-elasticsearch). To modify configuration of centralized logging
adjust and use the following defaults in your manifest:
kind: configuration/logging
title: Logging Config
name: default
specification:
cluster_name: LambdaStackElastic
clustered: True
paths:
data: /var/lib/elasticsearch
repo: /var/lib/elasticsearch-snapshots
logs: /var/log/elasticsearch
Elasticsearch stores data using JSON documents, and an Index is a collection of documents. As in every database, it's crucial to correctly maintain data in this one. It's almost impossible to deliver database configuration which will fit to every type of project and data stored in. LambdaStack deploys preconfigured Opendistro Elasticsearch, but this configuration may not meet user requirements. Before going to production, configuration should be tailored to the project needs. All configuration tips and tricks are available in official documentation.
The main and most important decisions to take before you deploy cluster are:
These parameters are defined in yaml file, and it's important to create a big enough cluster.
specification:
components:
logging:
count: 1 # Choose number of nodes
---
kind: infrastructure/virtual-machine
title: "Virtual Machine Infra"
name: logging-machine
specification:
size: Standard_DS2_v2 # Choose machine size
If it's required to have Elasticsearch which works in cluster formation configuration, except setting up more than one machine in yaml config file please acquaint dedicated support article and adjust Elasticsearch configuration file.
At this moment Opendistro for Elasticsearch does not support plugin similar to ILM, log rotation is possible only by configuration created in Index State Management.
ISM - Index State Management - is a plugin that provides users and administrative panel to monitor the indices and
apply policies at different index stages. ISM lets users automate periodic, administrative operations by triggering them
based on index age, size, or number of documents. Using the ISM plugin, can define policies that automatically handle
index rollovers or deletions. ISM is installed with Opendistro by default - user does not have to enable this. Official
documentation is available
in Opendistro for Elasticsearch website.
To reduce the consumption of disk resources, every index you created should use well-designed policy.
Among others these two index actions might save machine from filling up disk space:
Index Rollover - rolls an alias
to a new index. Set up correctly max index size / age or minimum number of documents to keep index size in requirements
framework.
Index Deletion - deletes indexes
managed by policy
Combining these actions, adapting them to data amount and specification users are able to create policy which will maintain data in cluster for example: to secure node from fulfilling disk space.
There is example of policy below. Be aware that this is only example, and it needs to be adjusted to environment needs.
{
"policy": {
"policy_id": "ls_policy",
"description": "Safe setup for logs management",
"last_updated_time": 1615201615948,
"schema_version": 1,
"error_notification": null,
"default_state": "keep",
"states": [
{
"name": "keep",
"actions": [],
"transitions": [
{
"state_name": "delete",
"conditions": {
"min_index_age": "14d"
}
},
{
"state_name": "rollover_by_size",
"conditions": {
"min_size": "1gb"
}
},
{
"state_name": "rollover_by_time",
"conditions": {
"min_index_age": "1d"
}
}
]
},
{
"name": "delete",
"actions": [
{
"delete": {}
}
],
"transitions": []
},
{
"name": "rollover_by_size",
"actions": [
{
"rollover": {}
}
],
"transitions": []
},
{
"name": "rollover_by_time",
"actions": [
{
"rollover": {}
}
],
"transitions": []
}
]
}
}
Example above shows configuration with rollover daily or when index achieve 1 GB size. Indexes older than 14 days will be deleted. States and conditionals could be combined. Please see policies documentation for more details.
Apply Policy
To apply policy use similar API request as presented below:
PUT _template/template_01
{
"index_patterns": ["filebeat*"],
"settings": {
"opendistro.index_state_management.rollover_alias": "filebeat"
"opendistro.index_state_management.policy_id": "ls_policy"
}
}
After applying this policy, every new index created under this one will apply to it. There is also possibility to apply policy to already existing policies by assigning them to policy in Index Management Kibana panel.
Since v1.0 LambdaStack provides the possibility to export reports from Kibana to CSV, PNG or PDF using the Open Distro for Elasticsearch Kibana reports feature.
Check more details about the plugin and how to export reports in the documentation
Note: Currently in Open Distro for Elasticsearch Kibana the following plugins are installed and enabled by default: security, alerting, anomaly detection, index management, query workbench, notebooks, reports, alerting, gantt chart plugins.
You can easily check enabled default plugins for Kibana using the following command on the logging machine:
./bin/kibana-plugin list in Kibana directory.
Since v0.8 LambdaStack provides the possibility to export data from Elasticsearch to CSV using Logstash (logstash-oss) along with logstash-input-elasticsearch and logstash-output-csv plugins.
To install Logstash in your cluster add logstash to feature mapping for logging, opendistro_for_elasticsearch or * elasticsearch* group.
NOTE
To check plugin versions following command can be used
/usr/share/logstash/bin/logstash-plugin list --verbose
LambdaStack provides a basic configuration file (logstash-export.conf.template) as template for your data export. This
file has to be modified according to your Elasticsearch configuration and data you want to export.
NOTE
Exporting data is not automated. It has to be invoked manually. Logstash daemon is disabled by default after installation.
Run Logstash to export data:
/usr/share/logstash/bin/logstash -f /etc/logstash/logstash-export.conf
More details about configuration of input and output plugins.
NOTE
At the moment input plugin doesn't officially support skipping certificate validation for secure connection to Elasticsearch. For non-production environment you can easily disable it by adding new line:
ssl_options[:verify] = false right after other ssl_options definitions in file:
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-input-elasticsearch-*/lib/logstash/inputs/elasticsearch.rb
In order to properly handle multilines in files harvested by Filebeat you have to provide multiline definition in the
configuration manifest. Using the following code you will be able to specify which lines are part of a single event.
By default, postgresql block is provided, you can use it as example:
postgresql_input:
multiline:
pattern: >-
'^\d{4}-\d{2}-\d{2} '
negate: true
match: after
Supported inputs: common_input,postgresql_input,container_input
More details about multiline options you can find in
the official documentation
There is a possibility to deploy Filebeat as daemonset in K8s. To do that, set k8s_as_cloud_service option to true:
kind: lambdastack-cluster
specification:
cloud:
k8s_as_cloud_service: true
It is possible to configure setup.dashboards.enabled and setup.dashboards.index Filebeat settings using specification.kibana.dashboards key in configuration/filebeat doc.
When specification.kibana.dashboards.enabled is set to auto, the corresponding setting in Filebeat configuration file will be set to true only if Kibana is configured to be present on the host.
Other possible values are true and false.
Default configuration:
specification:
kibana:
dashboards:
enabled: auto
index: filebeat-*
Note: Setting specification.kibana.dashboards.enabled to true not providing Kibana will result in a Filebeat crash.
This part of the documentations covers the topic how to check if each component is working properly.
To verify that Docker services are up and running you can first check the status of the Docker service with the following command:
systemctl status docker
Additionally you can check also if the command:
docker info
doesn't return any error. You can also find there useful information about your Docker configuration.
First to check if everything is working fine we need to check verify status of Kubernetes kubelet service with the command:
systemctl status kubelet
We can also check state of Kubernetes nodes using the command:
root@primary01:~# kubectl get nodes --kubeconfig=/etc/kubernetes/admin.conf
NAME STATUS ROLES AGE VERSION
primary01 Ready master 24h v1.17.7
node01 Ready <none> 23h v1.17.7
node02 Ready <none> 23h v1.17.7
We can get additional information about Kubernetes components:
root@primary01:~# kubectl cluster-info --kubeconfig=/etc/kubernetes/admin.conf
Kubernetes master is running at https://primary01:6443
CoreDNS is running at https://primary01:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
We can also check status of pods in all namespaces using the command:
kubectl get pods -A --kubeconfig=/etc/kubernetes/admin.conf
We can get additional information about components statuses:
root@primary01:~# kubectl get cs --kubeconfig=/etc/kubernetes/admin.conf
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
For more detailed information please refer to official documentation
To check the if a Keycloak service deployed on Kubernetes is running with the command:
kubectl get pods --kubeconfig=/etc/kubernetes/admin.conf --namespace=keycloak_service_namespace --field-selector=status.phase=Running | grep keycloak_service_name
To check status of HAProxy we can use the command:
systemctl status haproxy
Additionally we can check if the application is listening on ports defined in the file haproxy.cfg running netstat command.
To check status of Prometheus we can use the command:
systemctl status prometheus
We can also check if Prometheus service is listening at the port 9090:
netstat -antup | grep 9090
To check status of Grafana we can use the command:
systemctl status grafana-server
We can also check if Grafana service is listening at the port 3000:
netstat -antup | grep 3000
To check status of Node Exporter we can use the command:
status prometheus-node-exporter
To check status of Elasticsearch we can use the command:
systemct status elasticsearch
We can check if service is listening on 9200 (API communication port):
netstat -antup | grep 9200
We can also check if service is listening on 9300 (nodes coummunication port):
netstat -antup | grep 9300
We can also check status of Elasticsearch cluster:
<IP>:9200/_cluster/health
We can do this using curl or any other equivalent tool.
To check status of Kibana we can use the command:
systemctl status kibana
We can also check if Kibana service is listening at the port 5601:
netstat -antup | grep 5601
To check status of Filebeat we can use the command:
systemctl status filebeat
To check status of PostgreSQL we can use commands:
systemctl status postgresql
systemctl status postgresql-10
where postgresql-10 is only an example, because the number differs from version to version. Please refer to your version number in case of using this command.
We can also check if PostgreSQL service is listening at the port 5432:
netstat -antup | grep 5432
We can also use the pg_isready command, to get information if the PostgreSQL server is running and accepting connections with command:
[user@postgres01 ~]$ pg_isready
/var/run/postgresql:5432 - accepting connections
[user@postgres01 ~]$ /usr/pgsql-10/bin/pg_isready
/var/run/postgresql:5432 - accepting connections
where the path /usr/pgsql-10/bin/pg_isready is only an example, because the number differs from version to version. Please refer to your version number in case of using this command.
In version 0.8 of LambdaStack we introduced modules. Modularization of LambdaStack environment will result in:
Those and multiple other factors (eg.: readability, reliability) influence this direction of changes.
From a user point of view, there will be no significant changes in the nearest future as it will be still possible to install LambdaStack "classic way" so with a single lambdastack configuration using a whole codebase as a monolith.
For those who want to play with new features, or will need newly introduced possibilities, there will be a short transition period which we consider as a kind of "preview stage". In this period there will be a need to run each module separately by hand in the following order:
Init, plan and apply phases explanation you'll find in next sections of this document. Main point is that dependent modules have to be executed one after another during this what we called "preview stage". Later, with next releases there will be separate mechanism introduced to orchestrate modules dependencies and their consecutive execution.
In 0.8 we offer the possibility to use AKS or EKS as Kubernetes providers. That is introduced with modules mechanism, so we launched the first four modules:
Those 4 modules together with the classic LambdaStack used with any provider allow replacing of on-prem Kubernetes cluster with managed Kubernetes services.
As it might be already visible there are 2 paths provided:
Those "... Basic Infrastructure" modules are responsible to provide basic cloud resources (eg.: resource groups, virtual networks, subnets, virtual machines, network security rules, routing, ect.) which will be used by next modules. So in this case, those are "... KS modules" meant to provide managed Kubernetes services. They use resources provided by basic infrastructure modules (eg.: subnets or resource groups) and instantiate managed Kubernetes services provided by cloud providers. The last element in both those cloud provider related paths is classic LambdaStack installed on top of resources provided by those modules using any provider.
In each module, we provided a guide on how to use the module. Please refer:
After deployment of EKS or AKS, you can perform LambdaStack installation on top of it.
NOTE - Default OS users:
Azure:
redhat: ec2-user
ubuntu: operations
AWS:
redhat: ec2-user
ubuntu: ubuntu
Create LambdaStack cluster config file in /tmp/shared/ls.yml
Example:
kind: lambdastack-cluster
title: LambdaStack Cluster Config
name: your-cluster-name # <----- make unified with other places and build directory name
build_path: # Dynamically built
provider: any # <----- use "any" provider
specification:
name: your-cluster-name # <----- make unified with other places and build directory name
admin_user:
name: operations # <----- make sure os-user is correct
key_path: /tmp/shared/vms_rsa # <----- use generated key file
path: # Dynamically built
cloud:
k8s_as_cloud_service: true # <----- make sure that flag is set, as it indicates usage of a managed Kubernetes service
components:
repository:
count: 1
machines:
- default-lambdastack-modules-test-all-0 # <----- make sure that it is correct VM name
kubernetes_master:
count: 0
kubernetes_node:
count: 0
logging:
count: 0
monitoring:
count: 0
kafka:
count: 0
postgresql:
count: 1
machines:
- default-lambdastack-modules-test-all-1 # <----- make sure that it is correct VM name
load_balancer:
count: 0
rabbitmq:
count: 0
---
kind: configuration/feature-mapping
title: Feature mapping to roles
name: your-cluster-name # <----- make unified with other places and build directory name
provider: any
specification:
roles_mapping:
repository:
- repository
- image-registry
- firewall
- filebeat
- node-exporter
- applications
---
kind: infrastructure/machine
name: default-lambdastack-modules-test-all-0
provider: any
specification:
hostname: lambdastack-modules-test-all-0
ip: 12.34.56.78 # <----- put here public IP attached to machine
---
kind: infrastructure/machine
name: default-lambdastack-modules-test-all-1
provider: any
specification:
hostname: lambdastack-modules-test-all-1
ip: 12.34.56.78 # <----- put here public IP attached to machine
---
kind: configuration/repository
title: "LambdaStack requirements repository"
name: default
specification:
description: "Local repository of binaries required to install LambdaStack"
download_done_flag_expire_minutes: 120
apache_lsrepo_path: "/var/www/html/lsrepo"
teardown:
disable_http_server: true
remove:
files: false
helm_charts: false
images: false
packages: false
provider: any
---
kind: configuration/postgresql
title: PostgreSQL
name: default
specification:
config_file:
parameter_groups:
- name: CONNECTIONS AND AUTHENTICATION
subgroups:
- name: Connection Settings
parameters:
- name: listen_addresses
value: "'*'"
comment: listen on all addresses
- name: Security and Authentication
parameters:
- name: ssl
value: 'off'
comment: to have the default value also on Ubuntu
- name: RESOURCE USAGE (except WAL)
subgroups:
- name: Kernel Resource Usage
parameters:
- name: shared_preload_libraries
value: AUTOCONFIGURED
comment: set by automation
- name: ERROR REPORTING AND LOGGING
subgroups:
- name: Where to Log
parameters:
- name: log_directory
value: "'/var/log/postgresql'"
comment: to have standard location for Filebeat and logrotate
- name: log_filename
value: "'postgresql.log'"
comment: to use logrotate with common configuration
- name: WRITE AHEAD LOG
subgroups:
- name: Settings
parameters:
- name: wal_level
value: replica
when: replication
- name: Archiving
parameters:
- name: archive_mode
value: 'on'
when: replication
- name: archive_command
value: "'test ! -f /dbbackup/{{ inventory_hostname }}/backup/%f &&\
\ gzip -c < %p > /dbbackup/{{ inventory_hostname }}/backup/%f'"
when: replication
- name: REPLICATION
subgroups:
- name: Sending Server(s)
parameters:
- name: max_wal_senders
value: 10
comment: maximum number of simultaneously running WAL sender processes
when: replication
- name: wal_keep_segments
value: 34
comment: number of WAL files held for standby servers
when: replication
extensions:
pgaudit:
enabled: false
shared_preload_libraries:
- pgaudit
config_file_parameters:
log_connections: 'off'
log_disconnections: 'off'
log_statement: 'none'
log_line_prefix: "'%m [%p] %q%u@%d,host=%h '"
pgaudit.log: "'write, function, role, ddl' # 'misc_set' is not supported for\
\ PG 10"
pgaudit.log_catalog: 'off # to reduce overhead of logging'
pgaudit.log_relation: 'on # separate log entry for each relation'
pgaudit.log_statement_once: 'off'
pgaudit.log_parameter: 'on'
pgbouncer:
enabled: false
replication:
enabled: false
replication_user_name: ls_repmgr
replication_user_password: PASSWORD_TO_CHANGE
privileged_user_name: ls_repmgr_admin
privileged_user_password: PASSWORD_TO_CHANGE
repmgr_database: ls_repmgr
shared_preload_libraries:
- repmgr
logrotate:
config: |-
/var/log/postgresql/postgresql*.log {
maxsize 10M
daily
rotate 6
copytruncate
# delaycompress is for Filebeat
delaycompress
compress
notifempty
missingok
su root root
nomail
# to have multiple unique filenames per day when dateext option is set
dateformat -%Y%m%dH%H
}
provider: any
---
kind: configuration/applications
title: "Kubernetes Applications Config"
name: default
specification:
applications:
- name: ignite-stateless
enabled: false
image_path: "lambdastack/ignite:2.9.1"
use_local_image_registry: false
namespace: ignite
service:
rest_nodeport: 32300
sql_nodeport: 32301
thinclients_nodeport: 32302
replicas: 1
enabled_plugins:
- ignite-kubernetes
- ignite-rest-http
- name: rabbitmq
enabled: false
image_path: rabbitmq:3.8.3
use_local_image_registry: false
service:
name: rabbitmq-cluster
port: 30672
management_port: 31672
replicas: 2
namespace: queue
rabbitmq:
plugins:
- rabbitmq_management
- rabbitmq_management_agent
policies:
- name: ha-policy2
pattern: ".*"
definitions:
ha-mode: all
custom_configurations:
- name: vm_memory_high_watermark.relative
value: 0.5
cluster:
- name: auth-service
enabled: false
image_path: jboss/keycloak:9.0.0
use_local_image_registry: false
service:
name: as-testauthdb
port: 30104
replicas: 2
namespace: namespace-for-auth
admin_user: auth-service-username
admin_password: PASSWORD_TO_CHANGE
database:
name: auth-database-name
user: auth-db-user
password: PASSWORD_TO_CHANGE
- name: pgpool
enabled: true
image:
path: bitnami/pgpool:4.1.1-debian-10-r29
debug: false
use_local_image_registry: false
namespace: postgres-pool
service:
name: pgpool
port: 5432
replicas: 3
pod_spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pgpool
topologyKey: kubernetes.io/hostname
nodeSelector: {}
tolerations: {}
resources:
limits:
memory: 176Mi
requests:
cpu: 250m
memory: 176Mi
pgpool:
env:
PGPOOL_BACKEND_NODES: autoconfigured
PGPOOL_POSTGRES_USERNAME: ls_pgpool_postgres_admin
PGPOOL_SR_CHECK_USER: ls_pgpool_sr_check
PGPOOL_ADMIN_USERNAME: ls_pgpool_admin
PGPOOL_ENABLE_LOAD_BALANCING: true
PGPOOL_MAX_POOL: 4
PGPOOL_POSTGRES_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_postgres_password
PGPOOL_SR_CHECK_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_sr_check_password
PGPOOL_ADMIN_PASSWORD_FILE: /opt/bitnami/pgpool/secrets/pgpool_admin_password
secrets:
pgpool_postgres_password: PASSWORD_TO_CHANGE
pgpool_sr_check_password: PASSWORD_TO_CHANGE
pgpool_admin_password: PASSWORD_TO_CHANGE
pgpool_conf_content_to_append: |
#------------------------------------------------------------------------------
# CUSTOM SETTINGS (appended by LambdaStack to override defaults)
#------------------------------------------------------------------------------
# num_init_children = 32
connection_life_time = 900
reserved_connections = 1
pool_hba_conf: autoconfigured
- name: pgbouncer
enabled: true
image_path: brainsam/pgbouncer:1.12
init_image_path: bitnami/pgpool:4.1.1-debian-10-r29
use_local_image_registry: false
namespace: postgres-pool
service:
name: pgbouncer
port: 5432
replicas: 2
resources:
requests:
cpu: 250m
memory: 128Mi
limits:
cpu: 500m
memory: 128Mi
pgbouncer:
env:
DB_HOST: pgpool.postgres-pool.svc.cluster.local
DB_LISTEN_PORT: 5432
LISTEN_ADDR: "*"
LISTEN_PORT: 5432
AUTH_FILE: "/etc/pgbouncer/auth/users.txt"
AUTH_TYPE: md5
MAX_CLIENT_CONN: 150
DEFAULT_POOL_SIZE: 25
RESERVE_POOL_SIZE: 25
POOL_MODE: transaction
provider: any
Run lambdastack tool to install LambdaStack:
lambdastack --auto-approve apply --file='/tmp/shared/ls.yml' --vault-password='secret'
This will install PostgreSQL on one of the machines and configure PgBouncer, Pgpool and additional services to manage database connections.
Please make sure you disable applications that you don't need. Also, you can enable standard LambdaStack services like Kafka or RabbitMQ, by increasing the number of virtual machines in the basic infrastructure config and assigning them to LambdaStack components you want to use.
If you would like to deploy custom resources into managed Kubernetes, then the standard kubeconfig yaml document can be found inside the shared state file (you should be able to use vendor tools as well to get it).
We highly recommend using the Ingress resource in Kubernetes to allow access to web applications inside the cluster. Since it's managed Kubernetes and fully supported by the cloud platform, the classic HAProxy load-balancer solution seems to be deprecated here.
Prometheus:
Grafana:
Kibana:
Azure:
AWS:
Prometheus is an open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach. For more information about the features, components and architecture of Prometheus please refer to the official documentation.
Prometheus role provides the following files with rules:
However, only common rules are enabled by default. To enable a specific rule you have to meet two conditions:
kind: configuration/prometheus
...
specification:
alert_rules:
common: true
container: false
kafka: false
node: false
postgresql: false
prometheus: false
For more information about how to setup Prometheus alerting rules, refer to the official website.
LambdaStack provides Alertmanager configuration via configuration manifest. To see default configuration please refer to default Prometheus configuration file.
To enable Alertmanager you have to modify configuration manifest:
Example:
...
specification:
...
alertmanager:
enable: true
alert_rules:
common: true
container: false
kafka: false
node: false
postgresql: false
prometheus: false
...
config:
route:
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: "test@domain.com"
For more details about Alertmanager configuration please refer to the official documentation
If you want to create scalable Prometheus setup you can use federation. Federation lets you scrape metrics from different Prometheus instances on one Prometheus instance.
In order to create a federation of Prometheus add to your configuration (for example to prometheus.yaml
file) of previously created Prometheus instance (on which you want to scrape data from other
Prometheus instances) to scrape_configs section:
scrape_configs:
- job_name: federate
metrics_path: /federate
params:
'match[]':
- '{job=~".+"}'
honor_labels: true
static_configs:
- targets:
- your-prometheus-endpoint1:9090
- your-prometheus-endpoint2:9090
- your-prometheus-endpoint3:9090
...
- your-prometheus-endpointn:9090
To check if Prometheus from which you want to scrape data is accessible, you can use a command like below (on Prometheus instance where you want to scrape data):
curl -G --data-urlencode 'match[]={job=~".+"}' your-prometheus-endpoint:9090/federate
If everything is configured properly and Prometheus instance from which you want to gather data is up and running, this should return the metrics from that instance.
Grafana is a multi-platform open source analytics and interactive visualization web application. It provides charts, graphs, and alerts for the web when connected to supported data sources. For more information about Grafana please refer to the official website.
Prior to setup Grafana, please setup in your configuration yaml new password and/or name for your admin user. If not, default "admin" user will be used with the default password "PASSWORD_TO_CHANGE".
kind: configuration/grafana
specification:
...
# Variables correspond to ones in grafana.ini configuration file
# Security
grafana_security:
admin_user: admin
admin_password: "YOUR_PASSWORD"
...
More information about Grafana security you can find at https://grafana.com/docs/grafana/latest/installation/configuration/#security address.
LambdaStack uses Grafana for monitoring data visualization. LambdaStack installation creates Prometheus datasource in Grafana, so the only additional step you have to do is to create your dashboard.
There are also many ready to take Grafana dashboards created by community - remember to check license before importing any of those dashboards.
You can create your own dashboards Grafana getting started page will help you with it. Knowledge of Prometheus will be really helpful when creating diagrams since it use PromQL to fetch data.
To import existing dashboard:
Dashboards/Manage in your Grafana web page.+Import button.Prometheus.ImportIn order to pull a dashboard from official Grafana website during lambdastack execution, you have to provide dashboard_id, revision_id and datasource in your configuration manifest.
Example:
kind: configuration/grafana
specification:
...
grafana_online_dashboards:
- dashboard_id: '4271'
revision_id: '3'
datasource: 'Prometheus'
Since v1.1.0 LambdaStack provides predefined Grafana dashboards. These dashboards are available in online and offline deployment modes.
To enable particular Grafana dashboard, refer to default Grafana configuration file, copy kind: configuration/grafana section to your configuration manifest and uncomment desired dashboards.
Example:
kind: configuration/grafana
specification:
...
grafana_external_dashboards:
# Kubernetes cluster monitoring (via Prometheus)
- dashboard_id: '315'
datasource: 'Prometheus'
# Node Exporter Server Metrics
- dashboard_id: '405'
datasource: 'Prometheus'
Note: The above link points to develop branch. Please choose the right branch that suits to LambdaStack version you are using.
There are many monitoring components deployed with LambdaStack that you can visualize data from. The knowledge which components are used is important when you look for appropriate dashboard on Grafana website or creating your own query to Prometheus.
List of monitoring components - so called exporters:
When dashboard creation or import succeeds you will see it on your dashboard list.
Note: For some dashboards, there is no data to visualize until there is traffic activity for the monitored component.
Kibana is an free and open frontend application that sits on top of the Elastic Stack, providing search and data visualization capabilities for data indexed in Elasticsearch. For more informations about Kibana please refer to the official website.
In order to start viewing and analyzing logs with Kibana, you first need to add an index pattern for Filebeat according to the following steps:
Management tabIndex Patternsfilebeat-*
Click next.@timestamp. This field represents the time that events occurred or were processed. You can choose not to have a time field, but you will not be able to narrow down your data by a time range.This filter pattern can now be used to query the Elasticsearch indices.
By default Kibana adjusts the UTC time in @timestamp to the browser's local timezone. This can be changed in Management > Advanced Settings > Timezone for date formatting.
To configure admin password for Kibana - Open Distro and Open Distro for Elasticsearch you need to follow the procedure below.
There are separate procedures for logging and opendistro-for-elasticsearch roles since most of the times for opendistro-for-elasticsearch, kibanaserver and logstash users are not required to be present.
By default LambdaStack removes users that are listed in demo_users_to_remove section of configuration/logging doc.
By default, kibanaserver user (needed by default LambdaStack installation of Kibana) and logstash (needed by default LambdaStack
installation of Filebeat) are not removed. If you want to perform configuration by LambdaStack, set kibanaserver_user_active to true
for kibanaserver user or logstash_user_active for logstash user. For logging role, those settings are already set to true by default.
We strongly advice to set different password for each user.
To change admin user's password, change value for admin_password key. For kibanaserver and logstash, change values
for kibanaserver_password and logstash_password keys respectively. Changes from logging role will be propagated to Kibana
and Filebeat configuration.
kind: configuration/logging
title: Logging Config
name: default
specification:
...
admin_password: YOUR_PASSWORD
kibanaserver_password: YOUR_PASSWORD
kibanaserver_user_active: true
logstash_password: YOUR_PASSWORD
logstash_user_active: true
demo_users_to_remove:
- kibanaro
- readall
- snapshotrestore
To set password of kibanaserver user, which is used by Kibana for communication with Open Distro Elasticsearch backend follow the procedure
described in Logging role.
To set password of logstash user, which is used by Filebeat for communication with Open Distro Elasticsearch backend follow the procedure described
in Logging role.
By default LambdaStack removes all demo users except admin user. Those users are listed in demo_users_to_remove section
of configuration/opendistro-for-elasticsearch doc. If you want to keep kibanaserver user (needed by default LambdaStack installation of Kibana),
you need to remove it from demo_users_to_remove list and set kibanaserver_user_active to true in order to change the default password.
We strongly advice to set different password for each user.
To change admin user's password, change value for admin_password key. For kibanaserver and logstash, change values for kibanaserver_password
and logstash_password keys respectively.
kind: configuration/opendistro-for-elasticsearch
title: Open Distro for Elasticsearch Config
name: default
specification:
...
admin_password: YOUR_PASSWORD
kibanaserver_password: YOUR_PASSWORD
kibanaserver_user_active: false
logstash_password: YOUR_PASSWORD
logstash_user_active: false
demo_users_to_remove:
- kibanaro
- readall
- snapshotrestore
- logstash
- kibanaserver
During upgrade LambdaStack takes kibanaserver (for Kibana) and logstash (for Filebeat) user passwords and re-applies them to upgraded configuration of Filebeat and Kibana. LambdaStack upgrade of Open Distro, Kibana or Filebeat will fail if kibanaserver or logstash usernames were changed in configuration of Kibana, Filebeat or Open Distro for Elasticsearch.
Setting up addtional monitoring on Azure for redundancy is good practice and might catch issues the LambdaStack monitoring might miss like:
More information about Azure monitoring and alerting you can find under links provided below:
https://docs.microsoft.com/en-us/azure/azure-monitor/overview
https://docs.microsoft.com/en-us/azure/monitoring-and-diagnostics/monitoring-overview-alerts
TODO
This guide describes steps you have to perform to patch RHEL and Ubuntu operating systems in a way to not to interrupt working LambdaStack components.
We provide a recommended way to patch your RHEL and Ubuntu operating systems. Before proceeding with patching the production environment we strongly recommend patching your test cluster first. This document will help you decide how you should patch your OS. This is not a step-by-step guide.
For LambdaStack >= v1.2 we recommend the following image (AMI):
RHEL-7.9_HVM-20210208-x86_64-0-Hourly2-GP2 (kernel 3.10.0-1160.15.2.el7.x86_64),ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server-20210907 (kernel 5.4.0-1056-aws).Note: For different supported OS versions this guide may be useful as well.
AWS provides Patch Manager that automates the process of patching managed instances.
Benefits:
This feature is available via:
For more information, refer to AWS Systems Manager User Guide.
For LambdaStack >= v1.2 we recommend the following image (urn):
RedHat:RHEL:7-LVM:7.9.2021051701 (kernel 3.10.0-1160.el7.x86_64),Canonical:UbuntuServer:18.04-LTS:18.04.202109130 (kernel 5.4.0-1058-azure).Note: For different supported OS versions this guide may be useful as well.
Azure has Update Management solution in Azure Automation. It gives you visibility into update compliance across Azure and other clouds, and on-premises. The feature allows you to create scheduled deployments that orchestrate the installation of updates within a defined maintenance window.
To manage updates that way please refer to official documentation.
The following commands can be executed in both clustered and non-clustered environments. In case of patching non-clustered environment, you have to schedule a maintenance window due to the required reboot after kernel patching.
Note: Some of the particular patches may also require a system reboot.
If your environment is clustered then hosts should be patched one by one. Before proceeding with the next host be sure that the patched host is up and all its components are running. For information how to check state of specific LambdaStack components, see here.
LambdaStack uses the repository role to provide all required packages. The role disables all existing repositories and provides a new one. After successful LambdaStack deployment, official repositories should be re-enabled and lambdastack-provided repository should be disabled.
Verify if lsrepo is disabled:
yum repolist lsrepo
Verify if repositories you want to use for upgrade are enabled:
yum repolist all
List installed security patches:
yum updateinfo list security installed
List available patches without installing them:
yum updateinfo list security available
Grab more details about available patches:
yum updateinfo info security available or specific patch: yum updateinfo info security <patch_name>
Install system security patches:
sudo yum update-minimal --sec-severity=critical,important --bugfix
Install all patches and updates, not only flagged as critical and important:
sudo yum update
You can also specify the exact bugfix you want to install or even which CVE vulnerability to patch, for example:
sudo yum update --cve CVE-2008-0947
Available options:
--advisory=ADVS, --advisories=ADVS
Include packages needed to fix the given advisory, in updates
--bzs=BZS Include packages needed to fix the given BZ, in updates
--cves=CVES Include packages needed to fix the given CVE, in updates
--sec-severity=SEVS, --secseverity=SEVS
Include security relevant packages matching the severity, in updates
Additional information Red Hat provides notifications about security flaws that affect its products in the form of security advisories. For more information, see here.
For automated security patches Ubuntu uses unattended-upgrade facility. By default it runs every day. To verify it on your system, execute:
dpkg --list unattended-upgrades
cat /etc/apt/apt.conf.d/20auto-upgrades | grep Unattended-Upgrade
For information how to change Unattended-Upgrade configuration, see here.
The following steps will allow you to perform an upgrade manually.
Update your local repository cache:
sudo apt update
Verify if lsrepo is disabled:
apt-cache policy | grep lsrepo
Verify if repositories you want to use for upgrade are enabled:
apt-cache policy
List available upgrades without installing them:
apt-get upgrade -s
List available security patches:
sudo unattended-upgrade -d --dry-run
Install system security patches:
sudo unattended-upgrade -d
Install all patches and updates with dependencies:
sudo apt-get dist-upgrade
Verify if your system requires a reboot after an upgrade (check if file exists):
test -e /var/run/reboot-required && echo reboot required || echo reboot not required
Additional information Canonical provides notifications about security flaws that affect its products in the form of security notices. For more information, see here.
Solutions are available to perform kernel patching without system reboot.
If you have a valid subscription for any of the above tools, we highly recommend using it to patch your systems.
LambdaStack supports Azure Files and Amazon EFS storage types to use as Kubernetes persistent volumes.
LambdaStack creates a storage account with "Standard" tier and locally-redundant storage ("LRS" redundancy option). This storage account contains a file share with the name "k8s".
With the following configuration it is possible to specify storage account name and "k8s" file share quota in GiB.
---
kind: infrastructure/storage-share
name: default
provider: azure
specification:
quota: 50
There are a few related K8s objects created such as PersistentVolume, PersistentVolumeClaim and "azure-secret" Secret
when specification.storage.enable is set to true. It is possible to control pv/pvc names and storage
capacity/request in GiB with the configuration below.
NOTE
It makes no sense to specify greater capacity than Azure file share allows using. In general these values should be the same.
---
kind: configuration/kubernetes-master
name: default
provider: azure
specification:
storage:
name: lambdastack-cluster-volume
enable: true
capacity: 50
It is possible to use Azure file shares created by your own. Check documentation for details. Created file shares may be used in different ways. There are appropriate configuration examples below.
NOTE
Before applying configuration, storage access secret should be created
As LambdaStack always creates a file share when provider: azure is used, in this case similar configuration can be used
even with specification.storage.enable set to false.
apiVersion: v1
kind: Pod
metadata:
name: azure1
spec:
containers:
- image: busybox
name: azure
command: [ "/bin/sh", "-c", "--" ]
args: [ "while true; do sleep 30; done;" ]
volumeMounts:
- name: azure
mountPath: /mnt/azure
volumes:
- name: azure
azureFile:
secretName: azure-secret
shareName: k8s
readOnly: false
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: lambdastack-cluster-volume
spec:
storageClassName: azurefile
capacity:
storage: 50Gi
accessModes:
- "ReadWriteMany"
azureFile:
secretName: azure-secret
shareName: k8s
readOnly: false
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: lambdastack-cluster-volume-claim
spec:
storageClassName: azurefile
volumeName: lambdastack-cluster-volume
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
---
apiVersion: v1
kind: Pod
metadata:
name: azure2
spec:
containers:
- image: busybox
name: azure
command: [ "/bin/sh", "-c", "--" ]
args: [ "while true; do sleep 30; done;" ]
volumeMounts:
- name: azure
mountPath: /mnt/azure
volumes:
- name: azure
persistentVolumeClaim:
claimName: lambdastack-cluster-volume-claim
Amazon EFS can be configured using following configuration.
---
kind: infrastructure/efs-storage
provider: aws
name: default
specification:
encrypted: true
performance_mode: generalPurpose
throughput_mode: bursting
#provisioned_throughput_in_mibps: # The throughput, measured in MiB/s, that you want to provision for the file system. Only applicable when throughput_mode set to provisioned
Configuration for AWS supports additional parameter specification.storage.path that allows specifying the path on EFS
to be accessed by pods. When specification.storage.enable is set to true, PersistentVolume and PersistentVolumeClaim
are created
---
kind: configuration/kubernetes-master
name: default
provider: aws
specification:
storage:
name: lambdastack-cluster-volume
path: /
enable: true
capacity: 50
If provider: aws is specified, EFS storage is always created and can be used with persistent volumes created by the
user. It is possible to create a separate EFS and use it. For more information check Kubernetes
NFS storage documentation. There is another way
to use EFS by Amazon EFS CSI driver but this approach
is not supported by LambdaStack's AWS provider.
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: lambdastack-cluster-volume
spec:
accessModes:
- ReadWriteMany
capacity:
storage: 100Gi
mountOptions:
- hard
- nfsvers=4.1
- rsize=1048576
- wsize=1048576
- timeo=600
- retrans=2
nfs:
path: /
server: fs-xxxxxxxx.efs.eu-west-1.amazonaws.com
storageClassName: defaultfs
volumeMode: Filesystem
There are 2 ways to get the image, build it locally yourself or pull it from the LambdaStack docker registry.
Shows the option of pushing the locally generated image to Docker Hub as well.
Install the following dependencies:
Open a terminal in the root directory of the LambdaStack source code and run (it should contain the /cli subdirectory. This also where the Dockerfile is located). There are two options below, the first option builds and applies a specific tag/version to the image and the second option builds and applies a specific tag/version plus applies a 'latest' tag in the event the user only wanted the latest version:
TAG=$(cat version)
docker build --file Dockerfile --tag lambdastack/lambdastack:${TAG} .
OR
TAG=$(cat version)
docker build --file Dockerfile --tag lambdastack/lambdastack:${TAG} --tag lambdastack/lambdastack:latest .
TAG=$(cat version)
docker push lambdastack/lambdastack:${TAG}
docker push lambdastack/lambdastack:latest
NOTE: This the default way. The latest version of LambdaStack will already be in the Docker Hub ready to be pulled down locally. If you built the image locally then it will already be in your local image so there is no need to pull it down - you can skip to doing a Docker Run like below.
TAG is the specific version tag given to the image. If you don't know the specific version then use the second option and it will grab the latest version.
docker pull lambdastack/lambdastack:TAG
OR
docker pull lambdastack/lambdastack:latest
Check here for the available tags.
To run the image:
docker run -it -v LOCAL_DIR:/shared --rm lambdastack/lambdastack:TAG
Where:
LOCAL_DIR should be replaced with the local path to the directory for LambdaStack input (SSH keys, data yaml files) and output (logs, build states),TAG should be replaced with an existing tag.Example: docker run -it -v $PWD:/shared --rm lambdastack/lambdastack:latest
The lambdastack docker image will mount to $PWD means present working directory so, change directory to where you want it to mount. It will expect any customized configs, SSH keys or data yaml files to be in that directory. The example above is for Linux based systems (including macs). See Windows method below.
Check here for the available tags.
Let LambdaStack run (it will take a while depending on the options you selected)!
Notes below are only here if you run into issues with a corporate proxy or something like that or if you want to do development and add cool new features to LambdaStack :).
For setting up the LambdaStack development environment please refer to this dedicated document here.
LambdaStack supports only DNS-1123 subdomain that must consist of lower case alphanumeric characters, '-' or '.', and must start and end with an alphanumeric character.
Watch out for the line endings conversion. By default, Git for Windows sets core.autocrlf=true. Mounting such files with Docker results in ^M end-of-line character in the config files.
Use: Checkout as-is, commit Unix-style (core.autocrlf=input) or Checkout as-is, commit as-is (core.autocrlf=false). Be sure to use a text editor that can work with Unix line endings (e.g. Notepad++).
Remember to allow Docker Desktop to mount drives in Settings -> Shared Drives
Escape your paths properly:
docker run -it -v C:\Users\USERNAME\git\LambdaStack:/LambdaStack --rm lambdastack-dev:
winpty docker run -it -v C:\\Users\\USERNAME\\git\\LambdaStack:/LambdaStack --rm lambdastack-dev
Mounting NTFS disk folders in a linux based image causes permission issues with SSH keys. When running either the development or deploy image:
Copy the certs on the image:
mkdir -p ~/.ssh/lambdastack-operations/
cp /lambdastack/core/ssh/id_rsa* ~/.ssh/lambdastack-operations/
Set the proper permission on the certs:
chmod 400 ~/.ssh/lambdastack-operations/id_rsa*
To run LambdaStack behind a proxy, environment variables need to be set.
When running a development container (upper and lowercase are needed because of an issue with the Ansible dependency):
export http_proxy="http://PROXY_SERVER:PORT"
export https_proxy="https://PROXY_SERVER:PORT"
export HTTP_PROXY="http://PROXY_SERVER:PORT"
export HTTPS_PROXY="https://PROXY_SERVER:PORT"
Or when running from a Docker image (upper and lowercase are needed because of an issue with the Ansible dependency):
docker run -it -v POSSIBLE_MOUNTS... -e HTTP_PROXY=http://PROXY_SERVER:PORT -e HTTPS_PROXY=http://PROXY_SERVER:PORT http_proxy=http://PROXY_SERVER:PORT -e https_proxy=http://PROXY_SERVER:PORT --rm IMAGE_NAME
In some cases it might be that a company uses custom CA certificates or CA bundles for providing secure connections. To use these with LambdaStack you can do the following:
Note that for the comments below the filenames of the certificate(s)/bundle do not matter, only the extensions. The certificate(s)/bundle need to be placed here before building the devcontainer.
crt extension.crt extension and also add the single bundle with the pem extension containing the same certificates. This is needed because not all tools inside the container accept the single bundle.If you are running LambdaStack from one of the prebuilt release containers you can do the following to install the certificate(s):
cp ./path/to/*.crt /usr/local/share/ca-certificates/
chmod 644 /usr/local/share/ca-certificates/*.crt
update-ca-certificates
If you plan to deploy on AWS you also need to add a separate configuration for Boto3 which can either be done by a config file or setting the AWS_CA_BUNDLE environment variable. More information about for Boto3 can be found here.
When installing a cluster, LambdaStack sets up its own internal repository for serving:
This ONLY applies to
airgappedenvironments (no Internet access environments - high secure areas)
This document will provide information about the repository lifecyle and how to deal with possible issues that might popup during that.
Below the lifecycle of the LambdaStack repository:
lsrepo and start HTTP server)Note: This will only cover online clusters
Downloading requirements is one of the most sensitive steps in deploying a new cluster because lots of resources are being downloaded from various sources.
When you see the following output from lambdastack, requirements are being downloaded:
INFO cli.engine.ansible.AnsibleCommand - TASK [repository : Run download-requirements script, this can take a long time
INFO cli.engine.ansible.AnsibleCommand - You can check progress on repository host with: journalctl -f -t download-requirements.sh] ***
As noted this process can take a long time depending on the connection and as downloading requirements is being done by a shell script, the Ansible process cannot return any realtime information.
To view the progress during the downloading (realtime output from the logs), one can SSH into the repository machine and run:
journalctl -f -t download-requirements.sh
If for some reason the download-requirements fails you can also always check the log afterwards on the repository machine here:
/tmp/ls-download-requirements/log
If for some reason the download requirement step fails and you want to restart, it might be a good idea to delete the following directory first:
/var/www/html/lsrepo
This directory holds all the files being downloaded and removing it makes sure that there are no corrupted or temporary files which might interfere with the restarted download process.
If you want to re-download the requirements but the process finished successfully before, you might need to remove the following file:
/tmp/ls-download-requirements/download-requirements-done.flag
When this file is present and it isn't older than defined amount of time (2 hours by default), it enforces skipping re-downloading requirements.
If during the component installation an issue will arise (e.g. network issue), it might be the case that the cluster machines are left in a state where step 5 of the repository lifecycle is not run. This might leave the machines with a broken repository setup making re-running lambdastack apply impossible as noted in issue #2324.
To restore the original repository setup on a machine, you can execute the following scripts:
# Re-enable system repositories
/tmp/ls-repository-setup-scripts/enable-system-repos.sh
# Disable lsrepo
/tmp/ls-repository-setup-scripts/disable-lsrepo-client.sh
An LambdaStack cluster has a number of components which log, collect and retain data. To make sure that these do not exceed the usable storage of the machines they running on, the following configurations are available.
TODO
TODO
There are two types of retention policies that can be configured at the broker or topic levels: based on time or size. LambdaStack defines the same default value for broker size retention policy as Kafka, -1, which means that no size limit is applied.
To define new log retention values following configuration can be used:
kind: configuration/kafka
title: "Kafka"
name: default
specification:
kafka_var:
partitions: 8
log_retention_hours: 168
log_retention_bytes: -1
Sets num.partitions parameter
Sets log.retention.hours parameter
Sets log.retention.bytes parameter
NOTE
Since this limit is enforced at the partition level, multiply it by the number of partitions to compute the topic retention in bytes.
TODO
TODO
TODO
TODO
This document describes the Security Groups layout which is used to deploy LambdaStack in AWS or Azure. You will find the default configuration here, as well as examples of adding own rules or changing existing ones.
By default LambdaStack platform is creating security groups required to handle communication by all components (like postgress/rabbitmq etc). As per defaults, LambdaStack creates a subnet per component and each subnet has its own of security group, with rules that allow communication between them. This enables the smooth communication between all components. Please check our security document too. Be aware, that whenever you want to add a new rule, you need to copy all default rules from mentioned above url. That this document is splited into two parts: AWS and Azure. The reason why we do that, is that there are diffrent values in AWS and AZure, when setting the security rules.
Sometimes, there is a need to set additional security rules for application which we're deploying in LambdaStack kubernetes cluster. Than, we need to stick into following rules:
Check bellow security diagram, which show how security groups are related to other components. This is example of AWS architecutre, but in Azure should be almost the same.

List of all security groups and related services in Azure are described here.
Rules description:
- name: "Name of the rule"
description: "Short rule description"
priority: "Priority (NUM), which describes which rules should be taken into conediration as first "
direction: "Inbound || Outbound" - which direction are you allowing rule"
access: "Allow|Deny - whenever we want to grant access or block"
protocol: "TCP || UDP" - which protocol should be used for connections"
source_port_range: "Source port ranges"
destination_port_range: "Destination port/s range"
source_address_prefix: "Source network address"
destination_address_prefix: "Destination network address"
Lets look into example on which, we are setting new rule name "nrpe-agent-port", with priority 250, which is allowing accesses from local network "10.1.4.0/24" into all hosts in our network on port 5666.
The rule:
- name: nrpe-agent-port
description: Allow access all hosts on port 5666 where nagios agent is running.
priority: 250
direction: Inbound
access: Allow
protocol: Tcp
source_port_range: "*"
destination_port_range: "5666"
source_address_prefix: "10.1.4.0/24"
destination_address_prefix: "0.0.0.0/0"
To deploy previously mentioned rule, we need to setup a complete YAML configuraiton file. Bellow example shows how this file should looks like. In this configuration we set simple setup of LambdaStack with 2nodes and 1 master vm in Azure.
kind: lambdastack-cluster
name: default
provider: azure
title: LambdaStack Cluster Config
build_path: # Dynamically built
specification:
name: azure
prefix: azure
admin_user:
name: operations
key_path: id_rsa
path: # Dynamically built
cloud:
region: East US
subscription_name: PUT_SUBSCRIPTION_NAME_HERE
use_public_ips: true
use_service_principal: true
network:
use_network_security_groups: true
components:
kafka:
count: 0
kubernetes_master:
count: 1
machine: kubernetes-master-machine
configuration: default
kubernetes_node:
count: 2
load_balancer:
count: 0
logging:
count: 0
monitoring:
count: 0
postgresql:
count: 0
rabbitmq:
count: 0
---
kind: infrastructure/virtual-machine
title: "Virtual Machine Infra"
provider: azure
name: kubernetes-master-machine
specification:
size: Standard_DS3_v2
security:
rules:
- name: ssh
description: Allow SSH
priority: 100
direction: Inbound
access: Allow
protocol: Tcp
source_port_range: "*"
destination_port_range: "22"
source_address_prefix: "0.0.0.0/0"
destination_address_prefix: "0.0.0.0/0"
- name: out
description: Allow out
priority: 101
direction: Outbound
access: Allow
protocol: "*"
source_port_range: "*"
destination_port_range: "0"
source_address_prefix: "0.0.0.0/0"
destination_address_prefix: "0.0.0.0/0"
- name: node_exporter
description: Allow node_exporter traffic
priority: 200
direction: Inbound
access: Allow
protocol: Tcp
source_port_range: "*"
destination_port_range: "9100"
source_address_prefix: "10.1.0.0/20"
destination_address_prefix: "0.0.0.0/0"
- name: subnet-traffic
description: Allow subnet traffic
priority: 201
direction: Inbound
access: Allow
protocol: "*"
source_port_range: "*"
destination_from_port: 0
destination_to_port: 65536
destination_port_range: "0"
source_address_prefix: "10.1.1.0/24"
destination_address_prefix: "0.0.0.0/0"
- name: monitoring-traffic
description: Allow monitoring subnet traffic
priority: 203
direction: Inbound
access: Allow
protocol: "*"
source_port_range: "*"
destination_from_port: 0
destination_to_port: 65536
destination_port_range: "0"
source_address_prefix: "10.1.4.0/24"
destination_address_prefix: "0.0.0.0/0"
- name: node-subnet-traffic
description: Allow node subnet traffic
priority: 204
direction: Inbound
access: Allow
protocol: "*"
source_port_range: "*"
destination_from_port: 0
destination_to_port: 65536
destination_port_range: "0"
source_address_prefix: "10.1.2.0/24"
destination_address_prefix: "0.0.0.0/0"
- name: package_repository
description: Allow package repository traffic
priority: 205
direction: Inbound
access: Allow
protocol: Tcp
source_port_range: "*"
destination_port_range: "80"
source_address_prefix: "10.1.0.0/20"
destination_address_prefix: "0.0.0.0/0"
- name: image_repository
description: Allow image repository traffic
priority: 206
direction: Inbound
access: Allow
protocol: Tcp
source_port_range: "*"
destination_port_range: "5000"
source_address_prefix: "10.1.0.0/20"
destination_address_prefix: "0.0.0.0/0"
# Add NRPE AGENT RULE
- name: nrpe-agent-port
description: Allow access all hosts on port 5666 where nagios agent is running.
priority: 250
direction: Inbound
access: Allow
protocol: Tcp
source_port_range: "*"
destination_port_range: "5666"
source_address_prefix: "10.1.4.0/24"
estination_address_prefix: "0.0.0.0/0"
List of all security groups and related services in AWS are described here.
Rules description:
- name: "Name of the rule"
description: "Short rule description"
direction: "Inbound || Egress" - which direction are you allowing rule"
protocol: "TCP || UDP" - which protocol should be used for connections"
destination_port_range: "Destination port/s range"
source_address_prefix: "Source network address"
destination_address_prefix: "Destination network address"
Lets look into example on which, we are setting new rule name "nrpe-agent-port", which is allowing accesses from local network "10.1.4.0/24" into all hosts in our network on port 5666.
The rule:
- name: nrpe-agent-port
description: Allow access all hosts on port 5666 where nagios agent is running.
direction: Inbound
protocol: Tcp
destination_port_range: "5666"
source_address_prefix: "10.1.4.0/24"
destination_address_prefix: "0.0.0.0/0"
Please check bellow example, how to setup basic LambdaStack cluster in AWS with 1 master, 2 nodes, mandatory repository machine, and open accesses to all hosts on port 5666 from monitoring network.
kind: lambdastack-cluster
name: default
provider: aws
build_path: # Dynamically built
specification:
admin_user:
name: ubuntu
key_path: id_rsa
path: # Dynamically built
cloud:
region: eu-central-1
credentials:
key: YOUR_AWS_KEY
secret: YOUR_AWS_SECRET
use_public_ips: true
components:
repository:
count: 1
machine: repository-machine
configuration: default
subnets:
- availability_zone: eu-central-1a
address_pool: 10.1.11.0/24
kubernetes_master:
count: 1
machine: kubernetes-master-machine
configuration: default
subnets:
- availability_zone: eu-central-1a
address_pool: 10.1.1.0/24
- availability_zone: eu-central-1b
address_pool: 10.1.2.0/24
kubernetes_node:
count: 2
machine: kubernetes-node-machine
configuration: default
subnets:
- availability_zone: eu-central-1a
address_pool: 10.1.1.0/24
- availability_zone: eu-central-1b
address_pool: 10.1.2.0/24
logging:
count: 0
monitoring:
count: 0
kafka:
count: 0
postgresql:
count: 0
load_balancer:
count: 0
rabbitmq:
count: 0
ignite:
count: 0
opendistro_for_elasticsearch:
count: 0
single_machine:
count: 0
name: testing
prefix: 'aws-machine'
title: LambdaStack Cluster Config
---
kind: infrastructure/virtual-machine
title: "Virtual Machine Infra"
provider: aws
name: kubernetes-master-machine
specification:
size: t3.medium
authorized_to_efs: true
mount_efs: true
security:
rules:
- name: ssh
description: Allow ssh traffic
direction: Inbound
protocol: Tcp
destination_port_range: "22"
source_address_prefix: "0.0.0.0/0"
destination_address_prefix: "0.0.0.0/0"
- name: node_exporter
description: Allow node_exporter traffic
direction: Inbound
protocol: Tcp
destination_port_range: "9100"
source_address_prefix: "10.1.0.0/20"
destination_address_prefix: "0.0.0.0/0"
- name: subnet-traffic
description: Allow master subnet traffic
direction: Inbound
protocol: ALL
destination_port_range: "0"
source_address_prefix: "10.1.1.0/24"
destination_address_prefix: "0.0.0.0/0"
- name: monitoring-traffic
description: Allow monitoring subnet traffic
direction: Inbound
protocol: ALL
destination_port_range: "0"
source_address_prefix: "10.1.4.0/24"
destination_address_prefix: "0.0.0.0/0"
- name: node-subnet-traffic
description: Allow node subnet traffic
direction: Inbound
protocol: ALL
destination_port_range: "0"
source_address_prefix: "10.1.2.0/24"
destination_address_prefix: "0.0.0.0/0"
- name: out
description: Allow out
direction: Egress
protocol: "all"
destination_port_range: "0"
source_address_prefix: "0.0.0.0/0"
destination_address_prefix: "0.0.0.0/0"
# New Rule
- name: nrpe-agent-port
description: Allow access all hosts on port 5666 where nagios agent is running.
direction: Inbound
protocol: Tcp
destination_port_range: "5666"
source_address_prefix: "10.1.4.0/24"
destination_address_prefix: "0.0.0.0/0"
To enable/disable LambdaStack service user you can use tool from our repository. You can find this in directory tools/service_user_disable_enable under name service-user-disable-enable.yml.
To use this you need to have Ansible installed on machine from which you want to execute this.
To disable user you need to run command:
ansible-playbook -i inventory --extra-vars "operation=disable name=your_service_user_name" service-user-disable-enable.yml
To enable user you need to run command:
ansible-playbook -i inventory --extra-vars "operation=enable name=your_service_user_name" service-user-disable-enable.yml
To add/remove users you need to provide additional section to kind: lambdastack-cluster configuration.
You need to add specification.users in the format similar to example that you can find below:
kind: lambdastack-cluster
name: pg-aws-deb
provider: aws
build_path: '' # Dynamically built
specification:
...
users:
- name: user01 # name of the user
sudo: true # does user have sudo priviledge, not defined will set to false
state: present # user will be added if not exist
public_key: "ssh-rsa ..." # public key to add to .ssh/authorized_keys
- name: user02
state: absent # user will deleted if exists
public_key: "ssh-rsa ..."
- name: user03
state: present
public_key: "ssh-rsa ..."
...
TODO
Right now LambdaStack supports only self-signed certificates generated and signed by CA self-sign certificate. If you want to provide your own certificates you need to configure Kafka manually according to Kafka documentation.
To use LambdaStack automation and self-signed certificates you need to provide your own configuration for kafka role and enable TLS/SSL as this is disabled by default.
To enable TLS/SSL communication in Kafka you can provide your own
configuration of Kafka by adding it to your LambdaStack configuration file
and set the enabled flag to true in the security/ssl section.
If in the ssl section you will also set the parameter client_auth parameter as required,
you have to also provide configuration of authorization and authentication
as this setting enforces checking identity. This option is by default set as
required. Values requested and none don't require such setup.
When TLS/SSL is turned on then all communication to Kafka is encrypted and no other option is enabled. If you need different configuration, you need to configure Kafka manually.
When CA certificate and key is created on server it is also downloaded to host from
which LambdaStack was executed. By default LambdaStack downloads this package to build output
folder to ansible/kafka_certs directory. You can also change this path in LambdaStack configuration.
Sample configuration for Kafka with enabled TLS/SSL:
kind: configuration/kafka
title: "Kafka"
name: default
specification:
...
security:
ssl:
enabled: True
port: 9093 # port on which Kafka will listen for encrypted communication
server:
local_cert_download_path: kafka-certs # path where generated key and certificate will be downloaded
keystore_location: /var/private/ssl/kafka.server.keystore.jks # location of keystore on servers
truststore_location: /var/private/ssl/kafka.server.truststore.jks # location of truststore on servers
cert_validity: 365 # period of time when certificates are valid
passwords: # in this section you can define passwords to keystore, truststore and key
keystore: PasswordToChange
truststore: PasswordToChange
key: PasswordToChange
endpoint_identification_algorithm: HTTPS # this parameter enforces validating of hostname in certificate
client_auth: required # authentication mode for Kafka - options are: none (no authentication), requested (optional authentication), required (enforce authentication, you need to setup also authentication and authorization then)
inter_broker_protocol: SSL # must be set to SSL if TLS/SSL is enabled
...
To configure Kafka authentication with TLS/SSL, first you need to configure ssl section.
Then you need to add authentication section with enabled flag set to true and set authentication_method
as certificates. Setting authentication_method as sasl is not described right now in this document.
kind: configuration/kafka
title: "Kafka"
name: default
build_path: '' # Dynamically built
specification:
...
security:
...
authentication:
enabled: True
authentication_method: certificates
...
To configure Kafka authorization with TLS/SSL, first you need to configure ssl and authentication sections.
If authentication is disabled, then authorization will be disabled as well.
To enable authorization, you need to provide authorization section and set enabled flag to True.
For authorization you can also provide different than default authorizer_class_name.
By default kafka.security.auth.SimpleAclAuthorizer is used.
If allow_everyone_if_no_acl_found parameter is set to False, Kafka will prevent accessing resources everyone
except super users and users having permissions granted to access topic.
You can also provide super users that will be added to Kafka configuration. To do this you need to provide list of users,
like in the example below, and generate certificate on your own only with CN that matches position that can be found in list
(do not set OU, DC or any other of parameters). Then the certificate needs to be signed by CA root certificate for Kafka.
CA root certificate will be downloaded automatically by LambdaStack to location set in ssl.server.local_cert_download_path or can be found on first Kafka host in ssl.server.keystore_location directory. To access the certificate key, you need root priviledges.
kind: configuration/kafka
title: "Kafka"
name: default
build_path: '' # Dynamically built
specification:
...
security:
...
authorization:
enabled: True
authorizer_class_name: kafka.security.auth.SimpleAclAuthorizer
allow_everyone_if_no_acl_found: False
super_users:
- tester01
- tester02
...
Automatic encryption of storage on Azure is not yet supported by LambdaStack. Guides to encrypt manually can be found:
To configure RabbitMQ TLS support in LambdaStack you need to set custom_configurations in the configuration file and
manually create certificate with common CA according to documentation on your RabbitMQ machines:
https://www.rabbitmq.com/ssl.html#manual-certificate-generation
or:
https://www.rabbitmq.com/ssl.html#automated-certificate-generation
If stop_service parameter in configuration/rabbitmq is set to true,
then RabbitMQ will be installed and stopped to allow manual actions
that are required to copy or generate TLS certificates.
NOTE
To complete installation it's required to execute lambdastack apply the second time
with stop_service set to false
There is custom_configurations setting in LambdaStack that extends RabbitMQ configuration
with the custom one. Also, it can be used to perform TLS configuration of RabbitMQ.
To customize RabbitMQ configuration you need to pass a list of parameters in format:
-name: rabbitmq.configuration.parameter value: rabbitmq.configuration.value
These settings are mapping to RabbitMQ TLS parameters configuration from documentation that you can find below the link: https://www.rabbitmq.com/ssl.html
Below you can find example of TLS/SSL configuration.
kind: configuration/rabbitmq
title: "RabbitMQ"
name: default
build_path: '' # Dynamically built
specification:
...
custom_configurations:
- name: listeners.tcp # option that disables non-TLS/SSL support
value: none
- name: listeners.ssl.default # port on which TLS/SSL RabbitMQ will be listening for connections
value: 5671
- name: ssl_options.cacertfile # file with certificate of CA which should sign all certificates
value: /var/private/ssl/ca/ca_certificate.pem
- name: ssl_options.certfile # file with certificate of the server that should be signed by CA
value: /var/private/ssl/server/server_certificate.pem
- name: ssl_options.keyfile # file with key to the certificate of the server
value: /var/private/ssl/server/private_key.pem
- name: ssl_options.password # password to key protecting server certificate
value: PasswordToChange
- name: ssl_options.verify # setting of peer verification
value: verify_peer
- name: ssl_options.fail_if_no_peer_cert # parameter that configure behaviour if peer cannot present a certificate
value: "false"
...
Please be careful about boolean values as they need to be double quoted and written in lowercase form. Otherwise RabbitMQ startup will fail.
Encryption at rest for EC2 root volumes is turned on by default. To change this one can modify the encrypted flag for the root disk inside a infrastructure/virtual-machine document:
...
disks:
root:
volume_type: gp2
volume_size: 30
delete_on_termination: true
encrypted: true
...
Encryption at rest for additional EC2 volumes is turned on by default. To change this one can modify the encrypted flag for each additional_disks inside a infrastructure/virtual-machine document:
...
disks:
root:
...
additional_disks:
- device_name: "/dev/sdb"
volume_type: gp2
volume_size: 60
delete_on_termination: true
encrypted: true
...
Encryption at rest for EFS storage is turned on by default. To change this one can modify the encrypted flag inside the infrastructure/efs-storage document:
kind: infrastructure/efs-storage
title: "Elastic File System Config"
provider: aws
name: default
build_path: '' # Dynamically built
specification:
encrypted: true
...
Additional information can be found here.
Prerequisites: LambdaStack Kubernetes cluster
SSH into the Kubernetes master.
Run echo -n 'admin' > ./username.txt, echo -n 'VeryStrongPassword!!1' > ./password.txt and kubectl create secret generic mysecret --from-file=./username.txt --from-file=./password.txt
Copy over secrets-sample.yaml file from the example folder and run it with kubectl apply -f secrets-sample.yaml
Run kubectl get pods, copy the name of one of the ubuntu pods and run kubectl exec -it POD_NAME -- /bin/bash with it.
In the pods bash run printenv | grep SECRET - Kubernetes secret created in point 2 was attached to pods during creation (take a look at secrets-sample.yaml) and are availiable inside of them as an environmental variables.
Register you application. Go to Azure portal to Azure Active Directory => App registrations tab.
Click button New application registration fill the data and confirm.
Deploy app from examples/dotnet/LambdaStack.SampleApps/LambdaStack.SampleApps.AuthService.
This is a test service for verification Azure AD authentication of registered app. (How to deploy app)
Create secret key for your app settings => keys. Remember to copy value of key after creation.
Try to authenticate (e.g. using postman) calling service api <service-url>/api/auth/ with following Body application/json type parameters :
{
"TenantId": "<tenant-id>",
"ClientId": "<client-id>",
"Resource": "https://graph.windows.net/",
"ClientSecret": "<client-secret>"
}
TenantId - Directory ID, which you find in Azure active Directory => Properties tab.
ClientId - Application ID, which you find in details of previously registered app Azure Active Directory => App registrations => your app
Resource - https://graph.windows.net is the service root of Azure AD Graph API. The Azure Active Directory (AD) Graph API provides programmatic access to Azure AD through OData REST API endpoints. You can construct your own Graph API URL. (How to construct a Graph API URL)
ClientSecret - Created secret key from 4. point.
The service should return Access Token.
LambdaStack encrypts Kubernetes artifacts (access tokens) stored in LambdaStack build directory. In order to achieve it, user is asked for password which will be used for encryption and decryption of artifacts. Remember to enter the same password for the same cluster - if password will not be the same, lambdastack will not be able to decrypt secrets.
Standard way of executing lambdastack has not been changed:
lambdastack apply -f demo.yaml
But you will be asked to enter a password:
Provide password to encrypt vault:
When running lambdastack from CI pipeline you can use new parameter for lambdastack:
lambdastack apply -f build/demo/demo.yaml --vault-password MYPWD
For security reasons, the access to the admin credentials is limited to the root user. To make a non-root user the cluster administrator, run these commands (as the non-root user):
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
See more options in Troubleshooting
In LambdaStack beside storing secrets in Kubernetes secrets there is also a possibility of using secrets stored in Vault from Hashicorp. This can provide much more sophisticated solution for using secrets and also higher level of security than standard Kubernetes secrets implementation. Also LambdaStack provides transparent method to access Hashicorp Vault secrets with applications running on Kubernetes. You can read in the more about it in How to turn on Hashicorp Vault integration with k8s section. In the future we want also to provide additional features that right now can be configured manually according to Hashicorp Vault documentation.
At the moment only installation on Kubernetes Control Plane is supported, but we are also planning separate installation with no other components. Also at this moment we are not providing clustered option for Vault deployment, but this will be part of the future releases. For multi-master (HA) Kubernetes, Vault is installed only on the first master defined in Ansible inventory.
Below you can find sample configuration for Vault with description of all options.
kind: configuration/vault
title: Vault Config
name: default
specification:
vault_enabled: true # enable Vault install
vault_system_user: vault # user name under which Vault service will be running
vault_system_group: vault # group name under which Vault service will be running
enable_vault_audit_logs: false # turn on audit logs that can be found at /opt/vault/logs/vault_audit.log
enable_vault_ui: false # enable Vault UI, shouldn't be used at production
vault_script_autounseal: true # enable automatic unseal vault at the start of the service, shouldn't be used at production
vault_script_autoconfiguration: true # enable automatic configuration of Hashicorp Vault. It sets the UNSEAL_VAULT variable in script.config
...
app_secret_path: devwebapp # application specific path where application secrets will be mounted
revoke_root_token: false # not implemented yet (more about in section Root token revocation)
secret_mount_path: secret # start of the path that where secrets will be mounted
vault_token_cleanup: true # should configuration script clean token
vault_install_dir: /opt/vault # directory where vault will be installed
vault_log_level: info # logging level that will be set for Vault service
override_existing_vault_users: false # should user from vault_users ovverride existing user and generate new password
vault_users: # users that will be created with vault
- name: admin # name of the user that will be created in Vault
policy: admin # name of the policy that will be assigned to user (descrption bellow)
- name: provisioner
policy: provisioner
vault_helm_chart_values: # helm chart values overwriting the default package (to be able to use internal registry for offline purposes)
injector:
externalVaultAddr: https://your-external-address:8200 # external vault address (only if you want to setup address to provide full name to use with signed certificate) [IMPORTANT: switch https->http if tls_disable parameter is set to true]
image:
repository: "{{ image_registry_address }}/hashicorp/vault-k8s" # docker image used by vault injector in kubernetes
agentImage:
repository: "{{ image_registry_address }}/vault" # docker image used by vault injector in kubernetes
server:
image:
repository: "{{ image_registry_address }}/vault" # docker image used by vault injector in kubernetes
# TLS part
tls_disable: false # enable TLS support, should be used always in production
certificate_name: fullchain.pem # certificate file name
private_key_name: privkey.pem # private key file name for certificate
vault_tls_valid_days: 365 # certificate valid time in days
selfsigned_certificate: # selfsigned certificate information
country: US # selfexplanatory
state: state # selfexplanatory
city: city # selfexplanatory
company: company # selfexplanatory
common_name: "*" # selfexplanatory
More information about configuration of Vault in LambdaStack and some guidance how to start working with Vault with LambdaStack you can find below.
To get more familiarity with Vault usage you can reffer to official getting started guide.
To create user by LambdaStack please provide list of users with name of policy that should be assigned to user. You can use predefined policy delivered by LambdaStack, default Vault policies or your own policy. Remember that if you have written your own policy it must exist before user creation.
Password for user will be generated automatically and can be found in directory /opt/vault in files matching
tokens-*.csv pattern. If user password will be generated or changed you will see corresponding line in csv file with
username, policy and password. If password won't be updated you will see ALREADY_EXISTS in password place.
Vault policies are used to define Role-Based Access Control that can be assigned to clients, applications and other components that are using Vault. You can find more information about policies here.
LambdaStack besides two already included in vault policies (root and default) provides two additional predefined policies:
By design Hashicorp Vault starts in sealed mode. It means that Vault data is encrypted and operator needs to provide unsealing key to be able to access data.
Vault can be unsealed manually using command:
vault operator unseal
and passing three unseal keys from /opt/vault/init.txt file. Number of keys will be defined from the level of LambdaStack configuration in the future releases. Right now we are using default Hashicorp Vault settings.
For development purposes you can also use vault_script_autounseal option in LambdaStack configuration.
More information about unseal you can find in documentation for CLI and about concepts here.
If you are using option with manual unseal or want to perform manual configuration you can run script later on manually from the command line:
/opt/vault/bin/configure-vault.sh
-c /opt/vault/script.config
-a ip_address_of_vault
-p http | https
-v helm_chart_values_be_override
Values for script configuration in script.config are automatically generated by LambdaStack and can be later on used to perform configuration.
To log into Vault with token you just need to pass token. You can do this using command:
vault login
Only root token has no expiration date, so be aware that all other tokens can expire. To avoid such situations you need to renew the token. You can assign policy to token to define access.
More information about login with tokens you can find here and about tokens here.
Other option to log into Vault is to use user/password pair. This method doesn't have disadvantage of login each time with different token after expire. To login with user/password pair you need to have userpass method and login with command:
vault login -method=userpass username=your-username
More information about login with tokens you can find here and about userpass authentication here.
Vault provide option to use token helper. By default Vault is creating a file .vault-token in home directory of user
running command vault login, which let to user perform automatically commands without providing a token. This token
will be removed by default after LambdaStack configuration, but this can be changed using vault_token_cleanup flag.
More information about token helper you can find here.
In order to create your own policy using CLI please refer to CLI documentation and documentation.
In order to create your own user with user and password login please refer to documentation. If you have configured any user using LambdaStack authentication userpass will be enabled, if not needs to be enabled manually.
In production is a good practice to revoke root token. This option is not implemented yet, by LambdaStack, but will be implemented in the future releases.
Be aware that after revoking root token you won't be able to use configuration script without generating new token
and replace old token with the new one in /opt/vault/init.txt (field Initial Root Token). For new root token generation
please refer to documentation accessible here.
By default tls_disable is set to false which means that certificates are used by vault. There are 2 ways of certificate configuration:
Vault selfsigned certificates are generated automatically during vault setup if no custom certificates are present in dedicated location.
In dedicated location user can add certificate (and private key). File names are important and have to be the same as provided in configuration and .pem file extensions are required.
Dedicated location of custom certificates:
core/src/lambdastack/data/common/ansible/playbooks/roles/vault/files/tls-certs
Certificate files names configuration:
kind: configuration/vault
title: Vault Config
name: default
specification:
...
certificate_name: fullchain.pem # certificate file name
private_key_name: privkey.pem # private key file name for certificate
...
In LambdaStack we have performed a lot of things to improve Vault security, e.g.:
However if you want to provide more security please refer to this guide.
To perform troubleshooting of vault and find the root cause of the problem please enable audit logs and set vault_log_level to debug. Please be aware that audit logs can contain sensitive data.
In LambdaStack there is also an option to configure automatically integration with Kubernetes. This is achieved with applying additional settings to Vault configuration. Sample config with description you can find below.
kind: configuration/vault
title: Vault Config
name: default
specification:
vault_enabled: true
...
vault_script_autounseal: true
vault_script_autoconfiguration: true
...
kubernetes_integration: true # enable setup kubernetes integration on vault side
kubernetes_configuration: true # enable setup kubernetes integration on vault side
enable_vault_kubernetes_authentication: true # enable kubernetes authentication on vault side
kubernetes_namespace: default # namespace where your application will be deployed
...
Vault and Kubernetes integration in LambdaStack relies on vault-k8s tool. Thit tool enables sidecar injection of secret into pod with usage of Kubernetes Mutating Admission Webhook. This is transparent for your application and you do not need to perform any binding to Hashicorp libaries to use secret stored in Vault.
You can also configure Vault manually on your own enabling by LambdaStack only options that are necessary for you.
More about Kubernetes sidecar integration you can find at the link.
To work with sidecar integration with Vault you need to enable Kubernetes authentication. Without that sidecar won't be able to access secret stored in Vault.
If you don't want to use sidecar integration, but you want to access automatically Vault secrets you can use Kubernetes authentication. To find more information about capabilities of Kubernetes authentication please refer to documentation.
In LambdaStack you can use integration of key value secrets to inject them into container. To do this you need to create them using vault CLI.
You can do this running command similar to sample below:
vault kv put secret/yourpath/to/secret username='some_user' password='some_password'
LambdaStack as backend for Vault secrets is using kv secrets engine. More information about kv secrets engine you can find here.
In LambdaStack we are creating additional Kubernetes objects to inject secrets automatically using sidecar. Those objects to have access to your application pods needs to be deployed in the same namespace.
Below you can find sample of deployment configuration excerpt with annotations. For this moment vault.hashicorp.com/role
cannot be changed, but this will change in future release.
template:
metadata:
labels:
app: yourapp
annotations:
vault.hashicorp.com/agent-inject: "true"
vault.hashicorp.com/role: "devweb-app"
vault.hashicorp.com/agent-inject-secret-credentials.txt: "secret/data/yourpath/to/secret"
vault.hashicorp.com/tls-skip-verify: "true"
vault.hashicorp.com/tls-skip-verify
If true, configures the Vault Agent to skip verification of Vault's TLS certificate.
It's mandatory for selfsigned certificates and not recommended to set this value to true in a production environment.
More information about annotations you can find here.
From lscli 0.4.2 and up the CLI has the ability to perform upgrades on certain components on a cluster. The components it currently can upgrade and will add are:
NOTE
There is an assertion to check whether K8s version is supported before running upgrade.
The component upgrade takes the existing Ansible build output and based on that performs the upgrade of the currently
supported components. If you need to re-apply your entire LambdaStack cluster a manual adjustment of the input yaml is
needed to the latest specification which then should be applied with lambdastack apply.... Please
see Run apply after upgrade chapter for more details.
Note about upgrade from pre-0.8 LambdaStack:
If you need to upgrade a cluster deployed with lambdastack in version earlier than 0.8, you should make sure that you've got enough disk space on master (which
is used as repository) host. If you didn't extend OS disk on master during deployment process, you probably have only
32 GB disk which is not enough to properly upgrade cluster (we recommend at least 64 GB). Before you run upgrade, please extend
OS disk on master machine according to cloud provider
documentation: AWS
, Azure.
If you use logging-machine(s) already in your cluster, it's necessary to scale up those machines before running upgrade to ensure you've got enough resources to run ELK stack in newer version. We recommend to use at least DS2_v2 Azure size (2 CPUs, 7 GB RAM) machine, or its equivalent on AWS and on-prem installations. It's very related to amount of data you'll store inside. Please see logging documentation for more details.
Your airgapped existing cluster should meet the following requirements:
Start the upgrade with:
lambdastack upgrade -b /buildoutput/
This will backup and upgrade the Ansible inventory in the provided build folder /buildoutput/ which will be used to
perform the upgrade of the components.
Your airgapped existing cluster should meet the following requirements:
NOTE
Before running lambdastack, check the Prerequisites
To upgrade the cluster components run the following steps:
First we need to get the tooling to prepare the requirements for the upgrade. On the provisioning machine run:
lambdastack prepare --os OS
Where OS should be centos-7, redhat-7, ubuntu-18.04. This will create a directory called prepare_scripts with the needed files inside.
The scripts in the prepare_scripts will be used to download all requirements. To do that, copy the prepare_scripts
folder over to the requirements machine and run the following command:
download-requirements.sh /requirementsoutput/
This will start downloading all requirements and put them in the /requirementsoutput/ folder. Once run successfully
the /requirementsoutput/ needs to be copied to the provisioning machine to be used later on.
Finally, start the upgrade with:
lambdastack upgrade -b /buildoutput/ --offline-requirements /requirementsoutput/
This will backup and upgrade the Ansible inventory in the provided build folder /buildoutput/ which will be used to
perform the upgrade of the components. The --offline-requirements flag tells LambdaStack where to find the folder with
requirements (/requirementsoutput/) prepared in steps 1 and 2 which is needed for the offline upgrade.
The lambdastack upgrade command has additional flags:
--wait-for-pods. When this flag is added, the Kubernetes upgrade will wait until all pods are in the ready state
before proceeding. This can be useful when a zero downtime upgrade is required. Note: that this can also cause the
upgrade to hang indefinitely.
--upgrade-components. Specify comma separated component names, so the upgrade procedure will only process specific
ones. List cannot be empty, otherwise execution will fail. By default, upgrade will process all components if this
parameter is not provided
Example:
lambdastack upgrade -b /buildoutput/ --upgrade-components "kafka,filebeat"
Currently, LambdaStack does not fully support apply after upgrade. There is a possibility to re-apply configuration from
newer version of LambdaStack but this needs some manual work from Administrator. Re-apply on already upgraded cluster needs
to be called with --no-infra option to skip Terraform part of configuration. If apply after upgrade is run
with --no-infra, the used system images from the older LambdaStack version are preserved to prevent the destruction of
the VMs. If you plan modify any infrastructure unit (e.g., add Kubernetes Node) you need to create machine by yourself
and attach it into configuration yaml. While running lambdastack apply... on already upgraded cluster you should use yaml
config files generated in newer version of LambdaStack and apply changes you had in older one. If the cluster is upgraded
to version 0.8 or newer you need also add additional feature mapping for repository role as shown on example below:
---
kind: lambdastack-cluster
name: clustername
provider: azure
build_path: # Dynamically built
specification:
admin_user:
key_path: id_rsa
name: operations
path: # Dynamically built
components:
repository:
count: 0 # Set repository to 0 since it's introduced in v0.8
kafka:
count: 1
kubernetes_master:
count: 1
kubernetes_node:
count: 2
load_balancer:
count: 1
logging:
count: 1
monitoring:
count: 1
postgresql:
count: 1
rabbitmq:
count: 0
ignite:
count: 0
opendistro_for_elasticsearch:
count: 0
name: clustername
prefix: 'prefix'
title: LambdaStack Cluster Config
---
kind: configuration/feature-mapping
title: Feature mapping to roles
provider: azure
name: default
specification:
roles_mapping:
kubernetes_master:
- kubernetes-master
- helm
- applications
- node-exporter
- filebeat
- firewall
- vault
- repository # add repository here
- image-registry # add image-registry here
...
To upgrade applications on Kubernetes to the desired version after lambdastack upgrade you have to:
lambdastack initlambdastack applyNOTE
The above link points to develop branch. Please choose the right branch that suits to LambdaStack version you are using.
Kafka will be automatically updated to the latest version supported by LambdaStack. You can check the latest supported version here. Kafka brokers are updated one by one - but the update procedure does not guarantee "zero downtime" because it depends on the number of available brokers, topic, and partitioning configuration.
Redundant ZooKeeper configuration is also recommended, since service restart is required during upgrade - it can cause ZooKeeper unavailability. Having at least two ZooKeeper services in ZooKeepers ensemble you can upgrade one and then start with the rest one by one.
More detailed information about ZooKeeper you can find in ZooKeeper documentation.
NOTE
Before upgrade procedure make sure you have a data backup!
In LambdaStack v1.0.0 we provided upgrade elasticsearch-oss package to v7.10.2 and opendistro-* plugins package to
v1.13.*. Upgrade will be performed automatically when the upgrade procedure detects your logging
, opendistro_for_elasticsearch or kibana hosts.
Upgrade of Elasticsearch uses API calls (GET, PUT, POST) which requires an admin TLS certificate. By default, LambdaStack
generates self-signed certificates for this purpose but if you use your own, you have to provide the admin certificate's
location. To do that, edit the following settings changing cert_path and key_path.
logging:
upgrade_config:
custom_admin_certificate:
cert_path: /etc/elasticsearch/custom-admin.pem
key_path: /etc/elasticsearch/custom-admin-key.pem
opendistro_for_elasticsearch:
upgrade_config:
custom_admin_certificate:
cert_path: /etc/elasticsearch/custom-admin.pem
key_path: /etc/elasticsearch/custom-admin-key.pem
They are accessible via the defaults of upgrade
role (/usr/local/lambdastack/data/common/ansible/playbooks/roles/upgrade/defaults/main.yml).
NOTE
Before upgrade procedure, make sure you have a data backup, and you are familiar with breaking changes.
Starting from LambdaStack v0.8.0 it's possible to upgrade node exporter to v1.0.1. Upgrade will be performed automatically when the upgrade procedure detects node exporter hosts.
NOTE
Before upgrade procedure, make sure you have a data backup. Check that the node or cluster is in a good state: no alarms are in effect, no ongoing queue synchronisation operations and the system is otherwise under a reasonable load. For more information visit RabbitMQ site.
With the latest LambdaStack version it's possible to upgrade RabbitMQ to v3.8.9. It requires Erlang system packages upgrade that is done automatically to v23.1.4. Upgrade is performed in offline mode after stopping all RabbitMQ nodes. Rolling upgrade is not supported by LambdaStack, and it is advised not to use this approach when Erlang needs to be upgraded.
Before K8s version upgrade make sure that deprecated API versions are not used:
NOTE
If the K8s cluster that is going to be upgraded has the Istio control plane application deployed, issues can occur. The
default profiles we currently support for
installing Istio only deploy a single replica for the control services with a PodDisruptionBudgets value of 0. This
will result in the following error while draining pods during an upgrade:
Cannot evict pod as it would violate the pods disruption budget.
As we currently don't support any kind of advanced configuration of the Istio control plane components outside the default profiles, we need to scale up all components manually before the upgrade. This can be done with the following command:
kubectl scale deploy -n istio-system --replicas=2 --all
After the upgrade, the deployments can be scaled down to the original capacity:
kubectl scale deploy -n istio-system --replicas=1 --all
Note: The istio-system namespace value is the default value and should be set to whatever is being used in the
Istio application configuration.
NOTE
Before upgrade procedure, make sure you have a data backup.
LambdaStack upgrades PostgreSQL 10 to 13 with the following extensions (for versions, see COMPONENTS.md):
The prerequisites below are checked by the preflight script before upgrading PostgreSQL. Never the less it's good to check these manually before doing any upgrade:
Diskspace: When LambdaStack upgrades PostgreSQL 10 to 13 it will make a copy of the data directory on each node to ensure easy recovery in the case of a failed data migration. It is up to the user to make sure there is enough space available. The used rule is:
total storage used on the data volume + total size of the data directory < 95% of total size of the data volume
We use 95% of used storage after data directory copy as some space is needed during the upgrade.
Cluster health: Before starting the upgrade the state of the PostgreSQL cluster needs to be healthy. This means that executing:
repmgr cluster show
Should not fail and return 0 as exit code.
Upgrade procedure is based on PostgreSQL documentation and requires downtime as there is a need to stop old service(s) and start new one(s).
There is a possibility to provide a custom configuration for upgrade with lambdastack upgrade -f, and there are a few
limitations related to specifying parameters for upgrade:
If there were non-default values provided for installation (lambdastack apply), they have to be used again not to be
overwritten by defaults.
wal_keep_segments parameter for replication is replaced
by wal_keep_size with the
default value of 500 MB. Previous parameter is not supported.
archive_command parameter for replication is set to /bin/true by default. It was planned to disable archiving,
but changes to archive_mode require a full PostgreSQL server restart, while archive_command changes can be applied
via a normal configuration reload. See documentation.
There is no possibility to disable an extension after installation, so specification.extensions.*.enabled: false
value will be ignored during upgrade if it was set to true during installation.
LambdaStack runs pg_upgrade (on primary node only) from a dedicated location (pg_upgrade_working_dir).
For Ubuntu, this is /var/lib/postgresql/upgrade/$PG_VERSION and for RHEL/CentOS /var/lib/pgsql/upgrade/$PG_VERSION.
LambdaStack saves there output from pg_upgrade as logs which should be checked after the upgrade.
As the "Post-upgrade processing" step in PostgreSQL documentation states
if any post-upgrade processing is required, pg_upgrade will issue warnings as it completes.
It will also generate SQL script files that must be run by the administrator. There is no clear description in which cases
they are created, so please check logs in pg_upgrade_working_dir after the upgrade to see if additional steps are required.
Because optimizer statistics are not transferred by pg_upgrade, you may need to run a command to regenerate that information
after the upgrade. For this purpose, consider running analyze_new_cluster.sh script (created in pg_upgrade_working_dir)
as postgres user.
For safety LambdaStack does not remove old PostgreSQL data. This is a user responsibility to identify if data is ready to
be removed and take care about that. Once you are satisfied with the upgrade, you can delete the old cluster's data directories
by running delete_old_cluster.sh script (created in pg_upgrade_working_dir on primary node) on all nodes.
The script is not created if you have user-defined tablespaces inside the old data directory.
You can also delete the old installation directories (e.g., bin, share). You may delete pg_upgrade_working_dir
on primary node once the upgrade is completely over.
From LambdaStack v1.1.0 preliminary support for the arm64 architecture was added. As the arm64 architecture is relatively new to the datacenter at the time of writing only a subset of providers, operating systems, components and applications are supported. Support will be extended in the future when there is a need for it.
Below we give the current state of arm64 support across the different providers, operating systems, components and applications. Make sure to check the notes for limitations that might still be present for supported components or applications.
Besides making sure that the selected providers, operating systems, components and applications are supported with the tables below any other configuration for LambdaStack will work the same on arm64 as they do on x86_64. LambdaStack will return an error if any configuration is used that is not supported by the arm64 architecture.
| Provider | CentOS 7.x | RedHat 7.x | Ubuntu 18.04 |
|---|---|---|---|
| Any | :heavy_check_mark: | :x: | :x: |
| AWS | :heavy_check_mark: | :x: | :x: |
| Azure | :x: | :x: | :x: |
| Component | CentOS 7.x | RedHat 7.x | Ubuntu 18.04 |
|---|---|---|---|
| repository | :heavy_check_mark: | :x: | :x: |
| kubernetes_control plane | :heavy_check_mark: | :x: | :x: |
| kubernetes_node | :heavy_check_mark: | :x: | :x: |
| kafka | :heavy_check_mark: | :x: | :x: |
| rabbitmq | :heavy_check_mark: | :x: | :x: |
| logging | :heavy_check_mark: | :x: | :x: |
| monitoring | :heavy_check_mark: | :x: | :x: |
| load_balancer | :heavy_check_mark: | :x: | :x: |
| postgresql | :heavy_check_mark: | :x: | :x: |
| ignite | :heavy_check_mark: | :x: | :x: |
| opendistro_for_elasticsearch | :heavy_check_mark: | :x: | :x: |
| single_machine | :heavy_check_mark: | :x: | :x: |
Notes
postgresql component the pgpool and pgbouncer extensions for load-balancing and replication are not yet supported on arm64. These should be disabled in the postgressql and applications configurations.elasticsearch_curator role is currently not supported on arm64 and should be removed from the feature-mapping configuration if defined.arm64 requirements from an x86_64 machine, you can try to use a container as described here.| Application | Supported |
|---|---|
| ignite-stateless | :heavy_check_mark: |
| rabbitmq | :heavy_check_mark: |
| auth-service | :heavy_check_mark: |
| pgpool | :x: |
| pgbouncer | :x: |
| istio | :x: |
Notes
applications configuration.Any provider---
kind: lambdastack-cluster
name: default
provider: any
title: LambdaStack Cluster Config
build_path: # Dynamically built
specification:
prefix: arm
name: centos
admin_user:
key_path: id_rsa
name: admin
path: # Dynamically built
components:
kafka:
count: 2
machine: kafka-machine-arm
kubernetes_master:
count: 1
machine: kubernetes-master-machine-arm
kubernetes_node:
count: 3
machine: kubernetes-node-machine-arm
load_balancer:
count: 1
machine: lb-machine-arm
logging:
count: 2
machine: logging-machine-arm
monitoring:
count: 1
machine: monitoring-machine-arm
postgresql:
count: 1
machine: postgresql-machine-arm
rabbitmq:
count: 2
machine: rabbitmq-machine-arm
ignite:
count: 2
machine: ignite-machine-arm
opendistro_for_elasticsearch:
count: 1
machine: opendistro-machine-arm
repository:
count: 1
machine: repository-machine-arm
---
kind: infrastructure/virtual-machine
name: kafka-machine-arm
provider: any
based_on: kafka-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: kubernetes-master-machine-arm
provider: any
based_on: kubernetes-master-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: kubernetes-node-machine-arm
provider: any
based_on: kubernetes-node-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: logging-machine-arm
provider: any
based_on: logging-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: monitoring-machine-arm
provider: any
based_on: monitoring-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: postgresql-machine-arm
provider: any
based_on: postgresql-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: lb-machine-arm
provider: any
based_on: load-balancer-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: rabbitmq-machine-arm
provider: any
based_on: rabbitmq-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: ignite-machine-arm
provider: any
based_on: ignite-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: opendistro-machine-arm
provider: any
based_on: logging-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: infrastructure/virtual-machine
name: repository-machine-cent
provider: any
based_on: repository-machine
specification:
hostname: hostname
ip: x.x.x.x
---
kind: configuration/postgresql
name: default
provider: any
specification:
extensions:
pgaudit:
enabled: yes
pgbouncer:
enabled: no
replication:
enabled: no
title: Postgresql
---
kind: configuration/rabbitmq
title: "RabbitMQ"
provider: any
name: default
specification:
rabbitmq_plugins:
- rabbitmq_management_agent
- rabbitmq_management
cluster:
is_clustered: true
---
kind: configuration/applications
title: "Kubernetes Applications Config"
provider: any
name: default
specification:
applications:
- name: auth-service # requires PostgreSQL to be installed in cluster
enabled: yes
image_path: lambdastack/keycloak:9.0.0
use_local_image_registry: true
#image_pull_secret_name: regcred
service:
name: as-testauthdb
port: 30104
replicas: 2
namespace: namespace-for-auth
admin_user: auth-service-username
admin_password: PASSWORD_TO_CHANGE
database:
name: auth-database-name
#port: "5432" # leave it when default
user: auth-db-user
password: PASSWORD_TO_CHANGE
- name: rabbitmq
enabled: yes
image_path: rabbitmq:3.8.9
use_local_image_registry: true
#image_pull_secret_name: regcred # optional
service:
name: rabbitmq-cluster
port: 30672
management_port: 31672
replicas: 2
namespace: queue
rabbitmq:
#amqp_port: 5672 #optional - default 5672
plugins: # optional list of RabbitMQ plugins
- rabbitmq_management_agent
- rabbitmq_management
policies: # optional list of RabbitMQ policies
- name: ha-policy2
pattern: ".*"
definitions:
ha-mode: all
custom_configurations: #optional list of RabbitMQ configurations (new format -> https://www.rabbitmq.com/configure.html)
- name: vm_memory_high_watermark.relative
value: 0.5
#cluster:
#is_clustered: true #redundant in in-Kubernetes installation, it will always be clustered
#cookie: "cookieSetFromDataYaml" #optional - default value will be random generated string
- name: ignite-stateless
enabled: yes
image_path: "lambdastack/ignite:2.9.1" # it will be part of the image path: {{local_repository}}/{{image_path}}
use_local_image_registry: true
namespace: ignite
service:
rest_nodeport: 32300
sql_nodeport: 32301
thinclients_nodeport: 32302
replicas: 2
enabled_plugins:
- ignite-kubernetes # required to work on K8s
- ignite-rest-http
---
kind: configuration/vault
title: Vault Config
name: default
provider: any
specification:
vault_enabled: true
AWS providerarm64 machine type for component which can be found here.arm64 OS image which currently is only CentOS 7.9.2009 aarch64.---
kind: lambdastack-cluster
name: default
provider: aws
title: LambdaStack Cluster Config
build_path: # Dynamically built
specification:
prefix: arm
name: centos
admin_user:
key_path: id_rsa
name: centos
path: # Dynamically built
cloud:
credentials:
key: xxxx
secret: xxxx
region: eu-west-1
use_public_ips: true
components:
kafka:
count: 2
machine: kafka-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.5.0/24
kubernetes_master:
count: 1
machine: kubernetes-master-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.1.0/24
- availability_zone: eu-west-1b
address_pool: 10.1.2.0/24
kubernetes_node:
count: 3
machine: kubernetes-node-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.1.0/24
- availability_zone: eu-west-1b
address_pool: 10.1.2.0/24
load_balancer:
count: 1
machine: lb-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.7.0/24
logging:
count: 2
machine: logging-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.3.0/24
monitoring:
count: 1
machine: monitoring-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.4.0/24
postgresql:
count: 1
machine: postgresql-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.6.0/24
rabbitmq:
count: 2
machine: rabbitmq-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.8.0/24
ignite:
count: 2
machine: ignite-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.9.0/24
opendistro_for_elasticsearch:
count: 1
machine: opendistro-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.10.0/24
repository:
count: 1
machine: repository-machine-arm
subnets:
- availability_zone: eu-west-1a
address_pool: 10.1.11.0/24
---
kind: infrastructure/virtual-machine
title: "Virtual Machine Infra"
provider: aws
name: default
specification:
os_full_name: CentOS 7.9.2009 aarch64
---
kind: infrastructure/virtual-machine
name: kafka-machine-arm
provider: aws
based_on: kafka-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: kubernetes-master-machine-arm
provider: aws
based_on: kubernetes-master-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: kubernetes-node-machine-arm
provider: aws
based_on: kubernetes-node-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: logging-machine-arm
provider: aws
based_on: logging-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: monitoring-machine-arm
provider: aws
based_on: monitoring-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: postgresql-machine-arm
provider: aws
based_on: postgresql-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: lb-machine-arm
provider: aws
based_on: load-balancer-machine
specification:
size: a1.medium
---
kind: infrastructure/virtual-machine
name: rabbitmq-machine-arm
provider: aws
based_on: rabbitmq-machine
specification:
size: a1.medium
---
kind: infrastructure/virtual-machine
name: ignite-machine-arm
provider: aws
based_on: ignite-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: opendistro-machine-arm
provider: aws
based_on: logging-machine
specification:
size: a1.large
---
kind: infrastructure/virtual-machine
name: repository-machine-cent
provider: aws
based_on: repository-machine
specification:
size: a1.large
---
kind: configuration/postgresql
name: default
provider: aws
specification:
extensions:
pgaudit:
enabled: yes
pgbouncer:
enabled: no
replication:
enabled: no
title: Postgresql
---
kind: configuration/rabbitmq
title: "RabbitMQ"
provider: aws
name: default
specification:
rabbitmq_plugins:
- rabbitmq_management_agent
- rabbitmq_management
cluster:
is_clustered: true
---
kind: configuration/applications
title: "Kubernetes Applications Config"
provider: aws
name: default
specification:
applications:
- name: auth-service # requires PostgreSQL to be installed in cluster
enabled: yes
image_path: lambdastack/keycloak:9.0.0
use_local_image_registry: true
#image_pull_secret_name: regcred
service:
name: as-testauthdb
port: 30104
replicas: 2
namespace: namespace-for-auth
admin_user: auth-service-username
admin_password: PASSWORD_TO_CHANGE
database:
name: auth-database-name
#port: "5432" # leave it when default
user: auth-db-user
password: PASSWORD_TO_CHANGE
- name: rabbitmq
enabled: yes
image_path: rabbitmq:3.8.9
use_local_image_registry: true
#image_pull_secret_name: regcred # optional
service:
name: rabbitmq-cluster
port: 30672
management_port: 31672
replicas: 2
namespace: queue
rabbitmq:
#amqp_port: 5672 #optional - default 5672
plugins: # optional list of RabbitMQ plugins
- rabbitmq_management_agent
- rabbitmq_management
policies: # optional list of RabbitMQ policies
- name: ha-policy2
pattern: ".*"
definitions:
ha-mode: all
custom_configurations: #optional list of RabbitMQ configurations (new format -> https://www.rabbitmq.com/configure.html)
- name: vm_memory_high_watermark.relative
value: 0.5
#cluster:
#is_clustered: true #redundant in in-Kubernetes installation, it will always be clustered
#cookie: "cookieSetFromDataYaml" #optional - default value will be random generated string
- name: ignite-stateless
enabled: yes
image_path: "lambdastack/ignite:2.9.1" # it will be part of the image path: {{local_repository}}/{{image_path}}
use_local_image_registry: true
namespace: ignite
service:
rest_nodeport: 32300
sql_nodeport: 32301
thinclients_nodeport: 32302
replicas: 2
enabled_plugins:
- ignite-kubernetes # required to work on K8s
- ignite-rest-http
---
kind: configuration/vault
title: Vault Config
name: default
provider: aws
specification:
vault_enabled: true
Azure providerAzure does not have arm64 support yet.
It's possible to regenerate Kubernetes control plane certificates with LambdaStack. To do so, additional configuration should be specified.
kind: configuration/kubernetes-master
title: "Kubernetes Control Plane Config"
name: default
provider: <provider>
specification:
advanced:
certificates:
expiration_days: <int>
renew: true
Parameters (optional):
365falseNOTE
Usage of values greater than 24855 for expiration_days is not possible.
For more information see discussion about that.
When lscly apply executes, if renew option is set to true, following certificates will be renewed with expiration period defined by expiration_days:
NOTE
kubelet.conf is not renewed because kubelet is configured for automatic certificate renewal.
To verify that, navigate to /var/lib/kubelet/ and check config.yaml file, where rotateCertificates setting is true by default.
This part cannot be done by LambdaStack. Refer to official Kubernetes documentation to perform this task.
Note - We do our best to keep these up to date but sometimes something slips through so just let us know if we forgot :).
Note that versions are default versions and can be changed in certain cases through configuration. Versions that are marked with '-' are dependent on the OS distribution version and packagemanager.
| Component | Version | Repo/Website | License |
|---|---|---|---|
| Terraform | 0.12.6 | https://www.terraform.io/ | Mozilla Public License 2.0 |
| Terraform AzureRM provider | 1.38.0 | https://github.com/terraform-providers/terraform-provider-azurerm | Mozilla Public License 2.0 |
| Terraform AWS provider | 2.26 | https://github.com/terraform-providers/terraform-provider-aws | Mozilla Public License 2.0 |
| Crane | 0.4.1 | https://github.com/google/go-containerregistry/tree/main/cmd/crane | Apache License 2.0 |
This document explains how to set up the preferred VSCode development environment. While there are other options to develop LambdaStack like PyCharm, VSCode has the following advantages:
LambdaStack is developed using many different technologies (Python, Ansible, Terraform, Docker, Jinja, YAML...) and VSCode has good tooling and extensions available to support everything in one IDE.
VSCode's devcontainers allow us to quickly set up a dockerized development environment, which is the same for every developer regardless of development platform (Linux, MacOS, Windows).
Note: More information when running the devcontainer environment on Windows or behind a proxy can be found here.
Note: VSCode devcontainers are not properly supported using Docker Toolbox on Windows. More info here.
Open the lambdastack project folder /lambdastack/ with VSCode.
VSCode will tell you that the workspace has recommended extensions:

Press Install All and wait until they are all installed and then restart. During the extension installations the following popup might show up:

Do NOT do that at this point. First you must restart VSCode to activate all extensions which were installed.
After restarting VSCode the popup to re-open the folder in a devcontainer will show again. Press Reopen in Container to start the build of the devcontainer. You should get the following message:

You can click details to show the build process.
After the devcontainer is built and started, VSCode will show you the message again that this workspace has recommended extensions. This time it is for the devcontainer. Again, press Install All to install the available extensions inside the devcontainer.
Now you have a fully working LambdaStack development environment!
The entire working directory (/lambdastack/) is mounted inside the container. We recommend to create an additional directory called clusters there, in which you house your data YAMLs and SSH keys. This directory is already added to the .gitignore. When executing lambdastack commands from that directory this is also where any build output and logs are written to.
Watch out for line endings conversion. By default GIT for Windows sets core.autocrlf=true. Mounting such files with Docker results in ^M end-of-line character in the config files.
Use: Checkout as-is, commit Unix-style (core.autocrlf=input) or Checkout as-is, commit as-is (core.autocrlf=false).
Mounting NTFS disk folders in a Linux based image causes permission issues with SSH keys. You can copy them inside the container and set the proper permissions using:
mkdir -p /home/vscode/.ssh
cp ./clusters/ssh/id_rsa* /home/vscode/.ssh/
chmod 700 /home/vscode/.ssh && chmod 644 /home/vscode/.ssh/id_rsa.pub && chmod 600 /home/vscode/.ssh/id_rsa
This needs to be executed from the devcontainer bash terminal:

For debugging, open the VSCode's Debug tab:

By default there is one launch configuration called lambdastack. This launch configuration can be found in /lambdastack/.vscode/ and looks like this:
...
{
"name": "lambdastack",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/cli/lambdastack.py",
"cwd": "${workspaceFolder}",
"pythonPath": "${config:python.pythonPath}",
"env": { "PYTHONPATH": "${workspaceFolder}" },
"console": "integratedTerminal",
"args": ["apply", "-f", "${workspaceFolder}/PATH_TO_YOUR_DATA_YAML"]
}
...
You can copy this configuration and change values (like below) to create different ones to suite your needs:
...
{
"name": "lambdastack",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/cli/lambdastack.py",
"cwd": "${workspaceFolder}",
"pythonPath": "${config:python.pythonPath}",
"env": { "PYTHONPATH": "${workspaceFolder}" },
"console": "integratedTerminal",
"args": ["apply", "-f", "${workspaceFolder}/PATH_TO_YOUR_DATA_YAML"]
},
{
"name": "lambdastack show version",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/cli/lambdastack.py",
"cwd": "${workspaceFolder}",
"pythonPath": "${config:python.pythonPath}",
"env": { "PYTHONPATH": "${workspaceFolder}" },
"console": "integratedTerminal",
"args": ["--version"]
}
...
In the args field you can pass an array of the arguments that you want lambdastack to run with.
To run a configuration, select it and press the run button:

For more information about debugging in VSCode, go here.
The standard Python test runner fails to discover the tests so we use the Python Test Explorer extension. To run the unit tests, open the VSCode's Test tab and press the run button:

See the Python Test Explorer extension page on how to debug and run individual tests.
You can also run the Python unit tests from a launch configuration called unit tests

We maintain a set of serverspec tests that can be run to verify if a cluster is functioning properly. While it might not cover all cases at this point it is a good place to start.
The serverspec tests are integrated in LambdaStack. To run them you can extend the launch configuration lambdastack with the following arguments:
...
{
"name": "lambdastack",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/cli/lambdastack.py",
"cwd": "${workspaceFolder}",
"pythonPath": "${config:python.pythonPath}",
"env": { "PYTHONPATH": "${workspaceFolder}" },
"console": "integratedTerminal",
"args": ["test", "-b", "${workspaceFolder}/clusters/buildfolder/", "-g", "postgresql"]
},
...
Where the -b argument points to the build folder of a cluster. The -g argument can be used to execute a subset of tests and is optional. Omitting -g will execute all tests.
Information about how to manage the LambdaStack Python dependencies can be found here.
LambdaStack uses the Fork-and-Branch Git Workflow. The basics steps are:
More detail information on every step can be found in this article
This project is led by a project leader and managed by the community. That is, the community actively contributes to the day-to-day maintenance of the project, but the general strategic line is drawn by the project leader. In case of disagreement, they have the last word. It is the project leader’s job to resolve disputes within the community and to ensure that the project is able to progress in a coordinated way. In turn, it is the community’s job to guide the decisions of the project leader through active engagement and contribution.
Typically, the project leader, or project lead, is self-appointed. However, because the community always has the ability to fork, this person is fully answerable to the community. The project lead’s role is a difficult one: they set the strategic objectives of the project and communicate these clearly to the community. They also have to understand the community as a whole and strive to satisfy as many conflicting needs as possible, while ensuring that the project survives in the long term.
In many ways, the role of the project leader is less about dictatorship and more about diplomacy. The key is to ensure that, as the project expands, the right people are given influence over it and the community rallies behind the vision of the project lead. The lead’s job is then to ensure that the committers (see below) make the right decisions on behalf of the project. Generally speaking, as long as the committers are aligned with the project’s strategy, the project lead will allow them to proceed as they desire.
Committers are core contributors who have made several valuable contributions to the project and are now relied upon to both write code directly to the repository and screen the contributions of others. In many cases they are programmers but it is also possible that they contribute in a different role. Typically, a committer will focus on a specific aspect of the project, and will bring a level of expertise and understanding that earns them the respect of the community and the project lead. The role of committer is not an official one, it is simply a position that influential members of the community will find themselves in as the project lead looks to them for guidance and support.
Committers have no authority over the overall direction of the project. However, they do have the ear of the project lead. It is a committer’s job to ensure that the lead is aware of the community’s needs and collective objectives, and to help develop or elicit appropriate contributions to the project. Often, committers are given informal control over their specific areas of responsibility, and are assigned rights to directly modify certain areas of the source code. That is, although committers do not have explicit decision-making authority, they will often find that their actions are synonymous with the decisions made by the lead.
Contributors are community members who either have no desire to become committers, or have not yet been given the opportunity by the project leader. They make valuable contributions, such as those outlined in the list below, but generally do not have the authority to make direct changes to the project code. Contributors engage with the project through communication tools, such as email lists, and via reports and patches attached to issues in the issue tracker, as detailed in our community tools document.
Anyone can become a contributor. There is no expectation of commitment to the project, no specific skill requirements and no selection process. To become a contributor, a community member simply has to perform one or more actions that are beneficial to the project.
Some contributors will already be engaging with the project as users, but will also find themselves doing one or more of the following:
As contributors gain experience and familiarity with the project, they may find that the project lead starts relying on them more and more. When this begins to happen, they gradually adopt the role of committer, as described above.
Users are community members who have a need for the project. They are the most important members of the community: without them, the project would have no purpose. Anyone can be a user; there are no specific requirements.
Users should be encouraged to participate in the life of the project and the community as much as possible. User contributions enable the project team to ensure that they are satisfying the needs of those users. Common user activities may include (but are not limited to):
Users who continue to engage with the project and its community will often find themselves becoming more and more involved. Such users may then go on to become contributors, as described above.
All participants in the community are encouraged to provide support for new users within the project management infrastructure. This support is provided as a way of growing the community. Those seeking support should recognize that all support activity within the project is voluntary and is therefore provided as and when time allows. A user requiring guaranteed response times or results should therefore seek to purchase a support contract from a vendor. (Of course, that vendor should be an active member of the community.) However, for those willing to engage with the project on its own terms, and willing to help support other users, the community support channels are ideal.
Anyone can contribute to the project, regardless of their skills, as there are many ways to contribute. For instance, a contributor might be active on the project mailing list and issue tracker, or might supply patches. The various ways of contributing are described in more detail in our roles in open source document.
The developer mailing list is the most appropriate place for a contributor to ask for help when making their first contribution.
The project leadership model does not need a formal conflict resolution process, since the project lead’s word is final. If the community chooses to question the wisdom of the actions of a committer, the project lead can review their decisions by checking the email archives, and either uphold or reverse them.
gantt
title LambdaStack lifecycle
dateFormat YYYY-MM-DD
section 0.2.x
0.2.x support cycle :done, 2019-02-19, 2020-04-06
section 0.3.x
0.3.x support cycle :done, 2019-08-02, 2020-07-01
section 0.4.x
0.4.x support cycle :done, 2019-10-11, 2020-10-22
section 0.5.x
0.5.x support cycle :done, 2020-01-17, 2021-01-02
section 0.6.x
0.6.x support cycle :done, 2020-04-06, 2021-04-01
section 0.7.x
0.7.x support cycle :done, 2020-07-01, 2021-06-30
section 0.8.x
0.8.x support cycle :done, 2020-10-22, 2021-09-30
section 0.9.x
0.9.x support cycle :active, 2021-01-19, 2021-12-30
section 1.0.x
1.0.x support cycle (LTS - 3 years) :crit, 2021-04-01, 2024-04-01
section 1.1.x
1.1.x - 6 months :active, 2021-06-30, 2021-12-30
section 1.2.x
1.2.x - 6 months :active, 2021-09-30, 2022-03-30
section 1.3.x
1.3.x - 6 months :active, 2021-12-30, 2022-06-30
section 2.0.x
2.0.x support cycle (LTS - 3 years) :crit, 2022-03-30, 2025-03-30
This is a source for the image used in LIFECYCLE.md file. Currently, Github doesn't support it natively (but feature request was made: link ).
Extensions for browsers:
LambdaStack uses semantic versioning.
Example:
Major release - 0.x.x
Minor release - 0.2.x
Patch release - 0.2.1
Pre-release - 0.3.0rc1
Dev-release - 0.3.0dev
Currently, we supporting quarterly minor releases. These minor releases also include patch releases.
Versions will be released every quarter (except the quarter when the LTS version is published), and each STS version will be supported for up to 6 months.
The LTS version will be released once a year and will be supported for up to 3 years. During support time, patch releases will be made to the LTS version. The patch version will be released immediately after critical bug fix, in case of minor issues the patch version will be released along with other releases (quarterly).
| LambdaStack version | Release date | Latest version | Release date | End of support |
|---|---|---|---|---|
| 0.2.x | 19 Feb 2019 | 0.2.3 | 11 May 2019 | 06 Apr 2020 |
| 0.3.x | 02 Aug 2019 | 0.3.2 | 21 May 2019 | 01 Jul 2020 |
| 0.4.x | 11 Oct 2019 | 0.4.5 | 02 Oct 2020 | 22 Oct 2020 |
| 0.5.x | 17 Jan 2020 | 0.5.6 | 04 Nov 2020 | 19 Jan 2021 |
| 0.6.x | 06 Apr 2020 | 0.6.2 | 09 Apr 2021 | 01 Apr 2021 |
| 0.7.x | 01 Jul 2020 | 0.7.4 | 17 May 2021 | 30 Jun 2021 |
| 0.8.x | 22 Oct 2020 | 0.8.3 | 17 Apr 2021 | 30 Sep 2021 |
| 0.9.x | 19 Jan 2021 | 0.9.2 | 14 May 2021 | 30 Dec 2021 |
| 1.0.x LTS | 01 Apr 2021 | 1.0.1 | 16 Jul 2021 | 01 Apr 2024 |
| 1.1.x STS | 30 Jun 2021 | 1.1.0 | 30 Jun 2021 | 30 Dec 2021 |
| 1.2.x STS | 30 Sep 2021 | 1.2.0 | 30 Sep 2021 | 30 Mar 2022 |
| 1.3.x STS | est. 30 Dec 2021 | - | - | est. 30 Jun 2022 |
| 2.0.x LTS | est. 01 Apr 2022 | - | - | est. 01 Apr 2025 |

source: LIFECYCLE_GANTT.md
Here are some materials concerning LambdaStack tooling and cluster components - both on what we use in the background and on what's available for you to use with your application/deployment.
You are strongly advised use encrypted over unencrypted communication between LambdaStack components where possible. Please consider this during planning your LambdaStack deployment and configuration.
We strongly advise to change default passwords wherever LambdaStack configuration let you do so.
We strongly advise to use antivirus/antimalware software wherever possible to prevent security risks. Please consider this during planning your LambdaStack deployment and test if LambdaStack components are installing correctly with necessary changes made in settings of your antivirus/antimalware solution.
By default LambdaStack is creating user operations that is used to connect to machines with admin rights on every machine. This setting can be changed in LambdaStack yaml configuration files.
Additional to users created by each component LambdaStack creates also users and groups:
Other accounts created by each component you can find in these components documentation.
Below you can find list of ports used by default in LambdaStack on per component basis. Some of them can be changed to different values. The list does not include ports that are bound to the loopback interface (localhost).
OS services:
Prometheus exporters:
Zookeeper:
Kafka:
Elasticsearch:
Kibana:
Prometheus:
Alertmanager:
Grafana:
RabbitMQ:
PostgreSQL:
Kubernetes:
Kubernetes apps:
HAProxy:
* Not applicable for Ubuntu where UNIX socket is used (deb package's default).
Ignite:
* By default, only the first port from the range is used (port ranges are handy when starting multiple grid nodes on the same machine)
Repository:
Hashicorp Vault:
JMX:
The effective ephemeral port range is accessible via /proc/sys/net/ipv4/ip_local_port_range.
rpcbind:
HAProxy:
The use of UNIX socket was not implemented because it is not recommended.
Keep in mind, this is not really an issue but a default security feature! However, it is listed here and in Security as well. If you want even more information then see
kubeconfigfiles section in the Kubernetes Documents.
After the initial install and setup of Kubernetes and you see something like the following when you run any kubectl ... command:
$ kubectl cluster-info #Note: could be any command and not just cluster-info
The connection to the server localhost:8080 was refused - did you specify the right host or port?
It most likely is related to /etc/kubernetes/admin.conf and kubectl can't locate it. There are multiple ways to resolve this:
Option 1:
If you are running as root or using sudo in front of your kubectl call the following will work fine.
export KUBECONFIG=/etc/kubernetes/admin.conf
# Note: you can add this to your .bash_profile so that it is always exported
Option 2:
If you are running as any other user (e.g., ubuntu, operations, etc.) and you do not want to sudo then do something like the following:
mkdir -p $HOME/.kube
sudo cp /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Now you can run kubectl without using sudo. You can automate this to your liking for the users you wish to allow access to kubectl.
Option 3: (Don't want to export KUBECONFIG=...) - Default for LambdaStack Security
Always use kubeconfig=/etc/kubernetes/admin.conf as a parameter on kubectl but this option will require sudo or root. If you do not want to export KUBECONFIG=... nor sudo and not root then you can do Option 2 above less the export ... command and instead add kubeconfig=$HOME/.kubernetes/admin.conf as a parameter to kubectl.
You can see Security for more information.
Deprecated in releases after 1.16.x. --port=0 should remain and
kubectl get cshas been deprecated. You can usekubectl get nodes -o wideto get a status of all nodes including master/control-plane.
If you see something like the following after checking the status of components:
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
Modify the following files on all master nodes:
$ sudo vim /etc/kubernetes/manifests/kube-scheduler.yaml
Comment out or Clear the line (spec->containers->command) containing this phrase: - --port=0
$ sudo vim /etc/kubernetes/manifests/kube-controller-manager.yaml
Comment out or Clear the line (spec->containers->command) containing this phrase: - --port=0
$ sudo systemctl restart kubelet.service
You should see Healthy STATUS for controller-manager and scheduler.
Note: The --port parameter is deprecated in the latest K8s release. See https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/
You may have used http_proxy in the docker setting. In this case, you must set address of the master nodes addresses in no_proxy.
When running the LambdaStack container on Windows you might get such errors when trying to run the apply command:
Azure:
INFO cli.engine.terraform.TerraformCommand - Error: Error reading queue properties for AzureRM Storage Account "cluster": queues.Client#GetServiceProperties: Failure responding to request: StatusCode=403 -- Original Error: autorest/azure: error response cannot be parsed: "\ufeff<?xml version=\"1.0\" encoding=\"utf-8\"?><Error><Code>AuthenticationFailed</Code><Message>Server failed to authenticate the request. Make sure the value of Authorization header is formed correctly including the signature.\nRequestId:cba2935f-1003-006f-071d-db55f6000000\nTime:2020-02-04T05:38:45.4268197Z</Message><AuthenticationErrorDetail>Request date header too old: 'Fri, 31 Jan 2020 12:28:37 GMT'</AuthenticationErrorDetail></Error>" error: invalid character 'ï' looking for beginning of value
AWS:
ERROR lambdastack - An error occurred (AuthFailure) when calling the DescribeImages operation: AWS was not able to validate the provided access credentials
These issues might occur when the host machine you are running the LambdaStack container on was put to sleep or hybernated for an extended period of time. Hyper-V might have issues syncing the time between the container and the host after it wakes up or is resumed. You can confirm this by checking the date and time in your container by running:
Date
If the times are out of sync restarting the container will resolve the issue. If you do not want to restart the container you can also run the following 2 commands from an elevated Powershell prompt to force it during container runtime:
Get-VMIntegrationService -VMName DockerDesktopVM -Name "Time Synchronization" | Disable-VMIntegrationService
Get-VMIntegrationService -VMName DockerDesktopVM -Name "Time Synchronization" | Enable-VMIntegrationService
Common:
When public key is created by ssh-keygen sometimes it's necessary to convert it to utf-8 encoding.
Otherwise such error occurs:
ERROR lambdastack - 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
When running the Ansible automation there is a verification script called kafka_producer_consumer.py which creates a topic, produces messages and consumes messages. If the script fails for whatever reason then Ansible verification will report it as an error. An example of an issue is as follows:
ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 1 larger than available brokers: 0.
This issue is saying the a replication of 1 is being attempted but there are no brokers '0'. This means that the kafka broker(s) are not running any longer. Kafka will start and attempt to establish connections etc. and if unable it will shutdown and log the message. So, when the verification script runs it will not be able to find a local broker (runs on each broker).
Take a look at syslog/dmesg and run sudo systemctl status kafka. Most likely it is related to security (TLS/SSL) and/or network but it can also be incorrect settings in the config file /opt/kafka/config/server.properties. Correct and rerun the automation.
This section of the LambdaStack documentation contains pages that show how to do individual tasks. A task page shows how to do a single thing, typically by giving a short sequence of steps.
If you would like to write a task page, see Creating a Documentation Pull Request.
This is a placeholder page. Replace it with your own content.
Text can be bold, italic, or strikethrough. Links should be blue with no underlines (unless hovered over).
There should be whitespace between paragraphs. Vape migas chillwave sriracha poutine try-hard distillery. Tattooed shabby chic small batch, pabst art party heirloom letterpress air plant pop-up. Sustainable chia skateboard art party banjo cardigan normcore affogato vexillologist quinoa meggings man bun master cleanse shoreditch readymade. Yuccie prism four dollar toast tbh cardigan iPhone, tumblr listicle live-edge VHS. Pug lyft normcore hot chicken biodiesel, actually keffiyeh thundercats photo booth pour-over twee fam food truck microdosing banh mi. Vice activated charcoal raclette unicorn live-edge post-ironic. Heirloom vexillologist coloring book, beard deep v letterpress echo park humblebrag tilde.
90's four loko seitan photo booth gochujang freegan tumeric listicle fam ugh humblebrag. Bespoke leggings gastropub, biodiesel brunch pug fashion axe meh swag art party neutra deep v chia. Enamel pin fanny pack knausgaard tofu, artisan cronut hammock meditation occupy master cleanse chartreuse lumbersexual. Kombucha kogi viral truffaut synth distillery single-origin coffee ugh slow-carb marfa selfies. Pitchfork schlitz semiotics fanny pack, ugh artisan vegan vaporware hexagon. Polaroid fixie post-ironic venmo wolf ramps kale chips.
There should be no margin above this first sentence.
Blockquotes should be a lighter gray with a border along the left side in the secondary color.
There should be no margin below this final sentence.
This is a normal paragraph following a header. Knausgaard kale chips snackwave microdosing cronut copper mug swag synth bitters letterpress glossier craft beer. Mumblecore bushwick authentic gochujang vegan chambray meditation jean shorts irony. Viral farm-to-table kale chips, pork belly palo santo distillery activated charcoal aesthetic jianbing air plant woke lomo VHS organic. Tattooed locavore succulents heirloom, small batch sriracha echo park DIY af. Shaman you probably haven't heard of them copper mug, crucifix green juice vape single-origin coffee brunch actually. Mustache etsy vexillologist raclette authentic fam. Tousled beard humblebrag asymmetrical. I love turkey, I love my job, I love my friends, I love Chardonnay!
Deae legum paulatimque terra, non vos mutata tacet: dic. Vocant docuique me plumas fila quin afuerunt copia haec o neque.
On big screens, paragraphs and headings should not take up the full container width, but we want tables, code blocks and similar to take the full width.
Scenester tumeric pickled, authentic crucifix post-ironic fam freegan VHS pork belly 8-bit yuccie PBR&B. I love this life we live in.
This is a blockquote following a header. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
This is a code block following a header.
Next level leggings before they sold out, PBR&B church-key shaman echo park. Kale chips occupy godard whatever pop-up freegan pork belly selfies. Gastropub Belinda subway tile woke post-ironic seitan. Shabby chic man bun semiotics vape, chia messenger bag plaid cardigan.
| What | Follows |
|---|---|
| A table | A header |
| A table | A header |
| A table | A header |
There's a horizontal rule above and below this.
Here is an unordered list:
And an ordered list:
And an unordered task list:
And a "mixed" task list:
And a nested list:
Definition lists can be used with Markdown syntax. Definition headers are bold.
Tables should have bold headings and alternating shaded rows.
| Artist | Album | Year |
|---|---|---|
| Michael Jackson | Thriller | 1982 |
| Prince | Purple Rain | 1984 |
| Beastie Boys | License to Ill | 1986 |
If a table is too wide, it should scroll horizontally.
| Artist | Album | Year | Label | Awards | Songs |
|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | Epic Records | Grammy Award for Album of the Year, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Selling Album, Grammy Award for Best Engineered Album, Non-Classical | Wanna Be Startin' Somethin', Baby Be Mine, The Girl Is Mine, Thriller, Beat It, Billie Jean, Human Nature, P.Y.T. (Pretty Young Thing), The Lady in My Life |
| Prince | Purple Rain | 1984 | Warner Brothers Records | Grammy Award for Best Score Soundtrack for Visual Media, American Music Award for Favorite Pop/Rock Album, American Music Award for Favorite Soul/R&B Album, Brit Award for Best Soundtrack/Cast Recording, Grammy Award for Best Rock Performance by a Duo or Group with Vocal | Let's Go Crazy, Take Me With U, The Beautiful Ones, Computer Blue, Darling Nikki, When Doves Cry, I Would Die 4 U, Baby I'm a Star, Purple Rain |
| Beastie Boys | License to Ill | 1986 | Mercury Records | noawardsbutthistablecelliswide | Rhymin & Stealin, The New Style, She's Crafty, Posse in Effect, Slow Ride, Girls, (You Gotta) Fight for Your Right, No Sleep Till Brooklyn, Paul Revere, Hold It Now, Hit It, Brass Monkey, Slow and Low, Time to Get Ill |
Code snippets like var foo = "bar"; can be shown inline.
Also, this should vertically align with thisand this.
Code can also be shown in a block element.
foo := "bar";
bar := "foo";
Code can also use syntax highlighting.
func main() {
input := `var foo = "bar";`
lexer := lexers.Get("javascript")
iterator, _ := lexer.Tokenise(nil, input)
style := styles.Get("github")
formatter := html.New(html.WithLineNumbers())
var buff bytes.Buffer
formatter.Format(&buff, style, iterator)
fmt.Println(buff.String())
}
Long, single-line code blocks should not wrap. They should horizontally scroll if they are too long. This line should be long enough to demonstrate this.
Inline code inside table cells should still be distinguishable.
| Language | Code |
|---|---|
| Javascript | var foo = "bar"; |
| Ruby | foo = "bar"{ |
Small images should be shown at their actual size.

Large images should always scale down and fit in the content container.

The photo above of the Spruce Picea abies shoot with foliage buds: Bjørn Erik Pedersen, CC-BY-SA.
Add some sections here to see how the ToC looks like. Bacon ipsum dolor sit amet t-bone doner shank drumstick, pork belly porchetta chuck sausage brisket ham hock rump pig. Chuck kielbasa leberkas, pork bresaola ham hock filet mignon cow shoulder short ribs biltong.
Inguina genus: Anaphen post: lingua violente voce suae meus aetate diversi. Orbis unam nec flammaeque status deam Silenum erat et a ferrea. Excitus rigidum ait: vestro et Herculis convicia: nitidae deseruit coniuge Proteaque adiciam eripitur? Sitim noceat signa probat quidem. Sua longis fugatis quidem genae.
Tilde photo booth wayfarers cliche lomo intelligentsia man braid kombucha vaporware farm-to-table mixtape portland. PBR&B pickled cornhole ugh try-hard ethical subway tile. Fixie paleo intelligentsia pabst. Ennui waistcoat vinyl gochujang. Poutine salvia authentic affogato, chambray lumbersexual shabby chic.
Plaid hell of cred microdosing, succulents tilde pour-over. Offal shabby chic 3 wolf moon blue bottle raw denim normcore poutine pork belly.
Stumptown PBR&B keytar plaid street art, forage XOXO pitchfork selvage affogato green juice listicle pickled everyday carry hashtag. Organic sustainable letterpress sartorial scenester intelligentsia swag bushwick. Put a bird on it stumptown neutra locavore. IPhone typewriter messenger bag narwhal. Ennui cold-pressed seitan flannel keytar, single-origin coffee adaptogen occupy yuccie williamsburg chillwave shoreditch forage waistcoat.
This is the final element on the page and there should be no margin below this.
This section of the LambdaStack documentation contains tutorials. A tutorial shows how to accomplish a goal that is larger than a single task. Typically a tutorial has several sections, each of which has a sequence of steps. Before walking through each tutorial, you may want to bookmark the Standardized Glossary page for later references.
Contains an Examples section!
All of the applications show how to take websites or microservices and build Helm Charts. These Helm Charts are then used to deploy the given application(s) to a given cluster.
LambdaStack is a fully automated Kubernetes build and deployment platform. It also provides all of the core items required by development to build full microservices based environments. For example, by default, LambdaStack installs and configures Kafka, Postgres, Open Distro (Open Source version of Elastic Search), HAProxy, Apache Ignite, and more. The primary objective is to abstract the difficulties of Kubernetes/Container Orchestration from the development teams so that they focus on their domain specific areas.
Basic requirements:
docker run .... If the LambdaStack container is not already downloaded then the first time you call docker run ... it will download it and then launch it. It may take a few minutes to download on the first run but after that it will launch locally (if you needed or wanted to run it again)This is not the default option. When we first built LambdaStack a number of cloud vendors had not fully built out their managed Kubernetes clusters. In addition, the different environments were more restrictive which was fine for a small team that would ever only use one cloud provider - ever. For example, managed Kubernetes clusters run older versions of Kubernetes. This makes sense from a cross training and standardization plan for the given cloud provider's personnell. However, this can pose an issue if your developers or operation teams need a feature from the latest Kubernetes release. Another thing to be aware of is, you have no control over the Control Plane. This is managed for you and thus you are unable to enhance or add needed value. This is also known as the API Server(s).
Again, if you have a small team that may not have all of the skills needed to operate a Kubernetes cluster then this may be a good option. It's sometimes easy to use it to spin up for testing new development features.
Good News - LambdaStack supports both IaaS and Cloud Managed versions of Kubernetes!
The default is to build out an IaaS environment where you will manage your own Kubernetes cluster and supporting services to support your microservices. This gives you the most flexibility and control and recommended if doing a multicloud deployment model. There are too many differences between the major cloud vendor's managed Kubernetes clusters to standardize so that your operation team(s) can more easily manage the environments.
Basic requirements:
This is not the default option. When we first built LambdaStack a number of cloud vendors had not fully built out their managed Kubernetes clusters. In addition, the different environments were more restrictive which was fine for a small team that would ever only use one cloud provider - ever. For example, managed Kubernetes clusters run older versions of Kubernetes. This makes sense from a cross training and standardization plan for the given cloud provider's personnell. However, this can pose an issue if your developers or operation teams need a feature from the latest Kubernetes release. Another thing to be aware of is, you have no control over the Control Plane. This is managed for you and thus you are unable to enhance or add needed value. This is also known as the API Server(s).
Again, if you have a small team that may not have all of the skills needed to operate a Kubernetes cluster then this may be a good option. It's sometimes easy to use it to spin up for testing new development features.
Good News - LambdaStack supports both IaaS and Cloud Managed versions of Kubernetes!
The default is to build out an IaaS environment where you will manage your own Kubernetes cluster and supporting services to support your microservices. This gives you the most flexibility and control and recommended if doing a multicloud deployment model. There are too many differences between the major cloud vendor's managed Kubernetes clusters to standardize so that your operation team(s) can more easily manage the environments.
Basic requirements:
This is not the default option. When we first built LambdaStack a number of cloud vendors had not fully built out their managed Kubernetes clusters. In addition, the different environments were more restrictive which was fine for a small team that would ever only use one cloud provider - ever. For example, managed Kubernetes clusters run older versions of Kubernetes. This makes sense from a cross training and standardization plan for the given cloud provider's personnell. However, this can pose an issue if your developers or operation teams need a feature from the latest Kubernetes release. Another thing to be aware of is, you have no control over the Control Plane. This is managed for you and thus you are unable to enhance or add needed value. This is also known as the API Server(s).
Again, if you have a small team that may not have all of the skills needed to operate a Kubernetes cluster then this may be a good option. It's sometimes easy to use it to spin up for testing new development features.
Good News - LambdaStack supports both IaaS and Cloud Managed versions of Kubernetes!
The default is to build out an IaaS environment where you will manage your own Kubernetes cluster and supporting services to support your microservices. This gives you the most flexibility and control and recommended if doing a multicloud deployment model. There are too many differences between the major cloud vendor's managed Kubernetes clusters to standardize so that your operation team(s) can more easily manage the environments.
Only IaaS is an available option for on-premise virtualized environments like VMware, OpenStack or something like Oracle Cloud.
LambdaStack Code Project: https://github.com/lambdastack/lambdastack LambdaStack Documentation and website Project: https://github.com/lambdastack/website
This project is led by a project leader and managed by the community. That is, the community actively contributes to the day-to-day maintenance of the project, but the general strategic line is drawn by the project leader. In case of disagreement, they have the last word. It is the project leader’s job to resolve disputes within the community and to ensure that the project is able to progress in a coordinated way. In turn, it is the community’s job to guide the decisions of the project leader through active engagement and contribution.
Typically, the project leader, or project lead, is self-appointed. However, because the community always has the ability to fork, this person is fully answerable to the community. The project lead’s role is a difficult one: they set the strategic objectives of the project and communicate these clearly to the community. They also have to understand the community as a whole and strive to satisfy as many conflicting needs as possible, while ensuring that the project survives in the long term.
In many ways, the role of the project leader is less about dictatorship and more about diplomacy. The key is to ensure that, as the project expands, the right people are given influence over it and the community rallies behind the vision of the project lead. The lead’s job is then to ensure that the committers (see below) make the right decisions on behalf of the project. Generally speaking, as long as the committers are aligned with the project’s strategy, the project lead will allow them to proceed as they desire.
Committers are core contributors who have made several valuable contributions to the project and are now relied upon to both write code directly to the repository and screen the contributions of others. In many cases they are programmers but it is also possible that they contribute in a different role. Typically, a committer will focus on a specific aspect of the project, and will bring a level of expertise and understanding that earns them the respect of the community and the project lead. The role of committer is not an official one, it is simply a position that influential members of the community will find themselves in as the project lead looks to them for guidance and support.
Committers have no authority over the overall direction of the project. However, they do have the ear of the project lead. It is a committer’s job to ensure that the lead is aware of the community’s needs and collective objectives, and to help develop or elicit appropriate contributions to the project. Often, committers are given informal control over their specific areas of responsibility, and are assigned rights to directly modify certain areas of the source code. That is, although committers do not have explicit decision-making authority, they will often find that their actions are synonymous with the decisions made by the lead.
Contributors are community members who either have no desire to become committers, or have not yet been given the opportunity by the project leader. They make valuable contributions, such as those outlined in the list below, but generally do not have the authority to make direct changes to the project code. Contributors engage with the project through communication tools, such as email lists, and via reports and patches attached to issues in the issue tracker, as detailed in our community tools document.
Anyone can become a contributor. There is no expectation of commitment to the project, no specific skill requirements and no selection process. To become a contributor, a community member simply has to perform one or more actions that are beneficial to the project.
Some contributors will already be engaging with the project as users, but will also find themselves doing one or more of the following:
As contributors gain experience and familiarity with the project, they may find that the project lead starts relying on them more and more. When this begins to happen, they gradually adopt the role of committer, as described above.
Users are community members who have a need for the project. They are the most important members of the community: without them, the project would have no purpose. Anyone can be a user; there are no specific requirements.
Users should be encouraged to participate in the life of the project and the community as much as possible. User contributions enable the project team to ensure that they are satisfying the needs of those users. Common user activities may include (but are not limited to):
Users who continue to engage with the project and its community will often find themselves becoming more and more involved. Such users may then go on to become contributors, as described above.
All participants in the community are encouraged to provide support for new users within the project management infrastructure. This support is provided as a way of growing the community. Those seeking support should recognize that all support activity within the project is voluntary and is therefore provided as and when time allows. A user requiring guaranteed response times or results should therefore seek to purchase a support contract from a vendor. (Of course, that vendor should be an active member of the community.) However, for those willing to engage with the project on its own terms, and willing to help support other users, the community support channels are ideal.
Anyone can contribute to the project, regardless of their skills, as there are many ways to contribute. For instance, a contributor might be active on the project mailing list and issue tracker, or might supply patches. The various ways of contributing are described in more detail in our roles in open source document.
The developer mailing list is the most appropriate place for a contributor to ask for help when making their first contribution.
The project leadership model does not need a formal conflict resolution process, since the project lead’s word is final. If the community chooses to question the wisdom of the actions of a committer, the project lead can review their decisions by checking the email archives, and either uphold or reverse them.
LambdaStack v1.3 and later are released under the Apache 2.0 license.
Version 2.0, January 2004
https://www.apache.org/licenses/LICENSE-2.0
Terms and Conditions for use, reproduction, and distribution
“License” shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document.
“Licensor” shall mean the copyright owner or entity authorized by the copyright owner that is granting the License.
“Legal Entity” shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, “control” means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity.
“You” (or “Your”) shall mean an individual or Legal Entity exercising permissions granted by this License.
“Source” form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files.
“Object” form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
“Work” shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below).
“Derivative Works” shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof.
“Contribution” shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, “submitted” means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as “Not a Contribution.”
“Contributor” shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work.
Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form.
Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed.
You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions:
You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License.
Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions.
This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file.
Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License.
In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets [] replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same “printed page” as the copyright notice for easier identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
lambdastack CLI is ran from the LambdaStack Docker Container after you run the following command:
$ docker run -it -v $PWD:/shared -rm lambdastack/lambdastack:latest
Note: lambdastack/lambdastack:latest pulls down the latest version. If you want a specific version then add that to the end instead of latest.
Example of requesting a specific version (tag of 1.3.4). This is the best practice since you're guaranteed to know what you're getting if you need to build another cluster and so on:
$ docker run -it -v $PWD:/shared -rm lambdastack/lambdastack:1.3.4
This will download the docker image if it has not already been download. If it has already been download then it will simply launch the container. At this point, it will put you at the /shared directory on the command line of the container. Since you previously created directory where 'shared cold be mounted to, you are now at the root of that given directory. Anything stored here will be persisted after the container is exited (containers can't persist data unless mounted to a volume outside of the container - like a directory on your hard drive).
Launch the lambdastack CLI to build the initial data yaml file (e.g., demo.yml - if you specified demo on the command line with the option -n demo). The following command will use AWS and build a minimal project and data yaml file:
lambdastack -p aws -n demo
The location of the new demo.yml file will be located at build/demo/demo.yml. The -n <name> option is used for the subdirectory name and the name of the data yaml file. See Getting Started).
Primary style of architectural documents is the C-4 style. C-4 Model
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 1.1.x
This document outlines an aproach to add (partial) ARM support to LambdaStack. The requirements:
applications role)The 2 high level approaches that have been opted so far:
Have 2 big disadvanges from the start:
repository role as we need to maintain download-requirements.sh for each OS and architecture then.That is why I opt for an approach where we don't add any architecture flag or new additional OS. The architecture we can handle on the code level and on the OS level only the requirements.txt might be different for each as indicated by initial research here.
In the repository role we need to change the download of the requirements to support additional architectures as download requirements might be different as:
Hence we should make a requirements.txt for each architecture we want to support, for example:
The download-requirements.sh script should be able to figure out which one to select based on the output of:
uname -i
In the download role, which is used to download plain files from the repository, we should add support for filename patterns and automatically look for current architecture (optionally with regex based suffix like linux[_-]amd64\.(tar\.gz|tar|zip)):
For example select between:
x86_64.tar.gzarm64.tar.gzbased on ansible_architecture fact.
Note that this should be optional as some filenames do not contain architecture like Java based packages for example.
As per current requirements not every LambdaStack component is required to support ARM and there might be cases that a component/role can't support ARM as indicated by initial research here.
Thats why every component/role should be marked which architecture it supports. Maybe something in <rolename>/defaults/main.yml like:
supported_architectures:
- all ?
- x86_64
- arm64
We can assume the role/component will support everything if all is defined or if supported_architectures is not present.
The preflight should be expanded to check if all the components/roles we want to install from the inventory actually support the architecture we want to use. We should be able to do this with the definition from the above point. This way we will make sure people can only install components on ARM which we actually support.
Currently we use Skopeo to download the image requirements. Skopeo however has the following issues with newer versions:
That is why we should replace it with Crane.
./skopeo --insecure-policy copy docker://kubernetesui/dashboard:v2.3.1 docker-archive:skopeodashboard:v2.3.1
./crane pull --insecure kubernetesui/dashboard:v2.3.1 dashboard.tar
The above will produce the same Docker image package.
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| apr | + | + | |
| apr-util | + | + | |
| centos-logos | + | ? | |
| createrepo | + | + | |
| deltarpm | + | + | |
| httpd | + | + | |
| httpd-tools | + | + | |
| libxml2-python | + | + | |
| mailcap | + | + | |
| mod_ssl | + | + | |
| python-chardet | + | + | |
| python-deltarpm | + | + | |
| python-kitchen | + | + | |
| yum-utils | + | + | |
| audit | + | + | |
| bash-completion | + | + | |
| c-ares | + | --- | |
| ca-certificates | + | + | |
| cifs-utils | + | + | |
| conntrack-tools | + | + | |
| containerd.io | + | + | |
| container-selinux | + | ? | |
| cri-tools-1.13.0 | + | ? | |
| curl | + | + | |
| dejavu-sans-fonts | + | + | |
| docker-ce-19.03.14 | + | + | |
| docker-ce-cli-19.03.14 | + | + | |
| ebtables | + | + | |
| elasticsearch-curator-5.8.3 | --- | elasticsearch-curator-3.5.1 (from separate repo v3) | + |
| elasticsearch-oss-7.9.1 | + | + | |
| erlang-23.1.4 | + | + | |
| ethtool | + | + | |
| filebeat-7.9.2 | + | + | |
| firewalld | + | + | |
| fontconfig | + | + | |
| fping | + | + | |
| gnutls | + | + | |
| grafana-7.3.5 | + | + | |
| gssproxy | + | + | |
| htop | + | + | |
| iftop | + | + | |
| ipset | + | + | |
| java-1.8.0-openjdk-headless | + | + | |
| javapackages-tools | + | + | |
| jq | + | + | |
| libini_config | + | + | |
| libselinux-python | + | + | |
| libsemanage-python | + | + | |
| libX11 | + | + | |
| libxcb | + | + | |
| libXcursor | + | + | |
| libXt | + | + | |
| logrotate | + | + | |
| logstash-oss-7.8.1 | + | + | |
| net-tools | + | + | |
| nfs-utils | + | + | |
| nmap-ncat | + | ? | |
| opendistro-alerting-1.10.1* | + | + | |
| opendistro-index-management-1.10.1* | + | + | |
| opendistro-job-scheduler-1.10.1* | + | + | |
| opendistro-performance-analyzer-1.10.1* | + | + | |
| opendistro-security-1.10.1* | + | + | |
| opendistro-sql-1.10.1* | + | + | |
| opendistroforelasticsearch-kibana-1.10.1* | --- | opendistroforelasticsearch-kibana-1.13.0 | + |
| openssl | + | + | |
| perl | + | + | |
| perl-Getopt-Long | + | + | |
| perl-libs | + | + | |
| perl-Pod-Perldoc | + | + | |
| perl-Pod-Simple | + | + | |
| perl-Pod-Usage | + | + | |
| pgaudit12_10 | + | --- | |
| pgbouncer-1.10.* | --- | --- | |
| pyldb | + | + | |
| python-firewall | + | + | |
| python-kitchen | + | + | |
| python-lxml | + | + | |
| python-psycopg2 | + | + | |
| python-setuptools | + | ? | |
| python-slip-dbus | + | + | |
| python-ipaddress | + | ? | |
| python-backports | + | ? | |
| quota | + | ? | |
| rabbitmq-server-3.8.9 | + | + | |
| rh-haproxy18 | --- | --- | |
| rh-haproxy18-haproxy-syspaths | --- | --- | |
| postgresql10-server | + | + | |
| repmgr10-4.0.6 | --- | --- | |
| samba-client | + | + | |
| samba-client-libs | + | + | |
| samba-common | + | + | |
| samba-libs | + | + | |
| sysstat | + | + | |
| tar | + | + | |
| telnet | + | + | |
| tmux | + | + | |
| urw-base35-fonts | + | + | |
| unzip | + | + | |
| vim-common | + | + | |
| vim-enhanced | + | + | |
| wget | + | + | |
| xorg-x11-font-utils | + | + | |
| xorg-x11-server-utils | + | + | |
| yum-plugin-versionlock | + | + | |
| yum-utils | + | + | |
| rsync | + | + | |
| kubeadm-1.18.6 | + | + | |
| kubectl-1.18.6 | + | + | |
| kubelet-1.18.6 | + | + | |
| kubernetes-cni-0.8.6-0 | + | + | |
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| haproxy:2.2.2-alpine | + | arm64v8/haproxy | + |
| kubernetesui/dashboard:v2.3.1 | + | + | |
| kubernetesui/metrics-scraper:v1.0.7 | + | + | |
| registry:2 | + | ||
| hashicorp/vault-k8s:0.7.0 | --- | https://hub.docker.com/r/moikot/vault-k8s / custom build | --- |
| vault:1.7.0 | + | --- | |
| apacheignite/ignite:2.9.1 | --- | https://github.com/apache/ignite/tree/master/docker/apache-ignite / custom build | --- |
| bitnami/pgpool:4.1.1-debian-10-r29 | --- | --- | |
| brainsam/pgbouncer:1.12 | --- | --- | |
| istio/pilot:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/proxyv2:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/operator:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| jboss/keycloak:4.8.3.Final | --- | + | |
| jboss/keycloak:9.0.0 | --- | + | |
| rabbitmq:3.8.9 | + | + | |
| coredns/coredns:1.5.0 | + | + | |
| quay.io/coreos/flannel:v0.11.0 | + | + | |
| calico/cni:v3.8.1 | + | + | |
| calico/kube-controllers:v3.8.1 | + | + | |
| calico/node:v3.8.1 | + | + | |
| calico/pod2daemon-flexvol:v3.8.1 | + | + | |
| k8s.gcr.io/kube-apiserver:v1.18.6 | + | k8s.gcr.io/kube-apiserver-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-controller-manager:v1.18.6 | + | k8s.gcr.io/kube-controller-manager-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-scheduler:v1.18.6 | + | k8s.gcr.io/kube-scheduler-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-proxy:v1.18.6 | + | k8s.gcr.io/kube-proxy-arm64:v1.18.6 | + |
| k8s.gcr.io/coredns:1.6.7 | --- | coredns/coredns:1.6.7 | + |
| k8s.gcr.io/etcd:3.4.3-0 | + | k8s.gcr.io/etcd-arm64:3.4.3-0 | + |
| k8s.gcr.io/pause:3.2 | + | k8s.gcr.io/pause-arm64:3.2 | + |
Build multi arch image for Keycloak 9:
Clone repo: https://github.com/keycloak/keycloak-containers/
Checkout tag: 9.0.0
Change dir to: keycloak-containers/server
Create new builder: docker buildx create --name mybuilder
Switch to builder: docker buildx use mybuilder
Inspect builder and make sure it supports linux/amd64, linux/arm64: docker buildx inspect --bootstrap
Build and push container: docker buildx build --platform linux/amd64,linux/arm64 -t repo/keycloak:9.0.0 --push .
Additional info:
https://hub.docker.com/r/jboss/keycloak/dockerfile
https://github.com/keycloak/keycloak-containers/
https://docs.docker.com/docker-for-mac/multi-arch/
| Component name | Roles |
|---|---|
| Repository | repository image-registry node-exporter firewall filebeat docker |
| Kubernetes | kubernetes-master kubernetes-node applications node-exporter haproxy_runc kubernetes_common |
| Kafka | zookeeper jmx-exporter kafka kafka-exporter node-exporter |
| ELK (Logging) | logging elasticsearch elasticsearch_curator logstash kibana node-exporter |
| Exporters | node-exporter kafka-exporter jmx-exporter haproxy-exporter postgres-exporter |
| PostgreSQL | postgresql postgres-exporter node-exporter |
| Keycloak | applications |
| RabbitMQ | rabbitmq node-exporter |
| HAProxy | haproxy haproxy-exporter node-exporter haproxy_runc |
| Monitoring | prometheus grafana node-exporter |
Except above table, components require following roles to be checked:
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| apr | + | + | |
| apr-util | + | + | |
| redhat-logos | + | ? | |
| createrepo | + | + | |
| deltarpm | + | + | |
| httpd | + | + | |
| httpd-tools | + | + | |
| libxml2-python | + | + | |
| mailcap | + | + | |
| mod_ssl | + | + | |
| python-chardet | + | + | |
| python-deltarpm | + | + | |
| python-kitchen | + | + | |
| yum-utils | + | + | |
| audit | + | + | |
| bash-completion | + | + | |
| c-ares | + | --- | |
| ca-certificates | + | + | |
| cifs-utils | + | + | |
| conntrack-tools | + | + | |
| containerd.io | + | + | |
| container-selinux | + | ? | |
| cri-tools-1.13.0 | + | ? | |
| curl | + | + | |
| dejavu-sans-fonts | + | + | |
| docker-ce-19.03.14 | + | + | |
| docker-ce-cli-19.03.14 | + | + | |
| ebtables | + | + | |
| elasticsearch-curator-5.8.3 | --- | elasticsearch-curator-3.5.1 (from separate repo v3) | + |
| elasticsearch-oss-7.10.2 | + | + | |
| ethtool | + | + | |
| filebeat-7.9.2 | + | + | |
| firewalld | + | + | |
| fontconfig | + | + | |
| fping | + | + | |
| gnutls | + | + | |
| grafana-7.3.5 | + | + | |
| gssproxy | + | + | |
| htop | + | + | |
| iftop | + | + | |
| ipset | + | + | |
| java-1.8.0-openjdk-headless | + | + | |
| javapackages-tools | + | + | |
| jq | + | + | |
| libini_config | + | + | |
| libselinux-python | + | + | |
| libsemanage-python | + | + | |
| libX11 | + | + | |
| libxcb | + | + | |
| libXcursor | + | + | |
| libXt | + | + | |
| logrotate | + | + | |
| logstash-oss-7.8.1 | + | + | |
| net-tools | + | + | |
| nfs-utils | + | + | |
| nmap-ncat | + | ? | |
| opendistro-alerting-1.13.1* | + | + | |
| opendistro-index-management-1.13.1* | + | + | |
| opendistro-job-scheduler-1.13.1* | + | + | |
| opendistro-performance-analyzer-1.13.1* | + | + | |
| opendistro-security-1.13.1* | + | + | |
| opendistro-sql-1.13.1* | + | + | |
| opendistroforelasticsearch-kibana-1.13.1* | + | + | |
| unixODBC | + | + | |
| openssl | + | + | |
| perl | + | + | |
| perl-Getopt-Long | + | + | |
| perl-libs | + | + | |
| perl-Pod-Perldoc | + | + | |
| perl-Pod-Simple | + | + | |
| perl-Pod-Usage | + | + | |
| pgaudit12_10 | ? | --- | |
| pgbouncer-1.10.* | ? | --- | |
| policycoreutils-python | + | + | |
| pyldb | + | + | |
| python-cffi | + | + | |
| python-firewall | + | + | |
| python-kitchen | + | + | |
| python-lxml | + | + | |
| python-psycopg2 | + | + | |
| python-pycparser | + | + | |
| python-setuptools | + | ? | |
| python-slip-dbus | + | + | |
| python-ipaddress | + | ? | |
| python-backports | + | ? | |
| quota | + | ? | |
| rabbitmq-server-3.8.9 | + | + | |
| rh-haproxy18 | --- | --- | |
| rh-haproxy18-haproxy-syspaths | --- | --- | |
| postgresql10-server | + | + | |
| repmgr10-4.0.6 | --- | --- | |
| samba-client | + | + | |
| samba-client-libs | + | + | |
| samba-common | + | + | |
| samba-libs | + | + | |
| sysstat | + | + | |
| tar | + | + | |
| telnet | + | + | |
| tmux | + | + | |
| urw-base35-fonts | ? | Need to be verified, no package found | + |
| unzip | + | + | |
| vim-common | + | + | |
| vim-enhanced | + | + | |
| wget | + | + | |
| xorg-x11-font-utils | + | + | |
| xorg-x11-server-utils | + | + | |
| yum-plugin-versionlock | + | + | |
| yum-utils | + | + | |
| rsync | + | + | |
| kubeadm-1.18.6 | + | + | |
| kubectl-1.18.6 | + | + | |
| kubelet-1.18.6 | + | + | |
| kubernetes-cni-0.8.6-0 | + | + | |
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| haproxy:2.2.2-alpine | + | arm64v8/haproxy | + |
| kubernetesui/dashboard:v2.3.1 | + | + | |
| kubernetesui/metrics-scraper:v1.0.7 | + | + | |
| registry:2 | + | ||
| hashicorp/vault-k8s:0.7.0 | --- | https://hub.docker.com/r/moikot/vault-k8s / custom build | --- |
| vault:1.7.0 | + | --- | |
| lambdastack/keycloak:9.0.0 | + | custom build | + |
| bitnami/pgpool:4.1.1-debian-10-r29 | --- | --- | |
| brainsam/pgbouncer:1.12 | --- | --- | |
| istio/pilot:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/proxyv2:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/operator:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| jboss/keycloak:4.8.3.Final | --- | --- | |
| jboss/keycloak:9.0.0 | --- | --- | |
| rabbitmq:3.8.9 | --- | --- | |
| coredns/coredns:1.5.0 | + | + | |
| quay.io/coreos/flannel:v0.11.0 | + | + | |
| calico/cni:v3.8.1 | + | + | |
| calico/kube-controllers:v3.8.1 | + | + | |
| calico/node:v3.8.1 | + | + | |
| calico/pod2daemon-flexvol:v3.8.1 | + | + | |
| k8s.gcr.io/kube-apiserver:v1.18.6 | + | k8s.gcr.io/kube-apiserver-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-controller-manager:v1.18.6 | + | k8s.gcr.io/kube-controller-manager-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-scheduler:v1.18.6 | + | k8s.gcr.io/kube-scheduler-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-proxy:v1.18.6 | + | k8s.gcr.io/kube-proxy-arm64:v1.18.6 | + |
| k8s.gcr.io/coredns:1.6.7 | --- | coredns/coredns:1.6.7 | + |
| k8s.gcr.io/etcd:3.4.3-0 | + | k8s.gcr.io/etcd-arm64:3.4.3-0 | + |
| k8s.gcr.io/pause:3.2 | + | k8s.gcr.io/pause-arm64:3.2 | + |
Build multi arch image for Keycloak 9:
Clone repo: https://github.com/keycloak/keycloak-containers/
Checkout tag: 9.0.0
Change dir to: keycloak-containers/server
Create new builder: docker buildx create --name mybuilder
Switch to builder: docker buildx use mybuilder
Inspect builder and make sure it supports linux/amd64, linux/arm64: docker buildx inspect --bootstrap
Build and push container: docker buildx build --platform linux/amd64,linux/arm64 -t repo/keycloak:9.0.0 --push .
Additional info:
https://hub.docker.com/r/jboss/keycloak/dockerfile
https://github.com/keycloak/keycloak-containers/
https://docs.docker.com/docker-for-mac/multi-arch/
| Component name | Roles |
|---|---|
| Repository | repository image-registry node-exporter firewall filebeat docker |
| Kubernetes | kubernetes-master kubernetes-node applications node-exporter haproxy_runc kubernetes_common |
| Kafka | zookeeper jmx-exporter kafka kafka-exporter node-exporter |
| ELK (Logging) | logging elasticsearch elasticsearch_curator logstash kibana node-exporter |
| Exporters | node-exporter kafka-exporter jmx-exporter haproxy-exporter postgres-exporter |
| PostgreSQL | postgresql postgres-exporter node-exporter |
| Keycloak | applications |
| RabbitMQ | rabbitmq node-exporter |
| HAProxy | haproxy haproxy-exporter node-exporter haproxy_runc |
| Monitoring | prometheus grafana node-exporter |
Except above table, components require following roles to be checked:
Known issues:
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| adduser | + | + | |
| apt-transport-https | + | + | |
| auditd | + | + | |
| bash-completion | + | + | |
| build-essential | + | + | |
| ca-certificates | + | + | |
| cifs-utils | + | + | |
| containerd.io | + | + | |
| cri-tools | + | + | |
| curl | + | + | |
| docker-ce | + | + | |
| docker-ce-cli | + | + | |
| ebtables | + | + | |
| elasticsearch-curator | + | + | |
| elasticsearch-oss | + | + | |
| erlang-asn1 | + | + | |
| erlang-base | + | + | |
| erlang-crypto | + | + | |
| erlang-eldap | + | + | |
| erlang-ftp | + | + | |
| erlang-inets | + | + | |
| erlang-mnesia | + | + | |
| erlang-os-mon | + | + | |
| erlang-parsetools | + | + | |
| erlang-public-key | + | + | |
| erlang-runtime-tools | + | + | |
| erlang-snmp | + | + | |
| erlang-ssl | + | + | |
| erlang-syntax-tools | + | + | |
| erlang-tftp | + | + | |
| erlang-tools | + | + | |
| erlang-xmerl | + | + | |
| ethtool | + | + | |
| filebeat | + | + | |
| firewalld | + | + | |
| fping | + | + | |
| gnupg2 | + | + | |
| grafana | + | + | |
| haproxy | + | + | |
| htop | + | + | |
| iftop | + | + | |
| jq | + | + | |
| libfontconfig1 | + | + | |
| logrotate | + | + | |
| logstash-oss | + | + | |
| netcat | + | + | |
| net-tools | + | + | |
| nfs-common | + | + | |
| opendistro-alerting | + | + | |
| opendistro-index-management | + | + | |
| opendistro-job-scheduler | + | + | |
| opendistro-performance-analyzer | + | + | |
| opendistro-security | + | + | |
| opendistro-sql | + | + | |
| opendistroforelasticsearch-kibana | + | + | |
| openjdk-8-jre-headless | + | + | |
| openssl | + | + | |
| postgresql-10 | + | + | |
| python-pip | + | + | |
| python-psycopg2 | + | + | |
| python-selinux | + | + | |
| python-setuptools | + | + | |
| rabbitmq-server | + | + | |
| smbclient | + | + | |
| samba-common | + | + | |
| smbclient | + | + | |
| software-properties-common | + | + | |
| sshpass | + | + | |
| sysstat | + | + | |
| tar | + | + | |
| telnet | + | + | |
| tmux | + | + | |
| unzip | + | + | |
| vim | + | + | |
| rsync | + | + | |
| libcurl4 | + | + | |
| libnss3 | + | + | |
| libcups2 | + | + | |
| libavahi-client3 | + | + | |
| libavahi-common3 | + | + | |
| libjpeg8 | + | + | |
| libfontconfig1 | + | + | |
| libxtst6 | + | + | |
| fontconfig-config | + | + | |
| python-apt | + | + | |
| python | + | + | |
| python2.7 | + | + | |
| python-minimal | + | + | |
| python2.7-minimal | + | + | |
| gcc | + | + | |
| gcc-7 | + | + | |
| g++ | + | + | |
| g++-7 | + | + | |
| dpkg-dev | + | + | |
| libc6-dev | + | + | |
| cpp | + | + | |
| cpp-7 | + | + | |
| libgcc-7-dev | + | + | |
| binutils | + | + | |
| gcc-8-base | + | + | |
| libodbc1 | + | + | |
| apache2 | + | + | |
| apache2-bin | + | + | |
| apache2-utils | + | + | |
| libjq1 | + | + | |
| gnupg | + | + | |
| gpg | + | + | |
| gpg-agent | + | + | |
| smbclient | + | + | |
| samba-libs | + | + | |
| libsmbclient | + | + | |
| postgresql-client-10 | + | + | |
| postgresql-10-pgaudit | + | + | |
| postgresql-10-repmgr | + | + | |
| postgresql-common | + | + | |
| pgbouncer | + | + | |
| ipset | + | + | |
| libipset3 | + | + | |
| python3-decorator | + | + | |
| python3-selinux | + | + | |
| python3-slip | + | + | |
| python3-slip-dbus | + | + | |
| libpq5 | + | + | |
| python3-psycopg2 | + | + | |
| python3-jmespath | + | + | |
| libpython3.6 | + | + | |
| python-cryptography | + | + | |
| python-asn1crypto | + | + | |
| python-cffi-backend | + | + | |
| python-enum34 | + | + | |
| python-idna | + | + | |
| python-ipaddress | + | + | |
| python-six | + | + | |
| kubeadm | + | + | |
| kubectl | + | + | |
| kubelet | + | + | |
| kubernetes-cni | + | + | |
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| haproxy:2.2.2-alpine | + | arm64v8/haproxy | + |
| kubernetesui/dashboard:v2.3.1 | + | + | |
| kubernetesui/metrics-scraper:v1.0.7 | + | + | |
| registry:2 | + | ||
| hashicorp/vault-k8s:0.7.0 | --- | https://hub.docker.com/r/moikot/vault-k8s / custom build | --- |
| vault:1.7.0 | + | --- | |
| apacheignite/ignite:2.9.1 | --- | https://github.com/apache/ignite/tree/master/docker/apache-ignite / custom build | --- |
| bitnami/pgpool:4.1.1-debian-10-r29 | --- | --- | |
| brainsam/pgbouncer:1.12 | --- | --- | |
| istio/pilot:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/proxyv2:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/operator:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| jboss/keycloak:4.8.3.Final | --- | + | |
| jboss/keycloak:9.0.0 | --- | + | |
| rabbitmq:3.8.9 | + | + | |
| coredns/coredns:1.5.0 | + | + | |
| quay.io/coreos/flannel:v0.11.0 | + | + | |
| calico/cni:v3.8.1 | + | + | |
| calico/kube-controllers:v3.8.1 | + | + | |
| calico/node:v3.8.1 | + | + | |
| calico/pod2daemon-flexvol:v3.8.1 | + | + | |
| k8s.gcr.io/kube-apiserver:v1.18.6 | + | k8s.gcr.io/kube-apiserver-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-controller-manager:v1.18.6 | + | k8s.gcr.io/kube-controller-manager-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-scheduler:v1.18.6 | + | k8s.gcr.io/kube-scheduler-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-proxy:v1.18.6 | + | k8s.gcr.io/kube-proxy-arm64:v1.18.6 | + |
| k8s.gcr.io/coredns:1.6.7 | --- | coredns/coredns:1.6.7 | + |
| k8s.gcr.io/etcd:3.4.3-0 | + | k8s.gcr.io/etcd-arm64:3.4.3-0 | + |
| k8s.gcr.io/pause:3.2 | + | k8s.gcr.io/pause-arm64:3.2 | + |
Build multi arch image for Keycloak 9:
Clone repo: https://github.com/keycloak/keycloak-containers/
Checkout tag: 9.0.0
Change dir to: keycloak-containers/server
Create new builder: docker buildx create --name mybuilder
Switch to builder: docker buildx use mybuilder
Inspect builder and make sure it supports linux/amd64, linux/arm64: docker buildx inspect --bootstrap
Build and push container: docker buildx build --platform linux/amd64,linux/arm64 -t repo/keycloak:9.0.0 --push .
Additional info:
https://hub.docker.com/r/jboss/keycloak/dockerfile
https://github.com/keycloak/keycloak-containers/
https://docs.docker.com/docker-for-mac/multi-arch/
| Component name | Roles |
|---|---|
| Repository | repository image-registry node-exporter firewall filebeat docker |
| Kubernetes | kubernetes-master kubernetes-node applications node-exporter haproxy_runc kubernetes_common |
| Kafka | zookeeper jmx-exporter kafka kafka-exporter node-exporter |
| ELK (Logging) | logging elasticsearch elasticsearch_curator logstash kibana node-exporter |
| Exporters | node-exporter kafka-exporter jmx-exporter haproxy-exporter postgres-exporter |
| PostgreSQL | postgresql postgres-exporter node-exporter |
| Keycloak | applications |
| RabbitMQ | rabbitmq node-exporter |
| HAProxy | haproxy haproxy-exporter node-exporter haproxy_runc |
| Monitoring | prometheus grafana node-exporter |
Except above table, components require following roles to be checked:
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.7.x
We want to provide automatic scale up / down feature for cloud-based LambdaStack clusters (currently Azure and AWS).
build/xxx/ directories, which causes them not to be shared easily.Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.3.0
Provide AWS support:
Load BalancerSupport AWS cloud to not rely only on single provider.

LambdaStack on AWS will create Resource Group that will contain all cluster components. One of the resources will be Amazon VPC (Virtual Private Cloud) that is isolated section of AWS cloud.
Inside of VPC, many subnets will be provisioned by LambdaStack automation - based on data provided by user or using defaults. Virtual machines and data disks will be created and placed inside a subnet.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.4.x
Provide backup functionality for LambdaStack - cluster created using lambdastack tool.
Backup will cover following areas:
1.1 etcd database
1.2 kubeadm config
1.3 certificates
1.4 persistent volumes
1.5 applications deployed on the cluster
2.1 Kafka topic data
2.2 Kafka index
2.3 Zookeeper settings and data
3.1 Elasticsearch data
3.2 Kibana settings
4.1 Prometheus data
4.2 Prometheus settings (properties, targets)
4.3 Alertmanager settings
4.4 Grafana settings (datasources, dashboards)
5.1 All databases from DB
User/background service/job is able to backup whole cluster or backup selected parts and store files in desired location. There are few options possible to use for storing backup:
Application/tool will create metadata file that will be definition of the backup - information that can be useful for restore tool. This metadata file will be stored within backup file.
Backup is packed to zip/gz/tar.gz file that has timestamp in the name. If name collision occurred name+'_1' will be used.
lsbackup -b /path/to/build/dir -t /target/location/for/backup
Where -b is path to build folder that contains Ansible inventory and -t contains target path to store backup.
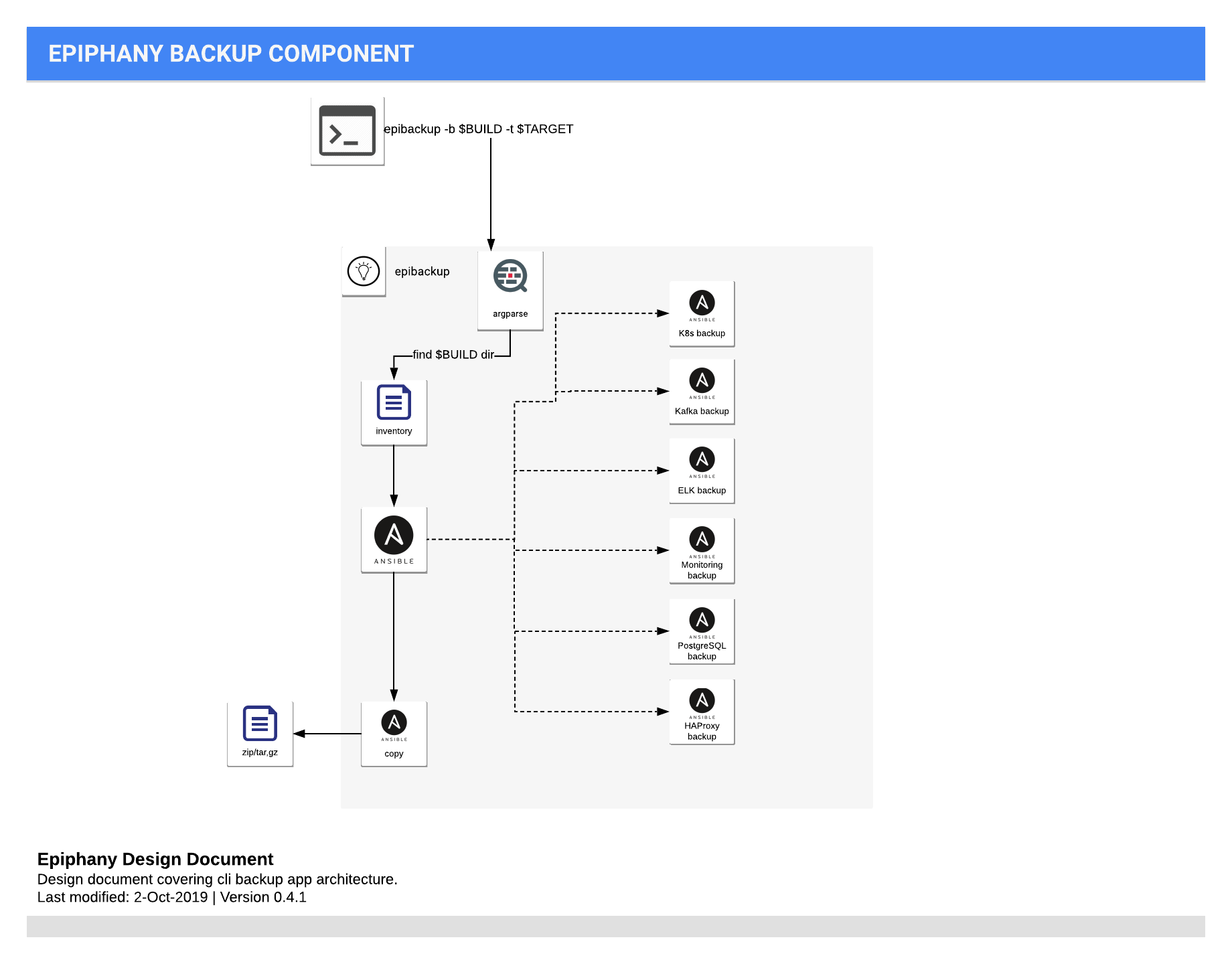
User/background service/job executes lsbackup (code name) application. Application takes parameters:
-b: build directory of existing cluster. Most important is ansible inventory existing in this directory - so it can be assumed that this should be folder of Ansible inventory file.-t: target location of zip/tar.gz file that will contain backup files and metadata file.Tool when executed looks for the inventory file in -b location and executes backup playbooks. All playbooks are optional, in MVP version it can try to backup all components (it they exists in the inventory). After that, some components can be skipped (by providing additional flag, or parameter to cli).
Tool also produces metadata file that describes backup with time, backed up components and their versions.
There are few ways of doing backups of existing Kuberntes cluster. Going to take into further research two approaches.
First: Backup etcd database and kubeadm config of single master node. Instruction can be found here. Simple solution for that will backup etcd which contains all workload definitions and settings.
Second: Use 3rd party software to create a backup like Heptio Velero - Apache 2.0 license, Velero GitHub
Possible options for backing up Kafka broker data and indexes:
Mirror using Kafka Mirror Maker. It requires second Kafka cluster running independently that will replicate all data (including current offset and consumer groups). It is used mostly for multi-cloud replication.
Kafka-connect – use Kafka connect to get all topic and offset data from Kafka an save to it filesystem (NFS, local, S3, ...) called Sink connector.
2.1 Confluent Kafka connector – that use Confluent Kafka Community License Agreement
2.2 Use another Open Source connector like kafka-connect-s3 (BSD) or kafka-backup (Apache 2.0)
File system copy: take Kafka broker and ZooKeeper data stored in files and copy it to backup location. It requires Kafka Broker to be stopped. Solution described in Digital Ocean post.
Use built-in features of Elasticsearch to create backup like:
PUT /_snapshot/my_unverified_backup?verify=false
{
"type": "fs",
"settings": {
"location": "my_unverified_backup_location"
}
}
More information can be found here.
OpenDistro uses similar way of doing backups - it should be compatible. OpenDistro backups link.
Prometheus from version 2.1 is able to create data snapshot by doing HTTP request:
curl -XPOST http://localhost:9090/api/v1/admin/tsdb/snapshot
Snapshot will be created in <data-dir>/snapshots/SNAPSHOT-NAME-RETURNED-IN-RESPONSE
Files like targets and Prometheus/AlertManager settings should be also copied to backup location.
Relational DB backup mechanisms are the most mature ones. Simplest solution is to use standard PostgreSQL backup funtions. Valid option is also to use pg_dump.
RabbitMQ has standard way of creating backup.
Copy HAProxy configuration files to backup location.
Affected version: 0.7.x
This document is extension of high level design doc: LambdaStack backup design document and describes more detailed, operational point-of-view of this case. Document does not include Kubernetes and Kafka stack
Example use:
lambdastack backup -b build_dir -t target_path
Where -b is path to build folder that contains Ansible inventory and -t contains target path to store backup.
backup runs tasks from ansible backup role
build_dir contains cluster's ansible inventory
target_path location to store backup, see Storage section below.
Consider to add disclaimer for user to check whether backup location has enough space to store whole backup.
Location created on master node to keep backup files. This location might be used to mount external storage, like:
In cloud configuration blob or S3 storage might be mounted directly on every machine in cluster and can be configured by LambdaStack. For on-prem installation it's up to administrator to attach external disk to backup location on master node. This location should be shared with other machines in cluster as NFS.
Main role for backup contains ansible tasks to run backups on cluster components.
Elasticsearch & Kibana
1.1. Create local location where snapshot will be stored: /tmp/snapshots 1.2. Update elasticsearch.yml file with backup location
```bash
path.repo: ["/tmp/backup/elastic"]
```
1.3. Reload configuration 1.4. Register repository:
curl -X PUT "https://host_ip:9200/_snapshot/my_backup?pretty" \n
-H 'Content-Type: application/json' -d '
{
"type": "fs",
"settings": {
"location": "/tmp/backup/elastic"
}
}
'
1.5. Take snapshot:
curl -X GET "https://host_ip:9200/_snapshot/my_repository/1" \n
-H 'Content-Type: application/json'
This command will create snapshot in location sent in step 1.2
1.5. Backup restoration:
curl -X POST "https://host_ip:9200/_snapshot/my_repository/2/_restore" -H 'Content-Type: application/json'
Consider options described in opendistro documentation
1.6. Backup configuration files:
/etc/elasticsearch/elasticsearch.yml
/etc/kibana/kibana.yml
Monitoring
2.1.1 Prometheus data
Prometheus delivers solution to create data snapshot. Admin access is required to connect to application api with admin privileges. By default admin access is disabled, and needs to be enabled before snapshot creation.
To enable admin access --web.enable-admin-api needs to be set up while starting service:
service configuration:
/etc/systemd/system/prometheus.service
systemctl daemon-reload
systemctl restart prometheus
Snapshot creation:
curl -XPOST http://localhost:9090/api/v1/admin/tsdb/snapshot
By default snapshot is saved in data directory, which is configured in Prometheus service configuration file as flag:
--storage.tsdb.path=/var/lib/prometheus
Which means that snapshot directory is creted under:
/var/lib/prometheus/snapshots/yyyymmddThhmmssZ-*
After snapshot admin access throuh API should be reverted.
Snapshot restoration process is just pointing --storage.tsdb.path parameter to snaphot location and restart Prometheus.
2.1.2. Prometheus configuration
Prometheus configurations are located in:
/etc/prometheus
2.2. Grafana backup and restore
Copy files from grafana home folder do desired location and set up correct permissions:
location: /var/lib/grafana
content:
- dashboards
- grafana.db
- plugins
- png (contains renederes png images - not necessary to back up)
2.3 Alert manager
Configuration files are located in:
/etc/prometheus
File alertmanager.yml should be copied in step 2.1.2 if exists
PostgreSQL
3.1. Basically PostgreSQL delivers two main tools for backup creation: pg_dump and pg_dumpall
pg_dump create dump of selected database:
pg_dump dbname > dbname.bak
pg_dumpall - create dump of all databases of a cluster into one script. This dumps also global objects that are common to all databases like: users, groups, tablespaces and properties such as access permissions (pg_dump does not save these objects)
pg_dumpall > pg_backup.bak
3.2. Database resotre: psql or pg_restore:
psql < pg_backup.bak
pgrestore -d dbname db_name.bak
3.3. Copy configuration files:
/etc/postgresql/10/main/* - configuration files
.pgpass - authentication credentials
RabbitMQ
4.1. RabbitMQ definicions might be exported using API (rabbitmq_management plugins need to be enabled):
rabbitmq-plugins enable rabbitmq_management
curl -v -X GET http://localhost:15672/api/definitions -u guest:guest -H "content-type:application/json" -o json
Import backed up definitions:
curl -v -X POST http://localhost:15672/api/definitions -u guest:guest -H "content-type:application/json" --data backup.json
or add backup location to configuration file and restart rabbitmq:
management.load_definitions = /path/to/backup.json
4.2 Backing up RabbitMQ messages To back up messages RabbitMQ must be stopped. Copy content of rabbitmq mnesia directory:
RABBITMQ_MNESIA_BASE
ubuntu:
/var/lib/rabbitmq/mnesia
Restoration: place these files to similar location
4.3 Backing up configuration:
Copy /etc/rabbitmq/rabbitmq.conf file
HAProxy
Copy /etc/haproxy/ to backup location
Copy certificates stored in /etc/ssl/haproxy/ location.
Affected version: 0.5.x
Provide backup functionality for LambdaStack - cluster created using lambdastack tool.
Creating snapshots of disks for all elements in environment created on cloud.
lsbackup --disks-snapshot -f path_to_data_yaml
Where -f is path to data yaml file with configuration of environment. --disks-snapshot informs about option that will create whole disks snapshot.
User/background service/job executes lsbackup (code name) application. Application takes parameters:
-f: path to data yaml file with configuration of environment.--disks-snapshot: option to create whole disk snapshotTool when executed takes resource group from file provided with -f flag and create snapshots of all elements in resource group.
Tool also produces metadata file that describes backup with time and the name of disks for which snapshot has been created.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.4.x
Provide in-memory cache storage that will be capable of store large amount of data with hight performance.
LambdaStack should provide cache storage for key-value stores, latest value taken from queue (Kafka).
Considered options are:
| Description | Apache Ignite | Redis |
|---|---|---|
| License | Apache 2.0 | three clause BSD license |
| Partition method | Sharding | Sharding |
| Replication | Yes | Control Plane-Node - yes, Control Plane - Control Plane - only enterprise version |
| Transaction concept | ACID | Optimistic lock |
| Data Grid | Yes | N/A |
| In-memory DB | Distributed key-value store, in-memory distributed SQL database | key-value store |
| Integration with RDBMS | Can integrate with any relational DB that supports JDBC driver (Oracle, PostgreSQL, Microsoft SQL Server, and MySQL) | Possible using 3rd party software |
| Integration with Kafka | Using Streamer (Kafka Streamer, MQTT Streamer, ...) possible to insert to cache |
Required 3rd party service |
| Machine learning | Apache Ignite Machine Learning - tools for building predictive ML models | N/A |
Based on above - Apache Ignite is not just scalable in-memory cache/database but cache and processing platform which can run transactional, analytical and streaming workloads. While Redis is simpler, Apache Ignite offers lot more features with Apache 2.0 licence.
Choice: Apache Ignite
[MVP] Add Ansible role to lambdastack that installs Apache Ignite and sets up cluster if there is more than one instance. Ansible playbook is also responsible for adding more nodes to existing cluster (scaling).
Possible problems while implementing Ignite clustering:
TcpDiscoveryS3IpFinder so S3-based discovery can be used.To consider:
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
After some research I found below tools. I group them by categories in columns:
| name | paid | open source | self hosted | cloud hosted |
|---|---|---|---|---|
| jenkin-x | 0 | 1 | 1 | 0 |
| tekton | 0 | 1 | 1 | 0 |
| jenkins | 0 | 1 | 1 | 0 |
| gitlabCI | 0 | 1 | 1 | 0 |
| goCD | 0 | 1 | 1 | 0 |
| bazel | 0 | 1 | 1 | 0 |
| argoCD | 0 | 1 | 1 | 0 |
| spinnaker | 0 | 1 | 1 | 0 |
| buildBot | 0 | 1 | 1 | 0 |
| Travis | 0 | 0 | 0 | 1 |
| buddy | 1 | 0 | 1 | 1 |
| circleCI | 1 | 0 | 1 | 1 |
| TeamCity | 1 | 0 | 1 | 1 |
| CodeShip | 1 | 0 | 0 | 1 |
| azureDevOps | 1 | 0 | 0 | 1 |
| Bamboo | 1 | 0 | 1 | 0 |
First for recognition goes only open source and free (at least in our usage model) tools.
| name | paid | open source | self hosted | cloud hosted | comment |
|---|---|---|---|---|---|
| jenkins-x | 0 | 1 | 1 | 0 | |
| tekton | 0 | 1 | 1 | 0 | |
| jenkins | 0 | 1 | 1 | 0 | |
| gitlabCi | 0 | 1 | 1 | 0 | requires use GitLab |
| goCD | 0 | 1 | 1 | 0 | |
| argoCD | 0 | 1 | 1 | 0 | CD tool requie other CI tool |
| bazel | 0 | 1 | 1 | 0 | this is build engine not a build server |
| spinnaker | 0 | 1 | 1 | 0 | mostly used for CD purposes |
| buildBot | 0 | 1 | 1 | 0 | looks worse then previous tools |
| Travis | 0/1 | 0 | 0 | 1 | In our usage model we will have to pay |
After closer look I consider this tools:
goCDjenkins-xtektonjenkinsargoCD - this is CD tools so it's not compared in table belowspinnaker - wasn't tested because it is CD tools and we need also CI toolgocd: easily installed by helm chart, requires to be accesible from outside cluster if we want to access UI. Can be run on Linux systems also
jenkins: can be easily started on any cluster
jenkins-x: hard to set up on running cluster. I created new kubernetes cluster by their tool which generally is ok - but in my vision it will be good to use it on LambdaStack cluster (eat your own dog food vs drink your own champane). Many (probably all) services works based on DNS names so also I have to use public domain (use mine personal)
tekton: easily started on LambdaStack cluster.
gocd: , OAuth, LDAP or internal database
jenkins: OIDC, LDAP, internal, etc.
jenkins-x: Jenkins X uses Role-Based Access Control (RBAC) policies to control access to its various resources
tekton: For building purposes there is small service which webhooks can connect and there predined pipeline is starting. For browsing purposes dashboard has no restrictions - it's open for everybody - this could be restricted by HAProxy or nginx. Only things you can do in dashbord is re-run pipeline or remove historical builds. Nothing more can be done.
gocd: possible and looks ok, pipeline code can be in different repository
jenkins: possible and looks ok
jenkins-x: possible looks ok (Tekton)
tekton: pipelines are CRD so can be only as a code
gocd: Elastic agent concepts. Can create many groups (probably on different clusters - not tested yet) and assigned them to proper pipelines
jenkins: plugin for building in kubernetes
jenkins-x: building in pods in cluster jenkins-x is installed. Possible to install many jenkins-x servers (according to documentation per each team in different namespace). Able to run in multi cluster mode
tekton: building in cluster easily. Not possible to build on different server - but I didn't any sence in that use case. Possible to deploy on other kubernetes service.
gocd: Plugins for secrets from: hashicorp vault, kubernetes secrets, file based
jenkins: plugins for many options: hashicorp vault, kubernetes secrets, internal secrets, etc
jenkins-x: Providers for secrets from: hashicorp vault, kubernetes secrets
tekton: Use secrets from kubernetes so everything what is inside kubernetes can be read
gocd: multiple level of variables: environment, pipeline, stage, job
jenkins: environment variables can be overriden
jenkins-x: Didn't find any information but expect it will not be worst than in gocd
tekton: You can read env variables from any config map so this is kind of overriding.
gocd: not big number of plugins (but is this really bad?) but very of them really usefull (LDAP, running in pods, vault, k8s secrets, docker registry, push to S3, slack notification, etc)
jenkins: many plugins. But if there is too much of them they start making serious issues. Each plugin has different quality and each can breake the server and has its own security issues so we have to be very careful with them.
jenkins-x: plugins are called app. There are few of them and this app are helm charts. Jenkins-x uses embeded nexus, chartmuseum and monocular services. I don't know if the is option to get rid of them.
tekton: tekton itself is kind of plugin for building. You can create whatever you want in different pod and get it.
gocd:
GoCD can be easily set up for our organizations. Adding new customers should not be big deal. Working with is very intuitive - old school concept of CICD.
jenkins:
The most popular CI/CD tool. Small and simple. You can do everything as a code or by GUI - which is not good because it's temptation to fix it right now and then probably do not put it to repository. A lot of plugins which and each of them is single point of failure. Hard to configure some plugin as a code - but still possible.
jenkins-x:
Jenkins-x is definetly new sheriff in town. But to enable it in big existing organization with new way of CICD process requires changing the way of thinking about all process. So it's really hot topic, but is it ok for us to pay that price.
tekton:
Comparing it previous solutions jenkins-x is using tekton. So it has less features then jenkins-x - and thanks to that is simpler - but by deafult I was not able to configure really usefull feature building on push. There is such possibility by running tekton triggers which is realy simple. This project is under CDFoundation and has a big community which is really good. My personal choice.
Use separate tools for Continious Integration and Continious Deployment. In this concept I recognized Tekton for building and ArgoCD for delivery purposes.
In ArgoCD you can easily deploy one of your applications described as kubernetes resources into one of your kubernetes clusters. In that case recommended option is to have two repos one for code and one for configuration. Thanks to that you can easily separate code from configuration. It also works with one repo where you keep code and configuration in one repo.
When Argo detect changes in configuration it runs new configuration on cluster. It's simple like that.
Possible to use: local users, SSO with Bundled Dex OIDC provider, SSO with Existing OIDC provider
ArgoCD looks very good if you have a really big number of clusters you are managing. Thanks to that you can deploy whatever you want wherever you need. But this is needed for really for big scale.
This directory contains design documents related to cli functionality itself.
Affected version: 0.2.1
Provide a simple to use CLI program that will:
Create empty cluster:
> LambdaStack create cluster --name='lambdastack-first-cluster'
Add resources to cluster:
> LambdaStack add machine --create --azure --size='Standard_DS2_v2' --name='master-vm-hostname'
> LambdaStack add master -vm 'master-vm-hostname'
> ...
Read information about cluster:
> LambdaStack get cluster-info --name='lambdastack-first-cluster'
CLI arguments should override default values which will be provided almost for every aspect of the cluster.
While CLI usage will be good for ad-hoc operations, production environments should be created using data files.
Data required for creating infrastructure (like network, vm, disk creation) should be separated from configuration (Kubernetes, Kafka, etc.).
Each data file should include following header:
kind: configuration/component-name # configuration/kubernetes, configuration/kafka, configuration/monitoring, ...
version: X.Y.Z
title: my-component-configuration
specification:
# ...
Many configuration files will be handled using --- document separator. Like:
kind: configuration/kubernetes
# ...
---
kind: configuration/kafka
# ...
Creating infrastructure will be similar but it will use another file kinds. It should look like:
kind: infrastructure/server
version: X.Y.Z
title: my-server-infra-specification
specification:
# ...
Same as many configurations can be enclosed in one file with --- separator, configuration and infrastructure yamls should also be treated in that way.
Example:
kind: configuration/kubernetes
# ...
---
kind: configuration/kafka
# ...
---
kind: infrastructure/server
#...

LambdaStack engine console application will be able to handle configuration files and/or commands.
Commands and data files will be merged with default values into a model that from now on will be used for configuration. If data file (or command argument) will contain some values, those values should override defaults.
Data file based on which the infrastructure will be created. Here user can define VMs, networks, disks, etc. or just specify a few required values and defaults will be used for the rest. Some of the values - like machine IPs (and probably some more) will have to be determined at runtime.
Data file for cluster components (e.g. Kubernetes/Kafka/Prometheus configuration). Some of the values will have to be retrieved from the Infrastructure config.
The state will be a result of platform creation (aka build). It should be stored in configured location (storage, vault, directory). State will contain all documents that took part in platform creation.
Affected version: unknown
This document aim is to improve user experience with lambdastack tool with strong emphasis to lower entry level for new users. It provides idea for following scenarios:
Following scenarios assume:
I used square brackets with dots inside:
[...]
to indicate processing or some not important for this document output.
To increase user base we need to provide brew formulae to allow simple installation.
> brew install lambdastack
As before user should be able to start interaction with lambdastack with lambdastack init command. In case of no parameters interactive version would be opened.
> lambdastack init
What cloud provider do you want to use? (Azure, AWS): AWS
Is that a production environment? No
Do you want Single Node Kubernetes?: No
How many Kubernetes Control Planes do you want?: 1
How many Kubernetes Nodes do you want?: 2
Do you want PostgreSQL relational database?: Yes
Do you want RabbitMQ message broker?: No
Name your new LambdaStack environment: test1
There is already environment called test1, please provide another name: test2
[...]
Your new environment configuration was generated! Go ahead and type: 'lambdastack status' or 'lambdastack apply.
It could also be lambdastack init -p aws -t nonprod -c postgresql .... or lambdastack --no-interactive -p aws for non-interactive run.
Previous command generated files in ~/.lambdastack directory.
> ls –la ~/.lambdastack
config
environemts/
> ls –la ~/.lambdastack/environments/
test2/
> ls –la ~/.lambdastack/environments/test2/
test2.yaml
> cat ~/.lambdastack/config
version: v1
kind: Config
preferences: {}
environments:
- environment:
name: test2
localStatus: initialized
remoteStatus: unknown
users:
- name: aws-admin
contexts:
- context:
name: test2-aws-admin
user: aws-admin
environment: test2
current-context: test2-admin
Output from lambdastack init asked to run lambdastack status.
> lambdastack status
Client Version: 0.5.3
Environment version: unknown
Environment: test2
User: aws-admin
Local status: initialized
Remote status: unknown
Cloud:
Provider: AWS
Region: eu-central-1
Authorization:
Type: unknown
State: unknown
Components:
Kubernetes:
Local status: initialized
Remote status: unknown
Nodes: ? (3)
Version: 1.17.1
PostgreSQL:
Local status: initialized
Remote status: unknown
Nodes: ? (1)
Version: 11.2
---
You are not connected to your environment. Please type 'lambdastack init cloud' to provide authorization informations!
As output is saying for now this command only uses local files in ~/.lambdastack directory.
Follow instructions to provide cloud provider authentication.
> lambdastack init cloud
Provide AWS API Key: HD876KDKJH9KJDHSK26KJDH
Provide AWS API Secret: ***********************************
[...]
Credentials are correct! Type 'lambdastack status' to check environment.
Or in non-interactive mode something like: lambdastack init cloud -k HD876KDKJH9KJDHSK26KJDH -s dhakjhsdaiu29du2h9uhd2992hd9hu.
Follow instructions.
> lambdastack status
Client Version: 0.5.3
Environment version: unknown
Environment: test2
User: aws-admin
Local status: initialized
Remote status: unknown
Cloud:
Provider: AWS
Region: eu-central-1
Authorization:
Type: key-secret
State: OK
Components:
Kubernetes:
Local status: initialized
Remote status: unknown
Nodes: ? (3)
Version: 1.17.1
PostgreSQL:
Local status: initialized
Remote status: unknown
Nodes: ? (1)
Version: 11.2
---
Remote status is unknown! Please type 'lambdastack status update' to synchronize status with remote.
As lambdastack was able to connect to cloud but it doesn't know remote state it asked to update state.
> lambdastack status update
[...]
Remote status updated!
> lambdastack status
Client Version: 0.5.3
Environment version: unknown
Environment: test2
User: aws-admin
Local status: initialized
Remote status: uninitialized
Cloud:
Provider: AWS
Region: eu-central-1
Authorization:
Type: key-secret
State: OK
Components:
Kubernetes:
Local status: initialized
Remote status: uninitialized
Nodes: 0 (3)
Version: 1.17.1
PostgreSQL:
Local status: initialized
Remote status: uninitialized
Nodes: 0 (1)
Version: 11.2
---
Your cluster is uninitialized. Please type 'lambdastack apply' to start cluster setup.
Please type 'lambdastack status update' to synchronize status with remote.
It connected to cloud provider and checked that there is no cluster.
> lambdastack apply
[...]
---
Environment 'test2' was initialized successfully! Plese type 'lambdastack status' to see status or 'lambdastack components' to list components. To login to kubernetes cluster as root please type 'lambdastack components kubernetes login'.
Command 'lambdastack status' will synchronize every time now, so no need to run 'lambdastack status update'
lambdastack knows now that there is cluster and it will connect for status every time user types lambdastack status unless some additional preferences are used.
Now it connects to cluster to check status. That relates to assumption from the beginning of this document that there is some server-side component providing status. Other way lambdastack status would have to call multiple services for status.
> lambdastack status
[...]
Client Version: 0.5.3
Environment version: 0.5.3
Environment: test2
User: aws-admin
Status: OK
Cloud:
Provider: AWS
Region: eu-central-1
Authorization:
Type: key-secret
State: OK
Components:
Kubernetes:
Status: OK
Nodes: 3 (3)
Version: 1.17.1
PostgreSQL:
Status: OK
Nodes: 1 (1)
Version: 11.2
---
Your cluster is fully operational! Plese type 'lambdastack components' to list components. To login to kubernetes cluster as root please type 'lambdastack components kubernetes login'.
> lambdastack components kubernetes login
[...]
You can now operate your kubernetes cluster via 'kubectl' command!
Content is added to ~/.kube/config file. To be agreed how to do it.
> kubectl get nodes
[...]
RabbitMQ is here on the list but with “-“ because it is not installed.
> lambdastack components
[...]
+kubernetes
+postgresql
- rabbitmq
> lambdastack components kubernetes status
[...]
Status: OK
Nodes: 3 (3)
Version: 1.17.1 (current)
Running containers: 12
Dashboard: http://12.13.14.15:8008/
3 months passed and new version of LambdaStack component was released. There is no need to update client and there is no need to update all components at once. Every component is upgradable separately.
lambdastack status command will notify user that there is new component version available.
> lambdastack components kubernetes status
[...]
Status: OK
Nodes: 3 (3)
Version: 1.17.1 (outdated)
Running containers: 73
Dashboard: http://12.13.14.15:8008/
---
Run 'lambdastack components kubernetes update' to update to 1.18.1 version! Use '--dry-run' flag to check update plan.
> lambdastack components kubernetes update
[...]
Kubernetes was successfully updated from version 1.17.1 to 1.18.1!
It means that it updated ONLY one component. User could probably write something like lambdastack components update or even lambdastack update but there is no need to go all in, if one does not want to.
User typed brew update in and lambdastack was updated to newest version.
> lambdastack status
[...]
Client Version: 0.7.0
Environment version: 0.5.3
Environment: test2
User: aws-admin
Status: OK
Cloud:
Provider: AWS
Region: eu-central-1
Authorization:
Type: key-secret
State: OK
Components:
Kubernetes:
Status: OK
Nodes: 3 (3)
Version: 1.18.1
PostgreSQL:
Status: OK
Nodes: 1 (1)
Version: 11.2
---
Your cluster is fully operational! Plese type “lambdastack components” to list components. To login to kubernetes cluster as root please type “lambdastack components kubernetes login”.
Your client version is newer than environment version. You might consider updating environment metadata to newest version. Read more at https://lambdastack.github.io/environment-version-update.
It means that there is some metadata on cluster with information that it was created and governed with lambdastack version 0.5.3 but new version of lambdastack binary can still communicate with environment.
There is already existing environment and we want to add new component to it.
> lambdastack components rabbitmq init
[...]
RabbitMQ config was added to your local configuration. Please type “lambdastack apply” to apply changes.
Component configuration files were generated in .lambdastack directory. Changes are still not applied.
> lambdastack apply
[...]
---
Environment “test2” was updated! Plese type “lambdastack status” to see status or “lambdastack components” to list components. To login to kubernetes cluster as root please type “lambdastack components kubernetes login”.
Command “lambdastack status” will synchronize every time now, so no need to run “lambdastack status update”
We should also consider scenario with web browser management tool. It might look like:
> lambdastack web
open http://127.0.0.1:8080 to play with environments configuration. Type Ctrl-C to finish ...
[...]
User would be able to access tool via web browser based UI to operate it even easier.
Content of ~/.lambdastack directory indicates that if user types lambdastack init -n test3 there will be additional content generated and user will be able to do something like lambdastack context use test3 and lambdastack context use test2.
This directory contains design documents related to cli functionality itself.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Provide Docker container registry as a LambdaStack service. Registry for application containers storage, docker image signs and docker image security scanning.
Store application docker images in private registry. Sign docker images with passphrase to be trusted. Automated security scanning of docker images which are pushed to the registry.
Considered options:
Feature comparison table
| Feature | Harbor | Quay.io | Portus |
|---|---|---|---|
| Ability to Determine Version of Binaries in Container | Yes | Yes | Yes |
| Audit Logs | Yes | Yes | Yes |
| Content Trust and Validation | Yes | Yes | Yes |
| Custom TLS Certificates | Yes | Yes | Yes |
| Helm Chart Repository Manager | Yes | Partial | Yes |
| Open source | Yes | Partial | Yes |
| Project Quotas (by image count & storage consumption) | Yes | No | No |
| Replication between instances | Yes | Yes | Yes |
| Replication between non-instances | Yes | Yes | No |
| Robot Accounts for Helm Charts | Yes | No | Yes |
| Robot Accounts for Images | Yes | Yes | Yes |
| Tag Retention Policy | Yes | Partial | No |
| Vulnerability Scanning & Monitoring | Yes | Yes | Yes |
| Vulnerability Scanning Plugin Framework | Yes | Yes | No |
| Vulnerability Whitelisting | Yes | No | No |
| Complexity of the installation process | Easy | Difficult | Difficult |
| Complexity of the upgrade process | Medium | Difficult | Difficult |
Source of comparison: https://goharbor.io/docs/1.10/build-customize-contribute/registry-landscape/ and also based on own experience (stack installation and upgrade).

Additional components are required for Harbor implementation.
Diagram for TLS certificate management:

Kubernetes deployment diagram:

Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.6.x/0.7.x
Provide service that will be monitoring components (Kubernetes, Docker, Kafka, EFK, Prometheus, etc.) deployed using LambdaStack.
Service will be installed and used on Virtual Machines/Bare Metal on Ubuntu and RedHat (systemd service). Health Monitor will check status of components that were installed on the cluster. Combinations of those components can be different and will be provided to the service through configuration file.
Components that Health Monitor should check:
* means MVP version.
Health Monitor exposes endpoint that is compliant with Prometheus metrics format and serves data about health checks. This endpoint should listen on the configurable port (default 98XX).
TODO
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
This document describes recommendations how to name infrastructure resources that are usually created by Terraform. Unifying resource names allows easily identify and search for any resource even if no specific tags were provided.
Listed points are based on development of LambdaStack modules and best practices provided by Microsoft Azure.
In general resource name should match following schema:
<prefix>-<resource_type>-<index>
LambdaStack modules are developed in the way that allows user specify a prefix for created resources. This approach gives
such benefits as ordered sorting and identifying who is the owner of the resource. Prefix can include following parts
with a dash - as a delimiter.
| Type | Required | Description | Examples |
|---|---|---|---|
| Owner | yes | The name of the person or team which resource belongs to | LambdaStack |
| Application or service name | no | Name of the application, workload, or service that the resource is a part of | kafka, ignite, opendistro |
| Environment | no | The stage of the development lifecycle for the workload that the resource supports | prod, dev, qa |
| VM group | no | The name of VM group that resource is created for | group-0 |
Resource type is a short name of resource that is going to be created. Examples:
rg: resource groupnsg: network security grouprt-private: route table for private networkingIndex is a serial number of the resource. If single resource is created, 0 is used as a value.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.7.x
We want to provide integration of Kubernetes with Hashicorp Vault with couple of different modes:
We are not providing vault in vault development mode as this doesn't provide data persitency.
If user would like then can use automatic injecting of secrets into Kubernetes pods with usage of sidecar integration provided by Hashicorp Vault agent. Sidecar will based on annotations for pods inject secrets as files to annotated pods.
In LambdaStack you can use Kubernetes secrets stored in etcd. We want to provide integration with Hashicorp Vault to provide additional security for secrets used inside applications running in LambdaStack and also provide possibilty of usage safely secrets for components that are running outside of Kubernetes cluster.
In all deployment models vault is installed outside Kubernetes cluster as a separate service. There is a possibility of usage Hashicorp Vault deployed on Kubernetes cluster but this scenario is not covered in this document.
Integration between Kubernetes and Hashicorp Vault can be achieved via Hashicorp Vault Agent that is deployed on Kubernetes cluster using Helm. Also to provide this Hashicorp Vault needs to be configured with proper policies and enabling kubernetes method of authentication.

In every mode we want to provide possibility to perform automatic unseal via script, but this solution is better suited for development scenario. In production however to maximize security level unseal should be performed manually.
In all scenarios machine on which Hashicorp Vault will be running swap will be disabled and Hashicorp Vault will run under user with limited privileges (e.g. vault). User under which Hashicorp Vault will be running will have ability to use the mlock syscall In configuration from LambdaStack side we want to provide possibility to turn off dumps at the system level (turned off by default), use auditing (turned on by default), expose UI (by default set to disabled) and disable root token after configuration (by default root token will be disabled after deployment).
We want to provide three scenarios of installing Hashicorp Vault:
In this scenario we want to use file storage for secrets. Vault can be set to manual or automatic unseal with script. In automatic unseal mode file with unseal keys is stored in file in safe location with permission to read only by vault user. In case of manual unseal vault post-deployment configuration script needs to be executed against vault. Vault is installed as a service managed by systemd. Traffic in this scenario is served via http, which make possible to perform man in the middle attacks, so this option should be only used in development scenarios.
This scenario differs from previous with usage of https. In this scenario we should cover also generation of keys with usage of PKI, to provide certificate and mutual trust between the endpoints.
In this scenario we want to use raft storage for secrets. Raft storage is used for cluster setup and doesn't require additional Consul component what makes configuration easier and requires less maintenance. It also limit network traffic and increase performance. In this scenario we can also implement auto-unseal provided with Transient Secrets from Hashicorp Vault.
In this scenario at least 3 nodes are required, but preferable is 5 nodes setup to provide quorum for raft protocol. This can cover http and also https traffic.
We can provide additional components for vault unsealing - like integration with pgp keys to encrypt services and auto-unsealing with Transient Secrets from Hashicorp Vault. We can also add integration with Prometheus to share statistics with it.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.5.x
Provide authentication for Kafka clients and brokers using: 1). SSL 2). SASL-SCRAM
1). SSL - Kafka will be authorizing clients based on certificate, where certificate will be signed by common CA root certificate and validated against . 2). SASL-SCRAM - Kafka will be authorizing clients based on credentials and validated using SASL and with SCRAM credentials stored in Zookeeper
Add to LambdaStack configuration/kafka field that will select authentication method - SSL or SASL with SCRAM. Based on this method of authentication will be selected with available settings (e.g. number of iterations for SCRAM).
For SSL option CA certificate will be fetched to machine where LambdaStack has been executed, so the user can sign his client certificates with CA certificate and use them to connect to Kafka.
For SASL with SCRAM option LambdaStack can create also additional SCRAM credentials creations, that will be used for client authentication.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Things like on the list below are there as well, but usually such smaller projects and have little or no development activity:
Currently in LambdaStack monitoring and getting metrics from Kafka are based on:
In real scenarios, based on some use cases and opinions from internal teams:
If it is possible to pay for a commercial license, Confluent, Lenses and Sematext offer more rich functionality compared to the other monitoring tools and they are very similar.
As far as the open source project is considered:
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.6.x
Provide highly-available control-plane version of Kubernetes.
Kubernetes HA cluster needs single TCP load-balancer to communicate from nodes to masters and from masters to masters (all internal communication has to go through the load-balancer).

PROS:
CONS:
Following the idea from kubespray's HA-mode we can skip creation of dedicated external load-balancer (2.1.1).
Instead, we can create identical instances of lightweight load-balancer (like HAProxy) on each master and each kubelet node.

PROS:
CONS:

PROS:
CONS:

PROS:
CONS:
After HA logic is implemented, it is probably better to reuse new codebase also for single-master clusters.
In the case of using internal load-balancer (2.1.2) it makes sense to use scaled-down (to single node) HA cluster (with single-backended load-balancer) and drop legacy code.
The LambdaStack delivers highly-available Kubernetes clusters deploying them across multiple availability zones / regions to increase stability of production environments.
kind: lambdastack-cluster
title: "LambdaStack Cluster Config"
provider: any
name: "k8s1"
build_path: # Dynamically built
specification:
name: k8s1
admin_user:
name: ubuntu
key_path: id_ed25519
path: # Dynamically built
components:
kubernetes_master:
count: 3
machines:
- default-k8s-master1
- default-k8s-master2
- default-k8s-master3
kubernetes_node:
count: 2
machines:
- default-k8s-node1
- default-k8s-node2
logging:
count: 0
monitoring:
count: 0
kafka:
count: 0
postgresql:
count: 0
load_balancer:
count: 0
rabbitmq:
count: 0
---
kind: infrastructure/machine
provider: any
name: default-k8s-master1
specification:
hostname: k1m1
ip: 10.10.1.148
---
kind: infrastructure/machine
provider: any
name: default-k8s-master2
specification:
hostname: k1m2
ip: 10.10.2.129
---
kind: infrastructure/machine
provider: any
name: default-k8s-master3
specification:
hostname: k1m3
ip: 10.10.3.16
---
kind: infrastructure/machine
provider: any
name: default-k8s-node1
specification:
hostname: k1c1
ip: 10.10.1.208
---
kind: infrastructure/machine
provider: any
name: default-k8s-node2
specification:
hostname: k1c2
ip: 10.10.2.168
As for the design proposal, the simplest solution is to take internal load-balancer (2.1.2) and internal etcd (2.2.2) and merge them together, then carefully observe and tune network traffic comming from haproxy instances for big number of worker nodes.
Example HAProxy config:
global
log /dev/log local0
log /dev/log local1 notice
daemon
defaults
log global
retries 3
maxconn 2000
timeout connect 5s
timeout client 120s
timeout server 120s
frontend k8s
mode tcp
bind 0.0.0.0:3446
default_backend k8s
backend k8s
mode tcp
balance roundrobin
option tcp-check
server k1m1 10.10.1.148:6443 check port 6443
server k1m2 10.10.2.129:6443 check port 6443
server k1m3 10.10.3.16:6443 check port 6443
Example ClusterConfiguration:
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.14.6
controlPlaneEndpoint: "localhost:3446"
apiServer:
extraArgs: # https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/
audit-log-maxbackup: "10"
audit-log-maxsize: "200"
audit-log-path: "/var/log/apiserver/audit.log"
enable-admission-plugins: "AlwaysPullImages,DenyEscalatingExec,NamespaceLifecycle,ServiceAccount,NodeRestriction"
profiling: "False"
controllerManager:
extraArgs: # https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/
profiling: "False"
terminated-pod-gc-threshold: "200"
scheduler:
extraArgs: # https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/
profiling: "False"
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
certificatesDir: /etc/kubernetes/pki
To deploy first master run (Kubernetes 1.14):
$ sudo kubeadm init --config /etc/kubernetes/kubeadm-config.yml --experimental-upload-certs
To add one more master run (Kubernetes 1.14):
$ sudo kubeadm join localhost:3446 \
--token 932b4p.n6teb53a6pd1rinq \
--discovery-token-ca-cert-hash sha256:bafb8972fe97c2ef84c6ac3efd86fdfd76207cab9439f2adbc4b53cd9b8860e6 \
--experimental-control-plane --certificate-key f1d2de1e5316233c078198a610c117c65e4e45726150d63e68ff15915ea8574a
To remove one master run (it will properly cleanup config inside Kubernetes - do not use kubectl delete node):
$ sudo kubeadm reset --force
In later versions (Kubernetes 1.17) this feature became stable and "experimental" word in the commandline paremeters was removed.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Components of control plane such as controller manager or scheduler use endpoints to select the leader. Instance which firstly create the endpoint of this service at the very beginning add annotation to the endpoint with the leader information.
Package leaderelection.go is used for leader election process which leverages above Kubernetes endpoint resource as some sort of LOCK primitive to prevent any follower to create the same endpoint in this same Namespace.
As far as leader election for pods is considered there are possible a few solutions:
coordination.k8s.io group API, it is possible to create in the cluster lease object which can hold the lock for the set of pods. It is necessary to implement a simple code into the application using package leaderelection.go in order to handle the leader election mechanism.Helpful article:
This is the recommended solution, simple, based on existing API group and lease object and not dependent on any external cloud object.
Helpful article:
This solution was recommended by Kubernetes in 2016 and looks a little bit outdated, is complex and require some work.
Helpful articles:
It is not recommended solution since the single object is a potential single point of failure.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
This directory contains design documents related to modularization of LambdaStack.
This represents the current status on: 05-25-2021
:heavy_check_mark: : Available :x: : Not available :heavy_exclamation_mark: Check the notes
| LambdaStack Azure | LambdaStack AWS | Azure BI | AWS BI | ||
|---|---|---|---|---|---|
| Network | Virtual network | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: |
| Private subnets | :heavy_exclamation_mark: | :heavy_exclamation_mark: | :heavy_check_mark: | :heavy_check_mark: | |
| Public subnets | :heavy_exclamation_mark: | :heavy_exclamation_mark: | :heavy_check_mark: | :heavy_check_mark: | |
| Security groups with rules | :heavy_check_mark: | :heavy_check_mark: | :x: | :heavy_check_mark: | |
| Possibility for Bastion host | :x: | :x: | :heavy_check_mark: | :heavy_check_mark: | |
| Possibility to connect to other infra (EKS, AKS) | :x: | :x: | :heavy_check_mark: | :heavy_check_mark: | |
| VM | "Groups" with similar configuration | :heavy_check_mark: | :heavy_exclamation_mark: | :heavy_check_mark: | :heavy_check_mark: |
| Data disks | :x: | :x: | :heavy_check_mark: | :heavy_check_mark: | |
| Shared storage (Azure Files, EFS) | :heavy_check_mark: | :heavy_check_mark: | :x: | :x: | |
| Easy configuration | :heavy_check_mark: | :heavy_check_mark: | :x: | :x: |
This design document presents findings on what are important pieces of modules communication in Dockerized Custom Modules approach described here.
Idea is to have something running and working mimicking real world modules. I used GNU make to perform this. With GNU make I was able to easily implement “run” logic. I also wanted to package everything into docker images to experience real world containers limitations of communication, work directory sharing and other stuff.
First list of modules is presented here:
version: v1
kind: Repository
components:
- name: c1
type: docker
versions:
- version: 0.1.0
latest: true
image: "docker.io/hashicorp/terraform:0.12.28"
workdir: "/terraform"
mounts:
- "/terraform"
commands:
- name: init
description: "initializes terraform in local directory"
command: init
envs:
TF_LOG: WARN
- name: apply
description: "applies terraform in local directory"
command: apply
envs:
TF_LOG: DEBUG
args:
- -auto-approve
... didn't have any dependencies section. We know that some kind of dependencies will be required very soon. I created idea of how to define dependencies between modules in following mind map:

It shows following things:
requires section with possible subsections strong and weak. A strong requirement is one has to be fulfilled for the module to be applied. A weak requirement, on the other hand, is something we can proceed without, but it is in some way connected when present.It's worth co notice each requires rule. I used kubernetes matchExpressions approach as main way of defining dependencies, as one of main usage here would be "version >= X", and we cannot use simple labels matching mechanism without being forced to update all modules using my module every time I release a new version of that module.
I started to implement example docker based mocked modules in tests directory, and I found a 3rd section required: influences. To explain this lets notice one folded module in upper picture: "BareMetalMonitoring". It is Prometheus based module so, as it works in pull mode, it needs to know about addresses of machines it should monitor. Let's imagine following scenario:
BareMetalKafka module,BareMetalKafka module to "inform" in some way BareMetalMonitoring module to monitor IP4, IP5 and IP6 addresses to addition of what it monitors already.This example explains "influences" section. Mocked example is following:
labels:
version: 0.0.1
name: Bare Metal Kafka
short: BMK
kind: stream-processor
core-technology: apache-kafka
provides-kafka: 2.5.1
provides-zookeeper: 3.5.8
requires:
strong:
- - key: kind
operator: eq
values: [infrastructure]
- key: provider,
operator: in,
values:
- azure
- aws
weak:
- - key: kind
operator: eq
values:
- logs-storage
- - key: kind
operator: eq
values:
- monitoring
- key: core-technology
operator: eq
values:
- prometheus
influences:
- - key: kind
operator: eq
values:
- monitoring
As presented there is influences section notifying that "there is something what that I'll do to selected module (if it's present)". I do not feel urge to define it more strictly at this point in time before development. I know that this kind of influences section will be required, but I do not know exactly how it will end up.
During implementation of mocks I found that:
influences section would be requiredvalidate-config (or later just validate) should in fact be planget-state in module container provider as state will be local and shared between modules. In fact some state related operations would be probably implemented on cli wrapper level.audit method which would be extremely important to check if no manual changes were applied to remote infrastructureAs already described there would be 5 main methods required to be implemented by module provider. Those are described in next sections.
That is simple method to display static YAML/JSON (or any kind of structured data) information about the module. In fact information from this method should be exactly the same to what is in repo file section about this module. Example output of metadata method might be:
labels:
version: 0.0.1
name: Bare Metal Kafka
short: BMK
kind: stream-processor
core-technology: apache-kafka
provides-kafka: 2.5.1
provides-zookeeper: 3.5.8
requires:
strong:
- - key: kind
operator: eq
values: [infrastructure]
- key: provider,
operator: in,
values:
- azure
- aws
weak:
- - key: kind
operator: eq
values:
- logs-storage
- - key: kind
operator: eq
values:
- monitoring
- key: core-technology
operator: eq
values:
- prometheus
influences:
- - key: kind
operator: eq
values:
- monitoring
init method main purpose is to jump start usage of module by generating (in smart way) configuration file using information in state. In example Makefile which is stored here you can test following scenario:
make cleanmake init-and-apply-azure-infrastructure./shared/state.yml file:
azi:
status: applied
size: 5
provide-pubips: true
nodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
usedBy: unused
- privateIP: 10.0.0.1
publicIP: 213.1.1.1
usedBy: unused
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
usedBy: unused
- privateIP: 10.0.0.3
publicIP: 213.1.1.3
usedBy: unused
- privateIP: 10.0.0.4
publicIP: 213.1.1.4
usedBy: unused
azi:
status: applied
size: 5
provide-pubips: true
nodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
usedBy: unused
- privateIP: 10.0.0.100 <---- here
publicIP: 213.1.1.100 <---- and here
usedBy: unused
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
usedBy: unused
- privateIP: 10.0.0.3
publicIP: 213.1.1.3
usedBy: unused
- privateIP: 10.0.0.4
publicIP: 213.1.1.4
usedBy: unused
make just-init-kafka./shared/bmk-config.yml
bmk:
size: 3
clusterNodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
- privateIP: 10.0.0.100
publicIP: 213.1.1.100
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
make and-then-apply-kafkaazi:
status: applied
size: 5
provide-pubips: true
nodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
usedBy: bmk
- privateIP: 10.0.0.100
publicIP: 213.1.1.100
usedBy: bmk
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
usedBy: bmk
- privateIP: 10.0.0.3
publicIP: 213.1.1.3
usedBy: unused
- privateIP: 10.0.0.4
publicIP: 213.1.1.4
usedBy: unused
bmk:
status: applied
size: 3
clusterNodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
state: created
- privateIP: 10.0.0.100
publicIP: 213.1.1.100
state: created
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
state: created
So init method is not just about providing "default" config file, but to actually provide "meaningful" configuration file. What is significant here, is that it's very easily testable if that method generates desired state when given different example state files.
plan method is a method to:
This method should be always started before apply by cli wrapper.
General reason to this method is that after we "smart initialized" config, we might have wanted to change some values some way, and then it has to be validated. Another scenario would be influence mechanism I described in Influences section. In that scenario it's easy to imagine that output of BMK module would produce proposed changes to BareMetalMonitoring module or even apply them to its config file. That looks obvious, that automatic "apply" operation on BareMetalMonitoring module is not desired option. So we want to suggest to the user "hey, I applied Kafka module, and usually it influences the configuration of Monitoring module, so go ahead and do plan operation on it to check changes". Or we can even do automatic "plan" operation and show what are those changes.
apply is main "logic" method. Its purpose is to do 2 things:
In fact, you might debate which of those is more important, and I could argue that updating state file is more important.
To perform its operations it uses config file previously validated in plan step.
audit method use case is to check how existing components is "understandable" by component provider logic. A standard situation would be upgrade procedure. We can imagine following history:
BareMetalKafka module in version 0.0.1BareMetalKafka to version 0.0.2 because it provides something I needIn such a scenario, checking if upgrade operation will succeed is critical one, and that is duty of audit operation. It should check on cluster machines if "known" configuration is still "known" (whatever it means for now) and that upgrade operation will not destroy anything.
Another use case for audit method is to reflect manually introduced changes into the configuration (and / or state). If I manually upgraded minor version of some component (i.e.: 1.2.3 to 1.2.4) it's highly possible that it might be easily reflected in state file without any trouble to other configuration.
There are also already known methods which would be required to have most (or maybe all) modules, but are not core to modules communication. Those are purely "internal" module business. Following examples are probably just subset of optional methods.
Provide backup and restore functionalities to protect data and configuration of installed module.
Perform steps to update module components to newer versions with data migration, software re-configuration, infrastructure remodeling and any other required steps.
Operations related to scale up and scale down module components.
All accessible methods would be listed in module metadata as proposed here. That means that it's possible to:
All that means that we would be able to automate modules release process, test it separately and validate its compliance with modules requirements.
We should consider during development phase if and how to present in manifest what are external fields that module requires for apply operation. That way we might be able to catch inconsistencies between what one module provide and what another module require form it.
Another topic to consider is some standardization over modules labeling.
To provide separation of concern on middleware level code we need to have consistent way to produce ansible based modules.
There are following requirements for modules:
Current state of understanding of modules is that we should have at least two commands:
There is possibility also to introduce additional “plan” command with usage of “—diff” and “—check” flags for ansible playbook but:
Module repository should have structure similar to following:
Affected version: 0.4.x
Make lambdastack easier to work on with multiple teams and make it easier to maintain/extend by:
The current monolithic lambdastack will be split up into the following modules.

Shared code between other modules and not executable as standalone. Responsible for:
Module for creating/destroying cloud infrastructure on AWS/Azure/Google... + "Analysing" existing infrastructure. Maybe at a later time we want to split up the different cloud providers into plugins as well.
Functionality (rough outline and subjected to change):
"lambdastack infra template -f outfile.yaml -p awz/azure/google/any (--all)"
"infra template -f outfile.yaml -p awz/azure/google/any (--all)"?
"Infrastructure.template(...)"
Task: Generate a template yaml with lambdastack-cluster definition + possible infra docs when --all is defined
Input: File to output data, provider and possible all flag
Output: outfile.yaml template
"lambdastack infra apply -f data.yaml"
"infra apply -f data.yaml"?
"Infrastructure.apply(...)"
Task: Create/Update infrastucture on AWS/Azure/Google...
Input: Yaml with at least lambdastack-cluster + possible infra docs
Output: manifest, ansible inventory and terrafrom files
"lambdastack infra analyse -f data.yaml"
"infra analyse -f data.yaml"?
"Infrastructure.analyse(...)"
Task: Analysing existing infrastructure
Input: Yaml with at least lambdastack-cluster + possible infra docs
Output: manifest, ansible inventory
"lambdastack infra destroy -b /buildfolder/"
"infra destroy -b /buildfolder/"?
"Infrastructure.destroy(...)"
Task: Destroy all infrastucture on AWS/Azure/Google?
Input: Build folder with manifest and terrafrom files
Output: Deletes the build folder.
Module for creating and tearing down a repo + preparing requirements for offline installation.
Functionality (rough outline and subjected to change):
"lambdastack repo template -f outfile.yaml (--all)"
"repo template -f outfile.yaml (--all)"?
"Repository.template(...)"
Task: Generate a template yaml for a repository
Input: File to output data, provider and possible all flag
Output: outfile.yaml template
"lambdastack repo prepare -os (ubuntu-1904/redhat-7/centos-7)"
"repo prepare -o /outputdirectory/"?
"Repo.prepare(...)"
Task: Create the scripts for downloading requirements for a repo for offline installation for a certain OS.
Input: Os which we want to output the scripts for: (ubuntu-1904/redhat-7/centos-7)
Output: Outputs the scripts scripts
"lambdastack repo create -b /buildfolder/ (--offline /foldertodownloadedrequirements)"
"repo create -b /buildfolder/"?
"Repo.create(...)"
Task: Create the repository on a machine (either by running requirement script or copying already prepared ) and sets up the other VMs/machines to point to said repo machine. (Offline and offline depending on --offline flag)
Input: Build folder with manifest and ansible inventory and posible offline requirements folder for onprem installation.
Output: repository manifest or something only with the location of the repo?
"lambdastack repo teardown -b /buildfolder/"
"repo teardown -b /buildfolder/"?
"Repo.teardown(...)"
Task: Disable the repository and resets the other VMs/machines to their previous state.
Input: Build folder with manifest and ansible inventory
Output: -
Module for applying a command on a component which can contain one or multiple roles. It will take the Ansible inventory to determine which roles should be applied to which component. The command each role can implement are (rough outline and subjected to change):
The apply command should be implemented for every role but the rest is optional. From an implementation perspective each role will be just a seperate folder inside the plugins directory inside the components module folder with command folders which will contain the ansible tasks:
components-|
|-plugins-|
|-master-|
| |-apply
| |-backup
| |-restore
| |-upgrade
| |-test
|
|-node-|
| |-apply
| |-backup
| |-restore
| |-upgrade
| |-test
|
|-kafka-|
| |-apply
| |-upgrade
| |-test
Based on the Ansible inventory and the command we can easily select which roles to apply to which components. For the commands we probably also want to introduce some extra flags to only execute commands for certain components.
Finally we want to add support for an external plugin directory where teams can specify there own role plguins which are not (yet) available inside LambdaStack itself. A feature that can also be used by other teams to more easily start contributing developing new components.
Bundles all executable modules (Infrastructure, Repository, Component) and adds functions to chain them together:
Functionality (rough outline and subjected to change):
"lambdastack template -f outfile.yaml -p awz/azure/google/any (--all)"
"LambdaStack.template(...)"
Task: Generate a template yaml with lambdastack-cluster definition + possible infrastrucure, repo and component configurations
Input: File to output data, provider and possible all flag
Output: outfile.yaml with templates
"lambdastack apply -f input.yaml"
"LambdaStack.template(...)"
Task: Sets up a cluster from start to finish
Input: File to output data, provider and possible all flag
Output: Build folder with manifest, ansible inventory, terrafrom files, component setup.
...
This document tries to compare 3 existing propositions to implement modularization.
To introduce modularization in LambdaStack we identified 3 approaches to consider. Following sections will describe briefly those 3 approaches.
This approach would look following way:
All that means that if we would like to install following stack:
Then steps would need to look somehow like this:
This approach would mean following:
All that means that if we would like to install following stack:
Then steps would need to look somehow like this:
This approach would mean following:
All that means that if we would like to install following stack:
Then steps would need to look somehow like this:
| Question | Dockerized custom modules (DCM) | Terraform providers (TP) | Kubernetes operators (KO) |
|---|---|---|---|
| How much work does it require to package lambdastack to first module? | Customize entrypoint of current image to provide metadata information. | Implement API server in current image to expose it to TP. | Implement ansible operator to handle CR’s and (possibly?) run current image as tasks. |
| Sizes: | 3XL | Too big to handle. We would need to implement just new modules that way. | 5XL |
| How much work does it require to package module CNS? | From kubectl image, provide some parameters, provide CRD’s, provide CR’s | Use (possibly?) terraform-provider-kubernetes. Prepare CRD’s, prepare CR’s. No operator required. | Just deploy Rook CRD’s, operator, CR’s. |
| Sizes: | XXL | XL | XL |
| How much work does it require to package module AKS/EKS? | From terraform, provide some parameters, provide terraform scripts | Prepare terraform scripts. No operator required. | [there is something called rancher/terraform-controller and it tries to be what we need. It’s alpha] Use (possibly?) rancher terraform-controller operator, provide DO module with terraform scripts. |
| Sizes: | XL | L | XXL |
| How would be dependencies handled? | Not defined so far. It seems that using kind of “selectors” to check if modules are installed and in state “applied” or something like this. | Standard terraform dependencies tree. It’s worth to remember that terraform dependencies sometimes work very weird and if you change one value it has to call multiple places. We would need to assess how much dependencies there should be in dependencies. | It seems that embedding all Kubernetes resources into helm charts, and adding dependencies between them could solve a problem. |
| Sizes: | XXL | XL | XXL |
| Would it be possible to install CNS module on LambdaStack Kubernetes in version 0.4.4? | yes | yes | yes |
| If I want to install CNS, how would dependencies be provided? | By selectors mechanism (that is proposition) | By terraform tree | By helm dependencies |
| Let’s assume that in version 0.8.0 of LambdaStack PostgreSQL is migrated to new component (managed not in lambdastack config). How would migration from 0.7.0 to 0.8.0 on existing environments be processed? | Proposition is, that for this kind of operations we can create separate “image” to conduct just that upgrade operation. So for example ls-o0-08-upgrader. It would check that environment v0.7.x had PostgreSQL installed, then it would generate config for new PostgreSQL module, it would initialize that module and it would allow upgrade of lambdastack module to v0.8.x | It doesn’t look like there is a way to do it automatically by terraform. You would need to add new PostgreSQL terraform configuration and import existing state into it, then remove PostgreSQL configuration from old module (while preventing it from deletion of resources). If you are advanced terraform user it still might be tricky. I’m not sure if we are able to handle it for user. | We would need to implement whole functionality in operator. Basically very similar to DCM scenario, but triggered by CR change. |
| Sizes: | XXL | Unknown | 3XL |
| Where would module store it’s configuration? | Locally in ~/.e/ directory. In future we can implement remote state (like terraform remote backend) | All terraform options. | As Kubernetes CR. |
| How would status of components be gathered by module? | We would need to implement it. | Standard terraform output and datasource mechanisms. | Status is continuously updated by operator in CR so there it is. |
| Sizes: | XL | XS | S |
| How would modules pass variables between each other? | CLI wrapper should be aware that one module needs other module output and it should call module1 get-output and pass that json or part of it to module2 apply |
Standard terraform. | Probably by Config resources. But not defined. |
| Sizes: | XXL | XS | XL |
| How would upstream module notify downstream that something changed in it’s values? | We would need to implement it. | Standard terraform tree update. Too active changes in a tree should be considered here as in dependencies. | It’s not clear. If upstream module can change downstream Config resource (what seems to be ridiculous idea) than it’s simple. Other way is that downstream periodically checks upstream Config for changes, but that introduces problems if we use existing operators. |
| Sizes: | XXL | XL | XXL |
| Sizes summary: | 1 3XL, 5 XXL, 2 XL | 1 Too big, 1 Unknown, 3 XL, 1 L, 2 XS | 1 5XL, 1 3XL, 3 XXL, 2 XL, 1 S |
DCM and KO are interesting. TP is too strict and not elastic enough.
DCM has the smallest standard deviation when you look at task sizes. It indicates the smallest risk. TP is on the opposite side of list with the biggest estimations and some significant unknowns.
If we were to consider only cloud provided resources TP is the fastest way. Since we need to provide multiple different resources and work on-prem it is not that nice. KO approach looks like something interesting, but it might be hard at the beginning. DCM looks like simplest to implement with backward compatibility.
DCM has significant risk of “custom development”. KO has risks related to requirement to use operator-framework and its concept, since very beginning of lsc work. TP has huge risks related to on-prem operational overhead.
Risks related to DCM are smallest and learning curve looks best. We would also be able to be backward compatible in relatively simple way.
DCM looks like desired approach.
Due to ongoing modularization process and introduction of middleware modules we need to decide how modules would obtain required dependencies for “offline” mode.
This document will describe installation and upgrade modes and will discuss ways to implement whole process considered during design process.
Each module has access to the “/shared” directory. Most wanted way to use modules is via “e” command line app.
There are 2 main identified ways (each with 2 mutations) to install LambdaStack cluster.
Following diagrams present high-level overview of those 4 scenarios:




Described in the previous section scenarios show that there is couple machine roles identified in installation process. Following list explains those roles in more details.
This section describes identified ways to provide dependencies to cluster. There is 6 identified ways. All of them are described in following subsections with pros and cons.
Docker image for each module has all required binaries embedded in itself during build process.
There is separate docker image with all required binaries for all modules embedded in itself during build process.
There is separate “dependencies” image for each module containing just dependencies.
Each module has “download requirements” step and downloads requirements to some directory.
Each module has “download requirements” step and downloads requirements to docker named volume.
Each module contains “requirements” section in its configuration, but there is one single module downloading requirements for all modules.
Its visible in offline scenarios that "export" process is as important as "download" process. For offline scenarios "export" has to cover following elements:
All those elements have to be packaged to archive to be transferred to the clusters Repository machine.
After all elements are packaged and transferred to Repository machine they have to be imported into Repository. It is current impression that repository module would be responsible for import operation.
In this document we provide high level definition how to approach offline installation and upgrade. Current understanding is:
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.4.x
Provide upgrade functionality for LambdaStack so Kubernetes and other components can be upgraded when working offline.
LambdaStack should be upgradeable when there is no internet connection. It requires all packages and dependencies to be downloaded on machine that has internet connection and then moved to air-gap server.
lsupgrade -b /path/to/build/dir
Where -b is path to build folder that contains Ansible inventory.
MVP for upgrade function will contain Kubernetes upgrade procedure to the latest supported version of Kubernetes. Later it will be extended to all other LambdaStack components.

lsupgrade application or module takes build path location (directory path that contains Ansible inventory file).
First part of upgrade execution is to download/upload packages to repository so new packages will exist and be ready for upgrade process. When repository module will finish its work then upgrade Ansible playbooks will be executed.
Upgrade application/module shall implement following functions:
apply it will execute upgrade--plan where there will be no changes made to the cluster - it will return list of changes that will be made during upgrade execution.Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
This document aim is to initialize evaluation of possible persistence layers for Kubernetes cluster (a.k.a. Cloud Native Storage, CNS) in various setups.
There is need to provide persistence layer for Kubernetes cluster installed as LambdaStack containers orchestrator. We need to consider performance of persistence layer as well. There is possibility to utilize external persistence solutions in future with managed Kubernetes clusters installations, but that is out of scope of this document.
This section proposes Objectives and Key Results for CNS.
As for now I can see following solutions:
We should review more solutions presented here.
There are numerous other solutions possible to use over CSI, but they require separate management.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Affected version: 0.5.x
Deploying PostgreSQL in a high-demand environment requires reliability and scalability. Even if you don't scale your infrastructure and you work only on one database node at some time you will reach connection limit. Number of connection to Postgres database is limited and is defined by max_connection parameter. It's possible to extend this limit, but you shouldn't do that reckless - this depends of machine resources.
LambdaStack delivers solution to build master - slave database nodes configuration. This means that application by default connects to master database. Database replica is updated immediately when master is modified.
Minimal solution to meet with client requirements is to install Pgbouncer on database master node to maintain connection pool. This will partially solve problem with exceeded connection limits. All applications need to be reconfigure to connect not directly with database, but with Pgbouncer service which will redirect connection to database master. This solution we can deliver fast and it's quite easy to implement.

Above chart presents high availability database cluster. Pgbouncer and Pgpool are located in separate pods in Kubernetes cluster. PGbouncer maintains connection pool and redirect them to pgpool which is responsible for connection pooling between master and slave node. This allows to redirect write operations to master database node and read (select) operations to slave database node(s). Additionally repmgr takes care of databases availability (must be installed on every database node), and promote subsequent slave node to be master when previous master went down.
Affected version: 0.5.x
Provide functionality to perform auditing of operations performed on PostgreSQL.
For SOX and other regulations compliance platform should provide auditing function for PostgreSQL database. This should be set via LambdaStack automation in LambdaStack configuration yaml.
In configuration for PostgreSQL we can add additional parameters, that could configure additional properties of PostgreSQL. Config similar to proposed below can be used to configure auditing with using pgaudit.
kind: configuration/postgresql
title: PostgreSQL
name: default
specification:
...
extensions:
pgaudit:
enabled: false
shared_preload_libraries:
- pgaudit
config_file_parameters:
pgaudit.log: 'all, -misc'
log_connections: 'on'
log_disconnections: 'on'
log_line_prefix: "'%m [%p] %q%u@%d,host=%h '"
log_statement: 'none'
...
Add to PostgreSQL configuration additional settings, that would install and configure pgaudit extension. For RHEL we use PostgreSQL installed from Software Collections repository, which doesn't provide pgaudit package for PostgreSQL versions older than 12. For this reason, on RHEL pgaudit will be installed from PostgreSQL repository.
Some of these date back to older versions but efforts are made to keep the most important - sometimes :)
Configuration data is stored in location: /var/lib/ceph Storage data is located on dedicated devices which are connected via OSD pods.
Replication: Like Ceph Clients, Ceph OSD Daemons use the CRUSH algorithm, but the Ceph OSD Daemon uses it to compute where replicas of objects should be stored (and for rebalancing). In a typical write scenario, a client uses the CRUSH algorithm to compute where to store an object, maps the object to a pool and placement group, then looks at the CRUSH map to identify the primary OSD for the placement group. The client writes the object to the identified placement group in the primary OSD. Then, the primary OSD with its own copy of the CRUSH map identifies the secondary and tertiary OSDs for replication purposes, and replicates the object to the appropriate placement groups in the secondary and tertiary OSDs (as many OSDs as additional replicas), and responds to the client once it has confirmed the object was stored successfully.
Since version 1.4 lvm package present on the nodes is required. It applies for AWS machines (not tested on Ubuntu) Example installation command:
RHEL:
yum install lvm2 -y
https://rook.io/docs/rook/v1.4/ceph-storage.html
Rook ceph cluster can be easily deployed using example default definitions from GH repo:
git clone --single-branch --branch release-1.4 https://github.com/rook/rook.git
open location:
rook/cluster/examples/kubernetes/ceph
and list examples:
-rw-r--r--. 1 root root 395 Jul 28 13:00 ceph-client.yaml
-rw-r--r--. 1 root root 1061 Jul 28 13:00 cluster-external-management.yaml
-rw-r--r--. 1 root root 886 Jul 28 13:00 cluster-external.yaml
-rw-r--r--. 1 root root 5300 Jul 28 13:00 cluster-on-pvc.yaml
-rw-r--r--. 1 root root 1144 Jul 28 13:00 cluster-test.yaml
-rw-r--r--. 1 root root 10222 Jul 28 14:47 cluster.yaml
-rw-r--r--. 1 root root 2143 Jul 28 13:00 common-external.yaml
-rw-r--r--. 1 root root 44855 Jul 28 13:00 common.yaml
-rw-r--r--. 1 root root 31424 Jul 28 13:00 create-external-cluster-resources.py
-rw-r--r--. 1 root root 2641 Jul 28 13:00 create-external-cluster-resources.sh
drwxr-xr-x. 5 root root 47 Jul 28 13:00 csi
-rw-r--r--. 1 root root 363 Jul 28 13:00 dashboard-external-https.yaml
-rw-r--r--. 1 root root 362 Jul 28 13:00 dashboard-external-http.yaml
-rw-r--r--. 1 root root 839 Jul 28 13:00 dashboard-ingress-https.yaml
-rw-r--r--. 1 root root 365 Jul 28 13:00 dashboard-loadbalancer.yaml
-rw-r--r--. 1 root root 1554 Jul 28 13:00 direct-mount.yaml
-rw-r--r--. 1 root root 3308 Jul 28 13:00 filesystem-ec.yaml
-rw-r--r--. 1 root root 780 Jul 28 13:00 filesystem-test.yaml
-rw-r--r--. 1 root root 4286 Jul 28 13:00 filesystem.yaml
drwxr-xr-x. 2 root root 115 Jul 28 13:00 flex
-rw-r--r--. 1 root root 4530 Jul 28 13:00 import-external-cluster.sh
drwxr-xr-x. 2 root root 183 Jul 28 13:00 monitoring
-rw-r--r--. 1 root root 1409 Jul 28 13:00 nfs.yaml
-rw-r--r--. 1 root root 495 Jul 28 13:00 object-bucket-claim-delete.yaml
-rw-r--r--. 1 root root 495 Jul 28 13:00 object-bucket-claim-retain.yaml
-rw-r--r--. 1 root root 2306 Jul 28 13:00 object-ec.yaml
-rw-r--r--. 1 root root 2313 Jul 28 13:00 object-openshift.yaml
-rw-r--r--. 1 root root 698 Jul 28 13:00 object-test.yaml
-rw-r--r--. 1 root root 488 Jul 28 13:00 object-user.yaml
-rw-r--r--. 1 root root 3573 Jul 28 13:00 object.yaml
-rw-r--r--. 1 root root 19075 Jul 28 13:00 operator-openshift.yaml
-rw-r--r--. 1 root root 18199 Jul 28 13:00 operator.yaml
-rw-r--r--. 1 root root 1080 Jul 28 13:00 pool-ec.yaml
-rw-r--r--. 1 root root 508 Jul 28 13:00 pool-test.yaml
-rw-r--r--. 1 root root 1966 Jul 28 13:00 pool.yaml
-rw-r--r--. 1 root root 410 Jul 28 13:00 rgw-external.yaml
-rw-r--r--. 1 root root 2273 Jul 28 13:00 scc.yaml
-rw-r--r--. 1 root root 682 Jul 28 13:00 storageclass-bucket-delete.yaml
-rw-r--r--. 1 root root 810 Jul 28 13:00 storageclass-bucket-retain-external.yaml
-rw-r--r--. 1 root root 681 Jul 28 13:00 storageclass-bucket-retain.yaml
-rw-r--r--. 1 root root 1251 Jul 28 13:00 toolbox.yaml
-rw-r--r--. 1 root root 6089 Jul 28 13:00 upgrade-from-v1.2-apply.yaml
-rw-r--r--. 1 root root 14957 Jul 28 13:00 upgrade-from-v1.2-crds.yaml
After creating basic setup (common.yaml, operator.yaml, cluster.yaml) install toolbox (toolbox.yaml) as well for checking the ceph cluster status.
IMPORTANT:
ensure the osd container is created and running. It requires a storage device to be available on the nodes.
During cluster startup it searches for the devices available and creates osd containers for them.
Kubelet nodes have to use a default flag enable-controller-attach-detach set to true. Otherwise PVC will not attach to the pod.
Location of the file where we can find the flag:
/var/lib/kubelet/kubeadm-flags.env
on every worker nodes with kubelet. After that we need to restart kubelet:
systemctl restart kubelet
If cluster is working we can create a storage which can be one of a type:
Block: Create block storage to be consumed by a pod
Object: Create an object store that is accessible inside or outside the
Kubernetes cluster
Shared Filesystem: Create a filesystem to be shared across multiple pods
Eg.
-> filesystem.yaml and then
-> storageclass.yaml
CRD:
There are 2 ways cluster can be set up:
PVC example:
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rbd-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: rook-ceph-block
Application using PVC example:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgresql
namespace: default
labels:
k8s-app: postgresql
kubernetes.io/cluster-service: "true"
spec:
replicas: 1
selector:
matchLabels:
k8s-app: postgresql
template:
metadata:
labels:
k8s-app: postgresql
kubernetes.io/cluster-service: "true"
spec:
containers:
- name: postgres
image: postgres:10.1
ports:
- containerPort: 5432
env:
- name: POSTGRES_DB
value: dbdb
- name: POSTGRES_USER
value: test
- name: POSTGRES_PASSWORD
value: test
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
volumeMounts:
- mountPath: "/var/lib/postgresql/data"
name: "image-store"
volumes:
- name: image-store
persistentVolumeClaim:
claimName: rbd-pvc
readOnly: false
Choosing Block Storage which allows a single pod to mount storage, be aware that if one node where Your application is hosted will crash, all the pods located on the crashed node will go into terminating state and application will be unavailable since terminating pods blocking access to ReadWriteOnce volume and new pod can't create. You have to manually delete volume attachment or use CephFS instead of RBD.
Related discussion: https://stackoverflow.com/questions/61186199/why-does-kubernetes-not-terminating-pods-after-a-node-crash
Step by step procedure for setting environment up and testing it (together with backup/restore) is available in the following repo: https://github.com/mkyc/k8s-rook-ceph
Good starting point:
https://rook.io/docs/rook/v1.4/ceph-quickstart.html
Toolbox for debugging:
https://rook.io/docs/rook/v1.4/ceph-toolbox.html
Filesystem storage:
https://rook.io/docs/rook/v1.4/ceph-filesystem.html
Custom Resource Definitions:
https://rook.io/docs/rook/v1.4/ceph-cluster-crd.html
Add/remove osd nodes: https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/2/html/administration_guide/adding_and_removing_osd_nodes
Useful rook ceph guide: https://www.cloudops.com/2019/05/the-ultimate-rook-and-ceph-survival-guide/
CHANGELOG-XX.XX.XX of a given versionThese are always in a specific format and in ascending order
CHANGELOG for v1.3CHANGELOG for v1.4lsio shell script in root directory of repo to easily launch the docker image or pull it down and launchbuild-docker-image.sh (in .devcontainer) that makes it easier to build a LambdaStack Docker Image. This only stores it in your default local registry on your machinepush-docker-image-to-registry.sh (in .devcontainer) to push your LambdaStack image to the LambdaStack Docker Hub public registry. Run build-docker-image.sh and then run push-docker-image-to-registry.sh to build and push to the public registryuse_public_ips: False to use_public_ips: True. This makes it easier to jumpstart and begin learning BUT it creates a security flaw since all IPs should be private and you access to the clusters should be secured via VPN or direct connectHere is a quick reference to the Kubernetes documentation.
Affected version: 0.7.x
This document is extension of high level design doc: LambdaStack backup design document and describes more detailed, operational point-of-view of this case. Document does not include Kubernetes and Kafka stack
Example use:
lambdastack backup -b build_dir -t target_path
Where -b is path to build folder that contains Ansible inventory and -t contains target path to store backup.
backup runs tasks from ansible backup role
build_dir contains cluster's ansible inventory
target_path location to store backup, see Storage section below.
Consider to add disclaimer for user to check whether backup location has enough space to store whole backup.
Location created on master node to keep backup files. This location might be used to mount external storage, like:
In cloud configuration blob or S3 storage might be mounted directly on every machine in cluster and can be configured by LambdaStack. For on-prem installation it's up to administrator to attach external disk to backup location on master node. This location should be shared with other machines in cluster as NFS.
Main role for backup contains ansible tasks to run backups on cluster components.
Elasticsearch & Kibana
1.1. Create local location where snapshot will be stored: /tmp/snapshots 1.2. Update elasticsearch.yml file with backup location
```bash
path.repo: ["/tmp/backup/elastic"]
```
1.3. Reload configuration 1.4. Register repository:
curl -X PUT "https://host_ip:9200/_snapshot/my_backup?pretty" \n
-H 'Content-Type: application/json' -d '
{
"type": "fs",
"settings": {
"location": "/tmp/backup/elastic"
}
}
'
1.5. Take snapshot:
curl -X GET "https://host_ip:9200/_snapshot/my_repository/1" \n
-H 'Content-Type: application/json'
This command will create snapshot in location sent in step 1.2
1.5. Backup restoration:
curl -X POST "https://host_ip:9200/_snapshot/my_repository/2/_restore" -H 'Content-Type: application/json'
Consider options described in opendistro documentation
1.6. Backup configuration files:
/etc/elasticsearch/elasticsearch.yml
/etc/kibana/kibana.yml
Monitoring
2.1.1 Prometheus data
Prometheus delivers solution to create data snapshot. Admin access is required to connect to application api with admin privileges. By default admin access is disabled, and needs to be enabled before snapshot creation.
To enable admin access --web.enable-admin-api needs to be set up while starting service:
service configuration:
/etc/systemd/system/prometheus.service
systemctl daemon-reload
systemctl restart prometheus
Snapshot creation:
curl -XPOST http://localhost:9090/api/v1/admin/tsdb/snapshot
By default snapshot is saved in data directory, which is configured in Prometheus service configuration file as flag:
--storage.tsdb.path=/var/lib/prometheus
Which means that snapshot directory is creted under:
/var/lib/prometheus/snapshots/yyyymmddThhmmssZ-*
After snapshot admin access throuh API should be reverted.
Snapshot restoration process is just pointing --storage.tsdb.path parameter to snaphot location and restart Prometheus.
2.1.2. Prometheus configuration
Prometheus configurations are located in:
/etc/prometheus
2.2. Grafana backup and restore
Copy files from grafana home folder do desired location and set up correct permissions:
location: /var/lib/grafana
content:
- dashboards
- grafana.db
- plugins
- png (contains renederes png images - not necessary to back up)
2.3 Alert manager
Configuration files are located in:
/etc/prometheus
File alertmanager.yml should be copied in step 2.1.2 if exists
PostgreSQL
3.1. Basically PostgreSQL delivers two main tools for backup creation: pg_dump and pg_dumpall
pg_dump create dump of selected database:
pg_dump dbname > dbname.bak
pg_dumpall - create dump of all databases of a cluster into one script. This dumps also global objects that are common to all databases like: users, groups, tablespaces and properties such as access permissions (pg_dump does not save these objects)
pg_dumpall > pg_backup.bak
3.2. Database resotre: psql or pg_restore:
psql < pg_backup.bak
pgrestore -d dbname db_name.bak
3.3. Copy configuration files:
/etc/postgresql/10/main/* - configuration files
.pgpass - authentication credentials
RabbitMQ
4.1. RabbitMQ definicions might be exported using API (rabbitmq_management plugins need to be enabled):
rabbitmq-plugins enable rabbitmq_management
curl -v -X GET http://localhost:15672/api/definitions -u guest:guest -H "content-type:application/json" -o json
Import backed up definitions:
curl -v -X POST http://localhost:15672/api/definitions -u guest:guest -H "content-type:application/json" --data backup.json
or add backup location to configuration file and restart rabbitmq:
management.load_definitions = /path/to/backup.json
4.2 Backing up RabbitMQ messages To back up messages RabbitMQ must be stopped. Copy content of rabbitmq mnesia directory:
RABBITMQ_MNESIA_BASE
ubuntu:
/var/lib/rabbitmq/mnesia
Restoration: place these files to similar location
4.3 Backing up configuration:
Copy /etc/rabbitmq/rabbitmq.conf file
HAProxy
Copy /etc/haproxy/ to backup location
Copy certificates stored in /etc/ssl/haproxy/ location.
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| apr | + | + | |
| apr-util | + | + | |
| centos-logos | + | ? | |
| createrepo | + | + | |
| deltarpm | + | + | |
| httpd | + | + | |
| httpd-tools | + | + | |
| libxml2-python | + | + | |
| mailcap | + | + | |
| mod_ssl | + | + | |
| python-chardet | + | + | |
| python-deltarpm | + | + | |
| python-kitchen | + | + | |
| yum-utils | + | + | |
| audit | + | + | |
| bash-completion | + | + | |
| c-ares | + | --- | |
| ca-certificates | + | + | |
| cifs-utils | + | + | |
| conntrack-tools | + | + | |
| containerd.io | + | + | |
| container-selinux | + | ? | |
| cri-tools-1.13.0 | + | ? | |
| curl | + | + | |
| dejavu-sans-fonts | + | + | |
| docker-ce-19.03.14 | + | + | |
| docker-ce-cli-19.03.14 | + | + | |
| ebtables | + | + | |
| elasticsearch-curator-5.8.3 | --- | elasticsearch-curator-3.5.1 (from separate repo v3) | + |
| elasticsearch-oss-7.9.1 | + | + | |
| erlang-23.1.4 | + | + | |
| ethtool | + | + | |
| filebeat-7.9.2 | + | + | |
| firewalld | + | + | |
| fontconfig | + | + | |
| fping | + | + | |
| gnutls | + | + | |
| grafana-7.3.5 | + | + | |
| gssproxy | + | + | |
| htop | + | + | |
| iftop | + | + | |
| ipset | + | + | |
| java-1.8.0-openjdk-headless | + | + | |
| javapackages-tools | + | + | |
| jq | + | + | |
| libini_config | + | + | |
| libselinux-python | + | + | |
| libsemanage-python | + | + | |
| libX11 | + | + | |
| libxcb | + | + | |
| libXcursor | + | + | |
| libXt | + | + | |
| logrotate | + | + | |
| logstash-oss-7.8.1 | + | + | |
| net-tools | + | + | |
| nfs-utils | + | + | |
| nmap-ncat | + | ? | |
| opendistro-alerting-1.10.1* | + | + | |
| opendistro-index-management-1.10.1* | + | + | |
| opendistro-job-scheduler-1.10.1* | + | + | |
| opendistro-performance-analyzer-1.10.1* | + | + | |
| opendistro-security-1.10.1* | + | + | |
| opendistro-sql-1.10.1* | + | + | |
| opendistroforelasticsearch-kibana-1.10.1* | --- | opendistroforelasticsearch-kibana-1.13.0 | + |
| openssl | + | + | |
| perl | + | + | |
| perl-Getopt-Long | + | + | |
| perl-libs | + | + | |
| perl-Pod-Perldoc | + | + | |
| perl-Pod-Simple | + | + | |
| perl-Pod-Usage | + | + | |
| pgaudit12_10 | + | --- | |
| pgbouncer-1.10.* | --- | --- | |
| pyldb | + | + | |
| python-firewall | + | + | |
| python-kitchen | + | + | |
| python-lxml | + | + | |
| python-psycopg2 | + | + | |
| python-setuptools | + | ? | |
| python-slip-dbus | + | + | |
| python-ipaddress | + | ? | |
| python-backports | + | ? | |
| quota | + | ? | |
| rabbitmq-server-3.8.9 | + | + | |
| rh-haproxy18 | --- | --- | |
| rh-haproxy18-haproxy-syspaths | --- | --- | |
| postgresql10-server | + | + | |
| repmgr10-4.0.6 | --- | --- | |
| samba-client | + | + | |
| samba-client-libs | + | + | |
| samba-common | + | + | |
| samba-libs | + | + | |
| sysstat | + | + | |
| tar | + | + | |
| telnet | + | + | |
| tmux | + | + | |
| urw-base35-fonts | + | + | |
| unzip | + | + | |
| vim-common | + | + | |
| vim-enhanced | + | + | |
| wget | + | + | |
| xorg-x11-font-utils | + | + | |
| xorg-x11-server-utils | + | + | |
| yum-plugin-versionlock | + | + | |
| yum-utils | + | + | |
| rsync | + | + | |
| kubeadm-1.18.6 | + | + | |
| kubectl-1.18.6 | + | + | |
| kubelet-1.18.6 | + | + | |
| kubernetes-cni-0.8.6-0 | + | + | |
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| haproxy:2.2.2-alpine | + | arm64v8/haproxy | + |
| kubernetesui/dashboard:v2.3.1 | + | + | |
| kubernetesui/metrics-scraper:v1.0.7 | + | + | |
| registry:2 | + | ||
| hashicorp/vault-k8s:0.7.0 | --- | https://hub.docker.com/r/moikot/vault-k8s / custom build | --- |
| vault:1.7.0 | + | --- | |
| apacheignite/ignite:2.9.1 | --- | https://github.com/apache/ignite/tree/master/docker/apache-ignite / custom build | --- |
| bitnami/pgpool:4.1.1-debian-10-r29 | --- | --- | |
| brainsam/pgbouncer:1.12 | --- | --- | |
| istio/pilot:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/proxyv2:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/operator:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| jboss/keycloak:4.8.3.Final | --- | + | |
| jboss/keycloak:9.0.0 | --- | + | |
| rabbitmq:3.8.9 | + | + | |
| coredns/coredns:1.5.0 | + | + | |
| quay.io/coreos/flannel:v0.11.0 | + | + | |
| calico/cni:v3.8.1 | + | + | |
| calico/kube-controllers:v3.8.1 | + | + | |
| calico/node:v3.8.1 | + | + | |
| calico/pod2daemon-flexvol:v3.8.1 | + | + | |
| k8s.gcr.io/kube-apiserver:v1.18.6 | + | k8s.gcr.io/kube-apiserver-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-controller-manager:v1.18.6 | + | k8s.gcr.io/kube-controller-manager-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-scheduler:v1.18.6 | + | k8s.gcr.io/kube-scheduler-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-proxy:v1.18.6 | + | k8s.gcr.io/kube-proxy-arm64:v1.18.6 | + |
| k8s.gcr.io/coredns:1.6.7 | --- | coredns/coredns:1.6.7 | + |
| k8s.gcr.io/etcd:3.4.3-0 | + | k8s.gcr.io/etcd-arm64:3.4.3-0 | + |
| k8s.gcr.io/pause:3.2 | + | k8s.gcr.io/pause-arm64:3.2 | + |
Build multi arch image for Keycloak 9:
Clone repo: https://github.com/keycloak/keycloak-containers/
Checkout tag: 9.0.0
Change dir to: keycloak-containers/server
Create new builder: docker buildx create --name mybuilder
Switch to builder: docker buildx use mybuilder
Inspect builder and make sure it supports linux/amd64, linux/arm64: docker buildx inspect --bootstrap
Build and push container: docker buildx build --platform linux/amd64,linux/arm64 -t repo/keycloak:9.0.0 --push .
Additional info:
https://hub.docker.com/r/jboss/keycloak/dockerfile
https://github.com/keycloak/keycloak-containers/
https://docs.docker.com/docker-for-mac/multi-arch/
| Component name | Roles |
|---|---|
| Repository | repository image-registry node-exporter firewall filebeat docker |
| Kubernetes | kubernetes-master kubernetes-node applications node-exporter haproxy_runc kubernetes_common |
| Kafka | zookeeper jmx-exporter kafka kafka-exporter node-exporter |
| ELK (Logging) | logging elasticsearch elasticsearch_curator logstash kibana node-exporter |
| Exporters | node-exporter kafka-exporter jmx-exporter haproxy-exporter postgres-exporter |
| PostgreSQL | postgresql postgres-exporter node-exporter |
| Keycloak | applications |
| RabbitMQ | rabbitmq node-exporter |
| HAProxy | haproxy haproxy-exporter node-exporter haproxy_runc |
| Monitoring | prometheus grafana node-exporter |
Except above table, components require following roles to be checked:
Affected version: 0.5.x
Provide backup functionality for LambdaStack - cluster created using lambdastack tool.
Creating snapshots of disks for all elements in environment created on cloud.
lsbackup --disks-snapshot -f path_to_data_yaml
Where -f is path to data yaml file with configuration of environment. --disks-snapshot informs about option that will create whole disks snapshot.
User/background service/job executes lsbackup (code name) application. Application takes parameters:
-f: path to data yaml file with configuration of environment.--disks-snapshot: option to create whole disk snapshotTool when executed takes resource group from file provided with -f flag and create snapshots of all elements in resource group.
Tool also produces metadata file that describes backup with time and the name of disks for which snapshot has been created.
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| apr | + | + | |
| apr-util | + | + | |
| redhat-logos | + | ? | |
| createrepo | + | + | |
| deltarpm | + | + | |
| httpd | + | + | |
| httpd-tools | + | + | |
| libxml2-python | + | + | |
| mailcap | + | + | |
| mod_ssl | + | + | |
| python-chardet | + | + | |
| python-deltarpm | + | + | |
| python-kitchen | + | + | |
| yum-utils | + | + | |
| audit | + | + | |
| bash-completion | + | + | |
| c-ares | + | --- | |
| ca-certificates | + | + | |
| cifs-utils | + | + | |
| conntrack-tools | + | + | |
| containerd.io | + | + | |
| container-selinux | + | ? | |
| cri-tools-1.13.0 | + | ? | |
| curl | + | + | |
| dejavu-sans-fonts | + | + | |
| docker-ce-19.03.14 | + | + | |
| docker-ce-cli-19.03.14 | + | + | |
| ebtables | + | + | |
| elasticsearch-curator-5.8.3 | --- | elasticsearch-curator-3.5.1 (from separate repo v3) | + |
| elasticsearch-oss-7.10.2 | + | + | |
| ethtool | + | + | |
| filebeat-7.9.2 | + | + | |
| firewalld | + | + | |
| fontconfig | + | + | |
| fping | + | + | |
| gnutls | + | + | |
| grafana-7.3.5 | + | + | |
| gssproxy | + | + | |
| htop | + | + | |
| iftop | + | + | |
| ipset | + | + | |
| java-1.8.0-openjdk-headless | + | + | |
| javapackages-tools | + | + | |
| jq | + | + | |
| libini_config | + | + | |
| libselinux-python | + | + | |
| libsemanage-python | + | + | |
| libX11 | + | + | |
| libxcb | + | + | |
| libXcursor | + | + | |
| libXt | + | + | |
| logrotate | + | + | |
| logstash-oss-7.8.1 | + | + | |
| net-tools | + | + | |
| nfs-utils | + | + | |
| nmap-ncat | + | ? | |
| opendistro-alerting-1.13.1* | + | + | |
| opendistro-index-management-1.13.1* | + | + | |
| opendistro-job-scheduler-1.13.1* | + | + | |
| opendistro-performance-analyzer-1.13.1* | + | + | |
| opendistro-security-1.13.1* | + | + | |
| opendistro-sql-1.13.1* | + | + | |
| opendistroforelasticsearch-kibana-1.13.1* | + | + | |
| unixODBC | + | + | |
| openssl | + | + | |
| perl | + | + | |
| perl-Getopt-Long | + | + | |
| perl-libs | + | + | |
| perl-Pod-Perldoc | + | + | |
| perl-Pod-Simple | + | + | |
| perl-Pod-Usage | + | + | |
| pgaudit12_10 | ? | --- | |
| pgbouncer-1.10.* | ? | --- | |
| policycoreutils-python | + | + | |
| pyldb | + | + | |
| python-cffi | + | + | |
| python-firewall | + | + | |
| python-kitchen | + | + | |
| python-lxml | + | + | |
| python-psycopg2 | + | + | |
| python-pycparser | + | + | |
| python-setuptools | + | ? | |
| python-slip-dbus | + | + | |
| python-ipaddress | + | ? | |
| python-backports | + | ? | |
| quota | + | ? | |
| rabbitmq-server-3.8.9 | + | + | |
| rh-haproxy18 | --- | --- | |
| rh-haproxy18-haproxy-syspaths | --- | --- | |
| postgresql10-server | + | + | |
| repmgr10-4.0.6 | --- | --- | |
| samba-client | + | + | |
| samba-client-libs | + | + | |
| samba-common | + | + | |
| samba-libs | + | + | |
| sysstat | + | + | |
| tar | + | + | |
| telnet | + | + | |
| tmux | + | + | |
| urw-base35-fonts | ? | Need to be verified, no package found | + |
| unzip | + | + | |
| vim-common | + | + | |
| vim-enhanced | + | + | |
| wget | + | + | |
| xorg-x11-font-utils | + | + | |
| xorg-x11-server-utils | + | + | |
| yum-plugin-versionlock | + | + | |
| yum-utils | + | + | |
| rsync | + | + | |
| kubeadm-1.18.6 | + | + | |
| kubectl-1.18.6 | + | + | |
| kubelet-1.18.6 | + | + | |
| kubernetes-cni-0.8.6-0 | + | + | |
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| haproxy:2.2.2-alpine | + | arm64v8/haproxy | + |
| kubernetesui/dashboard:v2.3.1 | + | + | |
| kubernetesui/metrics-scraper:v1.0.7 | + | + | |
| registry:2 | + | ||
| hashicorp/vault-k8s:0.7.0 | --- | https://hub.docker.com/r/moikot/vault-k8s / custom build | --- |
| vault:1.7.0 | + | --- | |
| lambdastack/keycloak:9.0.0 | + | custom build | + |
| bitnami/pgpool:4.1.1-debian-10-r29 | --- | --- | |
| brainsam/pgbouncer:1.12 | --- | --- | |
| istio/pilot:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/proxyv2:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/operator:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| jboss/keycloak:4.8.3.Final | --- | --- | |
| jboss/keycloak:9.0.0 | --- | --- | |
| rabbitmq:3.8.9 | --- | --- | |
| coredns/coredns:1.5.0 | + | + | |
| quay.io/coreos/flannel:v0.11.0 | + | + | |
| calico/cni:v3.8.1 | + | + | |
| calico/kube-controllers:v3.8.1 | + | + | |
| calico/node:v3.8.1 | + | + | |
| calico/pod2daemon-flexvol:v3.8.1 | + | + | |
| k8s.gcr.io/kube-apiserver:v1.18.6 | + | k8s.gcr.io/kube-apiserver-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-controller-manager:v1.18.6 | + | k8s.gcr.io/kube-controller-manager-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-scheduler:v1.18.6 | + | k8s.gcr.io/kube-scheduler-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-proxy:v1.18.6 | + | k8s.gcr.io/kube-proxy-arm64:v1.18.6 | + |
| k8s.gcr.io/coredns:1.6.7 | --- | coredns/coredns:1.6.7 | + |
| k8s.gcr.io/etcd:3.4.3-0 | + | k8s.gcr.io/etcd-arm64:3.4.3-0 | + |
| k8s.gcr.io/pause:3.2 | + | k8s.gcr.io/pause-arm64:3.2 | + |
Build multi arch image for Keycloak 9:
Clone repo: https://github.com/keycloak/keycloak-containers/
Checkout tag: 9.0.0
Change dir to: keycloak-containers/server
Create new builder: docker buildx create --name mybuilder
Switch to builder: docker buildx use mybuilder
Inspect builder and make sure it supports linux/amd64, linux/arm64: docker buildx inspect --bootstrap
Build and push container: docker buildx build --platform linux/amd64,linux/arm64 -t repo/keycloak:9.0.0 --push .
Additional info:
https://hub.docker.com/r/jboss/keycloak/dockerfile
https://github.com/keycloak/keycloak-containers/
https://docs.docker.com/docker-for-mac/multi-arch/
| Component name | Roles |
|---|---|
| Repository | repository image-registry node-exporter firewall filebeat docker |
| Kubernetes | kubernetes-control plane kubernetes-node applications node-exporter haproxy_runc kubernetes_common |
| Kafka | zookeeper jmx-exporter kafka kafka-exporter node-exporter |
| ELK (Logging) | logging elasticsearch elasticsearch_curator logstash kibana node-exporter |
| Exporters | node-exporter kafka-exporter jmx-exporter haproxy-exporter postgres-exporter |
| PostgreSQL | postgresql postgres-exporter node-exporter |
| Keycloak | applications |
| RabbitMQ | rabbitmq node-exporter |
| HAProxy | haproxy haproxy-exporter node-exporter haproxy_runc |
| Monitoring | prometheus grafana node-exporter |
Except above table, components require following roles to be checked:
Known issues:
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| adduser | + | + | |
| apt-transport-https | + | + | |
| auditd | + | + | |
| bash-completion | + | + | |
| build-essential | + | + | |
| ca-certificates | + | + | |
| cifs-utils | + | + | |
| containerd.io | + | + | |
| cri-tools | + | + | |
| curl | + | + | |
| docker-ce | + | + | |
| docker-ce-cli | + | + | |
| ebtables | + | + | |
| elasticsearch-curator | + | + | |
| elasticsearch-oss | + | + | |
| erlang-asn1 | + | + | |
| erlang-base | + | + | |
| erlang-crypto | + | + | |
| erlang-eldap | + | + | |
| erlang-ftp | + | + | |
| erlang-inets | + | + | |
| erlang-mnesia | + | + | |
| erlang-os-mon | + | + | |
| erlang-parsetools | + | + | |
| erlang-public-key | + | + | |
| erlang-runtime-tools | + | + | |
| erlang-snmp | + | + | |
| erlang-ssl | + | + | |
| erlang-syntax-tools | + | + | |
| erlang-tftp | + | + | |
| erlang-tools | + | + | |
| erlang-xmerl | + | + | |
| ethtool | + | + | |
| filebeat | + | + | |
| firewalld | + | + | |
| fping | + | + | |
| gnupg2 | + | + | |
| grafana | + | + | |
| haproxy | + | + | |
| htop | + | + | |
| iftop | + | + | |
| jq | + | + | |
| libfontconfig1 | + | + | |
| logrotate | + | + | |
| logstash-oss | + | + | |
| netcat | + | + | |
| net-tools | + | + | |
| nfs-common | + | + | |
| opendistro-alerting | + | + | |
| opendistro-index-management | + | + | |
| opendistro-job-scheduler | + | + | |
| opendistro-performance-analyzer | + | + | |
| opendistro-security | + | + | |
| opendistro-sql | + | + | |
| opendistroforelasticsearch-kibana | + | + | |
| openjdk-8-jre-headless | + | + | |
| openssl | + | + | |
| postgresql-10 | + | + | |
| python-pip | + | + | |
| python-psycopg2 | + | + | |
| python-selinux | + | + | |
| python-setuptools | + | + | |
| rabbitmq-server | + | + | |
| smbclient | + | + | |
| samba-common | + | + | |
| smbclient | + | + | |
| software-properties-common | + | + | |
| sshpass | + | + | |
| sysstat | + | + | |
| tar | + | + | |
| telnet | + | + | |
| tmux | + | + | |
| unzip | + | + | |
| vim | + | + | |
| rsync | + | + | |
| libcurl4 | + | + | |
| libnss3 | + | + | |
| libcups2 | + | + | |
| libavahi-client3 | + | + | |
| libavahi-common3 | + | + | |
| libjpeg8 | + | + | |
| libfontconfig1 | + | + | |
| libxtst6 | + | + | |
| fontconfig-config | + | + | |
| python-apt | + | + | |
| python | + | + | |
| python2.7 | + | + | |
| python-minimal | + | + | |
| python2.7-minimal | + | + | |
| gcc | + | + | |
| gcc-7 | + | + | |
| g++ | + | + | |
| g++-7 | + | + | |
| dpkg-dev | + | + | |
| libc6-dev | + | + | |
| cpp | + | + | |
| cpp-7 | + | + | |
| libgcc-7-dev | + | + | |
| binutils | + | + | |
| gcc-8-base | + | + | |
| libodbc1 | + | + | |
| apache2 | + | + | |
| apache2-bin | + | + | |
| apache2-utils | + | + | |
| libjq1 | + | + | |
| gnupg | + | + | |
| gpg | + | + | |
| gpg-agent | + | + | |
| smbclient | + | + | |
| samba-libs | + | + | |
| libsmbclient | + | + | |
| postgresql-client-10 | + | + | |
| postgresql-10-pgaudit | + | + | |
| postgresql-10-repmgr | + | + | |
| postgresql-common | + | + | |
| pgbouncer | + | + | |
| ipset | + | + | |
| libipset3 | + | + | |
| python3-decorator | + | + | |
| python3-selinux | + | + | |
| python3-slip | + | + | |
| python3-slip-dbus | + | + | |
| libpq5 | + | + | |
| python3-psycopg2 | + | + | |
| python3-jmespath | + | + | |
| libpython3.6 | + | + | |
| python-cryptography | + | + | |
| python-asn1crypto | + | + | |
| python-cffi-backend | + | + | |
| python-enum34 | + | + | |
| python-idna | + | + | |
| python-ipaddress | + | + | |
| python-six | + | + | |
| kubeadm | + | + | |
| kubectl | + | + | |
| kubelet | + | + | |
| kubernetes-cni | + | + | |
| Name | ARM Supported | Info | Required |
|---|---|---|---|
| haproxy:2.2.2-alpine | + | arm64v8/haproxy | + |
| kubernetesui/dashboard:v2.3.1 | + | + | |
| kubernetesui/metrics-scraper:v1.0.7 | + | + | |
| registry:2 | + | ||
| hashicorp/vault-k8s:0.7.0 | --- | https://hub.docker.com/r/moikot/vault-k8s / custom build | --- |
| vault:1.7.0 | + | --- | |
| apacheignite/ignite:2.9.1 | --- | https://github.com/apache/ignite/tree/master/docker/apache-ignite / custom build | --- |
| bitnami/pgpool:4.1.1-debian-10-r29 | --- | --- | |
| brainsam/pgbouncer:1.12 | --- | --- | |
| istio/pilot:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/proxyv2:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| istio/operator:1.8.1 | --- | https://github.com/istio/istio/issues/21094 / custom build | --- |
| jboss/keycloak:4.8.3.Final | --- | + | |
| jboss/keycloak:9.0.0 | --- | + | |
| rabbitmq:3.8.9 | + | + | |
| coredns/coredns:1.5.0 | + | + | |
| quay.io/coreos/flannel:v0.11.0 | + | + | |
| calico/cni:v3.8.1 | + | + | |
| calico/kube-controllers:v3.8.1 | + | + | |
| calico/node:v3.8.1 | + | + | |
| calico/pod2daemon-flexvol:v3.8.1 | + | + | |
| k8s.gcr.io/kube-apiserver:v1.18.6 | + | k8s.gcr.io/kube-apiserver-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-controller-manager:v1.18.6 | + | k8s.gcr.io/kube-controller-manager-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-scheduler:v1.18.6 | + | k8s.gcr.io/kube-scheduler-arm64:v1.18.6 | + |
| k8s.gcr.io/kube-proxy:v1.18.6 | + | k8s.gcr.io/kube-proxy-arm64:v1.18.6 | + |
| k8s.gcr.io/coredns:1.6.7 | --- | coredns/coredns:1.6.7 | + |
| k8s.gcr.io/etcd:3.4.3-0 | + | k8s.gcr.io/etcd-arm64:3.4.3-0 | + |
| k8s.gcr.io/pause:3.2 | + | k8s.gcr.io/pause-arm64:3.2 | + |
Build multi arch image for Keycloak 9:
Clone repo: https://github.com/keycloak/keycloak-containers/
Checkout tag: 9.0.0
Change dir to: keycloak-containers/server
Create new builder: docker buildx create --name mybuilder
Switch to builder: docker buildx use mybuilder
Inspect builder and make sure it supports linux/amd64, linux/arm64: docker buildx inspect --bootstrap
Build and push container: docker buildx build --platform linux/amd64,linux/arm64 -t repo/keycloak:9.0.0 --push .
Additional info:
https://hub.docker.com/r/jboss/keycloak/dockerfile
https://github.com/keycloak/keycloak-containers/
https://docs.docker.com/docker-for-mac/multi-arch/
| Component name | Roles |
|---|---|
| Repository | repository image-registry node-exporter firewall filebeat docker |
| Kubernetes | kubernetes-control plane kubernetes-node applications node-exporter haproxy_runc kubernetes_common |
| Kafka | zookeeper jmx-exporter kafka kafka-exporter node-exporter |
| ELK (Logging) | logging elasticsearch elasticsearch_curator logstash kibana node-exporter |
| Exporters | node-exporter kafka-exporter jmx-exporter haproxy-exporter postgres-exporter |
| PostgreSQL | postgresql postgres-exporter node-exporter |
| Keycloak | applications |
| RabbitMQ | rabbitmq node-exporter |
| HAProxy | haproxy haproxy-exporter node-exporter haproxy_runc |
| Monitoring | prometheus grafana node-exporter |
Except above table, components require following roles to be checked: