2 -
Context
This design document presents findings on what are important pieces of modules communication in Dockerized Custom Modules approach described here.
Plan
Idea is to have something running and working mimicking real world modules. I used GNU make to perform this. With GNU make I was able to easily implement “run” logic. I also wanted to package everything into docker images to experience real world containers limitations of communication, work directory sharing and other stuff.
Dependencies problem
First list of modules is presented here:
version: v1
kind: Repository
components:
- name: c1
type: docker
versions:
- version: 0.1.0
latest: true
image: "docker.io/hashicorp/terraform:0.12.28"
workdir: "/terraform"
mounts:
- "/terraform"
commands:
- name: init
description: "initializes terraform in local directory"
command: init
envs:
TF_LOG: WARN
- name: apply
description: "applies terraform in local directory"
command: apply
envs:
TF_LOG: DEBUG
args:
- -auto-approve
... didn't have any dependencies section. We know that some kind of dependencies will be required very soon. I created idea of how to define dependencies between modules in following mind map:
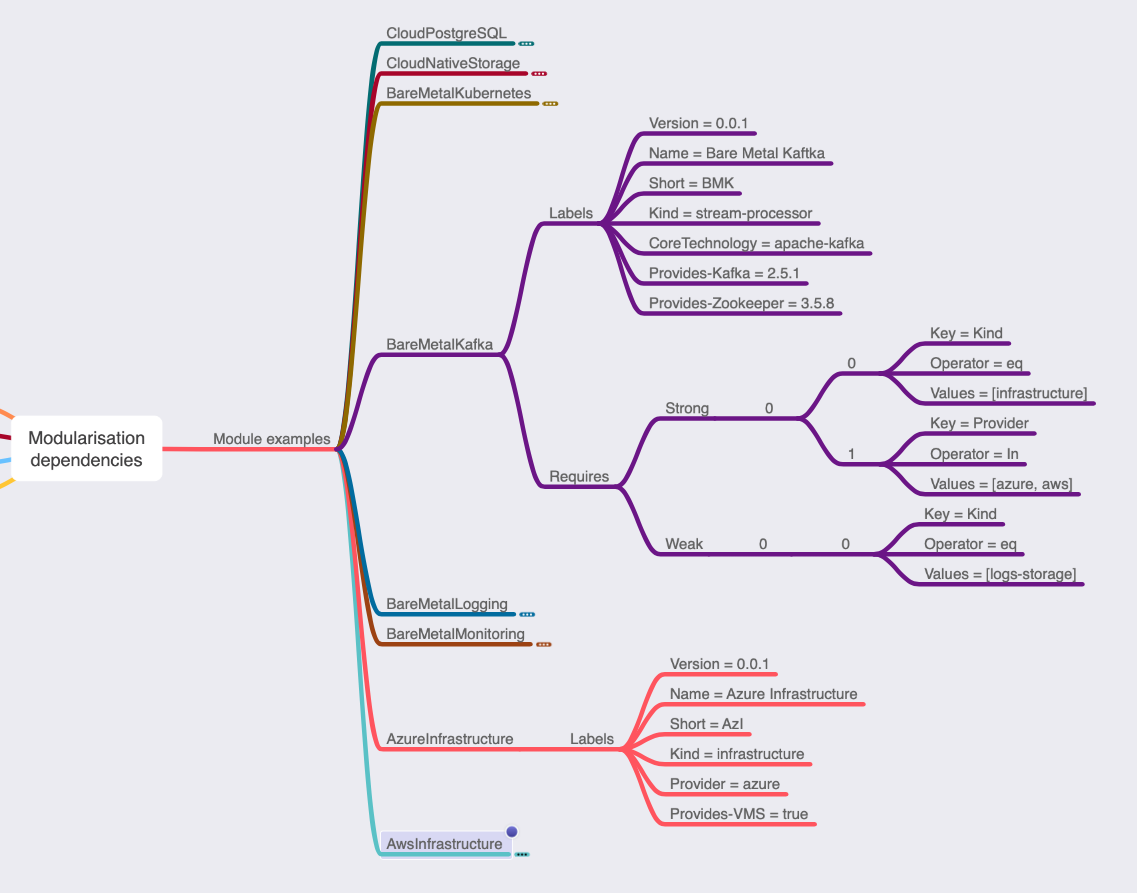
It shows following things:
- every module has some set of labels. I don't think we need to have any "obligatory" labels. If you create very custom ones you will be very hard to find.
- module has
requires section with possible subsections strong and weak. A strong requirement is one has to be fulfilled for the module to be applied. A weak requirement, on the other hand, is something we can proceed without, but it is in some way connected when present.
It's worth co notice each requires rule. I used kubernetes matchExpressions approach as main way of defining dependencies, as one of main usage here would be "version >= X", and we cannot use simple labels matching mechanism without being forced to update all modules using my module every time I release a new version of that module.
Influences
I started to implement example docker based mocked modules in tests directory, and I found a 3rd section required: influences. To explain this lets notice one folded module in upper picture: "BareMetalMonitoring". It is Prometheus based module so, as it works in pull mode, it needs to know about addresses of machines it should monitor. Let's imagine following scenario:
- I have Prometheus already installed, and it knows about IP1, IP2 and IP3 machines to be monitored,
- in next step I install, let's say
BareMetalKafka module,
- so now, I want Prometheus to monitor Kafka machines as well,
- so, I need
BareMetalKafka module to "inform" in some way BareMetalMonitoring module to monitor IP4, IP5 and IP6 addresses to addition of what it monitors already.
This example explains "influences" section. Mocked example is following:
labels:
version: 0.0.1
name: Bare Metal Kafka
short: BMK
kind: stream-processor
core-technology: apache-kafka
provides-kafka: 2.5.1
provides-zookeeper: 3.5.8
requires:
strong:
- - key: kind
operator: eq
values: [infrastructure]
- key: provider,
operator: in,
values:
- azure
- aws
weak:
- - key: kind
operator: eq
values:
- logs-storage
- - key: kind
operator: eq
values:
- monitoring
- key: core-technology
operator: eq
values:
- prometheus
influences:
- - key: kind
operator: eq
values:
- monitoring
As presented there is influences section notifying that "there is something what that I'll do to selected module (if it's present)". I do not feel urge to define it more strictly at this point in time before development. I know that this kind of influences section will be required, but I do not know exactly how it will end up.
Results
During implementation of mocks I found that:
influences section would be required- name of method
validate-config (or later just validate) should in fact be plan
- there is no need to implement method
get-state in module container provider as state will be local and shared between modules. In fact some state related operations would be probably implemented on cli wrapper level.
- instead, there is need of
audit method which would be extremely important to check if no manual changes were applied to remote infrastructure
Required methods
As already described there would be 5 main methods required to be implemented by module provider. Those are described in next sections.
That is simple method to display static YAML/JSON (or any kind of structured data) information about the module. In fact information from this method should be exactly the same to what is in repo file section about this module. Example output of metadata method might be:
labels:
version: 0.0.1
name: Bare Metal Kafka
short: BMK
kind: stream-processor
core-technology: apache-kafka
provides-kafka: 2.5.1
provides-zookeeper: 3.5.8
requires:
strong:
- - key: kind
operator: eq
values: [infrastructure]
- key: provider,
operator: in,
values:
- azure
- aws
weak:
- - key: kind
operator: eq
values:
- logs-storage
- - key: kind
operator: eq
values:
- monitoring
- key: core-technology
operator: eq
values:
- prometheus
influences:
- - key: kind
operator: eq
values:
- monitoring
Init
init method main purpose is to jump start usage of module by generating (in smart way) configuration file using information in state. In example Makefile which is stored here you can test following scenario:
make cleanmake init-and-apply-azure-infrastructure- observe what is in
./shared/state.yml file:
azi:
status: applied
size: 5
provide-pubips: true
nodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
usedBy: unused
- privateIP: 10.0.0.1
publicIP: 213.1.1.1
usedBy: unused
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
usedBy: unused
- privateIP: 10.0.0.3
publicIP: 213.1.1.3
usedBy: unused
- privateIP: 10.0.0.4
publicIP: 213.1.1.4
usedBy: unused
it mocked that it created some infrastructure with VMs having some fake IPs.
- change IP manually a bit to observe what I mean by "smart way"
azi:
status: applied
size: 5
provide-pubips: true
nodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
usedBy: unused
- privateIP: 10.0.0.100 <---- here
publicIP: 213.1.1.100 <---- and here
usedBy: unused
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
usedBy: unused
- privateIP: 10.0.0.3
publicIP: 213.1.1.3
usedBy: unused
- privateIP: 10.0.0.4
publicIP: 213.1.1.4
usedBy: unused
make just-init-kafka- observe what was generated in
./shared/bmk-config.yml
bmk:
size: 3
clusterNodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
- privateIP: 10.0.0.100
publicIP: 213.1.1.100
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
it used what it found in state file and generated config to actually work with given state.
make and-then-apply-kafka- check it got applied to state file:
azi:
status: applied
size: 5
provide-pubips: true
nodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
usedBy: bmk
- privateIP: 10.0.0.100
publicIP: 213.1.1.100
usedBy: bmk
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
usedBy: bmk
- privateIP: 10.0.0.3
publicIP: 213.1.1.3
usedBy: unused
- privateIP: 10.0.0.4
publicIP: 213.1.1.4
usedBy: unused
bmk:
status: applied
size: 3
clusterNodes:
- privateIP: 10.0.0.0
publicIP: 213.1.1.0
state: created
- privateIP: 10.0.0.100
publicIP: 213.1.1.100
state: created
- privateIP: 10.0.0.2
publicIP: 213.1.1.2
state: created
So init method is not just about providing "default" config file, but to actually provide "meaningful" configuration file. What is significant here, is that it's very easily testable if that method generates desired state when given different example state files.
Plan
plan method is a method to:
- validate that config file has correct structure,
- get state file, extract module related piece and compare it to config to "calculate" if there are any changes required and if yes, than what are those.
This method should be always started before apply by cli wrapper.
General reason to this method is that after we "smart initialized" config, we might have wanted to change some values some way, and then it has to be validated. Another scenario would be influence mechanism I described in Influences section. In that scenario it's easy to imagine that output of BMK module would produce proposed changes to BareMetalMonitoring module or even apply them to its config file. That looks obvious, that automatic "apply" operation on BareMetalMonitoring module is not desired option. So we want to suggest to the user "hey, I applied Kafka module, and usually it influences the configuration of Monitoring module, so go ahead and do plan operation on it to check changes". Or we can even do automatic "plan" operation and show what are those changes.
Apply
apply is main "logic" method. Its purpose is to do 2 things:
- apply module logic (i.e.: install software, modify a config, manage service, install infrastructure, etc.),
- update state file.
In fact, you might debate which of those is more important, and I could argue that updating state file is more important.
To perform its operations it uses config file previously validated in plan step.
Audit
audit method use case is to check how existing components is "understandable" by component provider logic. A standard situation would be upgrade procedure. We can imagine following history:
- I installed
BareMetalKafka module in version 0.0.1
- Then I manually customized configuration on cluster machines
- Now I want to update
BareMetalKafka to version 0.0.2 because it provides something I need
In such a scenario, checking if upgrade operation will succeed is critical one, and that is duty of audit operation. It should check on cluster machines if "known" configuration is still "known" (whatever it means for now) and that upgrade operation will not destroy anything.
Another use case for audit method is to reflect manually introduced changes into the configuration (and / or state). If I manually upgraded minor version of some component (i.e.: 1.2.3 to 1.2.4) it's highly possible that it might be easily reflected in state file without any trouble to other configuration.
Optional methods
There are also already known methods which would be required to have most (or maybe all) modules, but are not core to modules communication. Those are purely "internal" module business. Following examples are probably just subset of optional methods.
Backup / Restore
Provide backup and restore functionalities to protect data and configuration of installed module.
Update
Perform steps to update module components to newer versions with data migration, software re-configuration, infrastructure remodeling and any other required steps.
Scale
Operations related to scale up and scale down module components.
Check required methods implementation
All accessible methods would be listed in module metadata as proposed here. That means that it's possible to:
- validate if there are all required methods implemented,
- validate if required methods return in expected way,
- check if state file is updated with values expected by other known modules.
All that means that we would be able to automate modules release process, test it separately and validate its compliance with modules requirements.
Future work
We should consider during development phase if and how to present in manifest what are external fields that module requires for apply operation. That way we might be able to catch inconsistencies between what one module provide and what another module require form it.
Another topic to consider is some standardization over modules labeling.
3 -
Ansible based module
Purpose
To provide separation of concern on middleware level code we need to have consistent way to produce ansible based modules.
Requirements
There are following requirements for modules:
- Allow two-ways communication with other modules via Statefile
- Allow a reuse of ansible roles between modules
Design
Components
- Docker – infrastructure modules are created as Docker containers so far so this approach should continue
- Ansible – we do have tons of ansible code which could be potentially reused. Ansible is also a de facto industry standard for software provisioning, configuration management, and application deployment.
- Ansible-runner – due to need of automation we should use ansible-runner application which is a wrapper for ansible commands (i.e.: ansible-playbook) and provides good code level integration features (i.e.: passing of variables to playbook, extracting logs, RC and facts cache). It is originally used in AWX.
- E-structures – we started to use e-structures library to simplify interoperability between modules.
- Ansible Roles – we need to introduce more loosely coupled ansible code while extracting it from main LambdaStack code repository. To achieve it we need to utilize ansible roles in “ansible galaxy” way, which means each role should be separately developed, tested and versioned. To coordinate multiple roles between they should be connected in a modules single playbook.
Commands
Current state of understanding of modules is that we should have at least two commands:
- Init – would be responsible to build configuration file for the module. In design, it would be exactly the same as “init” command in infrastructure modules.
- Apply – that command would start ansible logic using following order:
- Template inventory file – command would get configuration file and using its values, would generate ansible inventory file with all required by playbook variables.
- Provide ssh key file – command would copy provided in “shared” directory key into expected location in container
There is possibility also to introduce additional “plan” command with usage of “—diff” and “—check” flags for ansible playbook but:
- It doesn't look like required step like in terraform-based modules
- It requires additional investigation for each role how to implement it.
Structure
Module repository should have structure similar to following:
- Directory “cmd” – Golang entrypoint binary files should be located here.
- Directory “resources” – would be root for ansible-runner “main” directory
- Subdirectory “project” – this directory should contain entrypoint.yml file being main module playbook.
- Subdirectory “roles” – this optional directory should contain local (not shared) roles. Having this directory would be considered “bad habit”, but it's possible.
- Files in “root” directory – Makefile, Dockerfile, go.mod, README.md, etc.
4 -
LambdaStack modular design document
Affected version: 0.4.x
Goals
Make lambdastack easier to work on with multiple teams and make it easier to maintain/extend by:
- Splitting up the monotithic LambdaStack into seperate modules which can run as standalone CLI tools or be linked together through LambdaStack.
- Create an extendable plug and play system for roles which can be assigned to components based on certain tasks: apply, upgrade, backup, restore, test etc
Architectural design
The current monolithic lambdastack will be split up into the following modules.
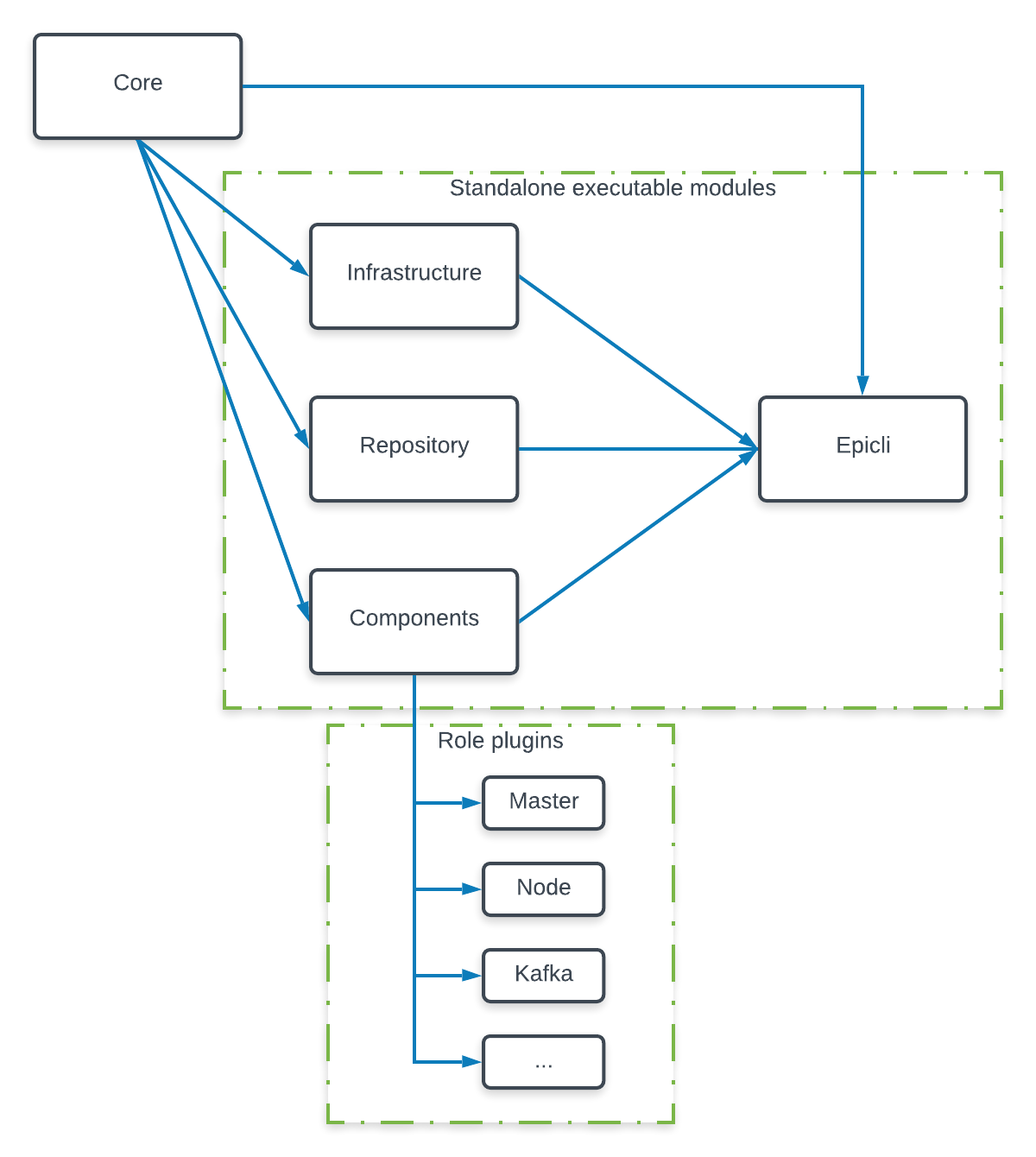
Core
Shared code between other modules and not executable as standalone. Responsible for:
- Config
- Logging
- Helpers
- Data schema handling: Loading, defaults, validating etv.
- Build output handling: Loading, saving, updating etc.
- Ansible runner
Infrastructure
Module for creating/destroying cloud infrastructure on AWS/Azure/Google... + "Analysing" existing infrastructure. Maybe at a later time we want to split up the different cloud providers into plugins as well.
Functionality (rough outline and subjected to change):
- template:
"lambdastack infra template -f outfile.yaml -p awz/azure/google/any (--all)"
"infra template -f outfile.yaml -p awz/azure/google/any (--all)"?
"Infrastructure.template(...)"
Task: Generate a template yaml with lambdastack-cluster definition + possible infra docs when --all is defined
Input: File to output data, provider and possible all flag
Output: outfile.yaml template
- apply:
"lambdastack infra apply -f data.yaml"
"infra apply -f data.yaml"?
"Infrastructure.apply(...)"
Task: Create/Update infrastucture on AWS/Azure/Google...
Input: Yaml with at least lambdastack-cluster + possible infra docs
Output: manifest, ansible inventory and terrafrom files
- analyse:
"lambdastack infra analyse -f data.yaml"
"infra analyse -f data.yaml"?
"Infrastructure.analyse(...)"
Task: Analysing existing infrastructure
Input: Yaml with at least lambdastack-cluster + possible infra docs
Output: manifest, ansible inventory
- destroy:
"lambdastack infra destroy -b /buildfolder/"
"infra destroy -b /buildfolder/"?
"Infrastructure.destroy(...)"
Task: Destroy all infrastucture on AWS/Azure/Google?
Input: Build folder with manifest and terrafrom files
Output: Deletes the build folder.
Repository
Module for creating and tearing down a repo + preparing requirements for offline installation.
Functionality (rough outline and subjected to change):
- template:
"lambdastack repo template -f outfile.yaml (--all)"
"repo template -f outfile.yaml (--all)"?
"Repository.template(...)"
Task: Generate a template yaml for a repository
Input: File to output data, provider and possible all flag
Output: outfile.yaml template
- prepare:
"lambdastack repo prepare -os (ubuntu-1904/redhat-7/centos-7)"
"repo prepare -o /outputdirectory/"?
"Repo.prepare(...)"
Task: Create the scripts for downloading requirements for a repo for offline installation for a certain OS.
Input: Os which we want to output the scripts for: (ubuntu-1904/redhat-7/centos-7)
Output: Outputs the scripts scripts
- create:
"lambdastack repo create -b /buildfolder/ (--offline /foldertodownloadedrequirements)"
"repo create -b /buildfolder/"?
"Repo.create(...)"
Task: Create the repository on a machine (either by running requirement script or copying already prepared ) and sets up the other VMs/machines to point to said repo machine. (Offline and offline depending on --offline flag)
Input: Build folder with manifest and ansible inventory and posible offline requirements folder for onprem installation.
Output: repository manifest or something only with the location of the repo?
- teardown:
"lambdastack repo teardown -b /buildfolder/"
"repo teardown -b /buildfolder/"?
"Repo.teardown(...)"
Task: Disable the repository and resets the other VMs/machines to their previous state.
Input: Build folder with manifest and ansible inventory
Output: -
Components
Module for applying a command on a component which can contain one or multiple roles. It will take the Ansible inventory to determine which roles should be applied to which component. The command each role can implement are (rough outline and subjected to change):
- apply: Command to install roles for components
- backup: Command to backup roles for components
- restore: Command to backup roles for components
- upgrade: Command to upgrade roles for components
- test: Command to upgrade roles for components
The apply command should be implemented for every role but the rest is optional. From an implementation perspective each role will be just a seperate folder inside the plugins directory inside the components module folder with command folders which will contain the ansible tasks:
components-|
|-plugins-|
|-master-|
| |-apply
| |-backup
| |-restore
| |-upgrade
| |-test
|
|-node-|
| |-apply
| |-backup
| |-restore
| |-upgrade
| |-test
|
|-kafka-|
| |-apply
| |-upgrade
| |-test
Based on the Ansible inventory and the command we can easily select which roles to apply to which components. For the commands we probably also want to introduce some extra flags to only execute commands for certain components.
Finally we want to add support for an external plugin directory where teams can specify there own role plguins which are not (yet) available inside LambdaStack itself. A feature that can also be used by other teams to more easily start contributing developing new components.
LambdaStack
Bundles all executable modules (Infrastructure, Repository, Component) and adds functions to chain them together:
Functionality (rough outline and subjected to change):
- template:
"lambdastack template -f outfile.yaml -p awz/azure/google/any (--all)"
"LambdaStack.template(...)"
Task: Generate a template yaml with lambdastack-cluster definition + possible infrastrucure, repo and component configurations
Input: File to output data, provider and possible all flag
Output: outfile.yaml with templates
- apply:
"lambdastack apply -f input.yaml"
"LambdaStack.template(...)"
Task: Sets up a cluster from start to finish
Input: File to output data, provider and possible all flag
Output: Build folder with manifest, ansible inventory, terrafrom files, component setup.
...
5 -
Intent
This document tries to compare 3 existing propositions to implement modularization.
Compared models
To introduce modularization in LambdaStack we identified 3 approaches to consider. Following sections will describe briefly those 3 approaches.
Dockerized custom modules
This approach would look following way:
- Each component management code would be packaged into docker containers
- Components would need to provide some known call methods to expose metadata (dependencies, info, state, etc.)
- Each component would be managed by one management container
- Components (thus management containers) can depend on each other in ‘pre-requisite’ manner (not runtime dependency, but order of executions)
- Separate wrapper application to call components execution and process metadata (dependencies, info, state, etc.)
All that means that if we would like to install following stack:
- On-prem Kubernetes cluster
- Rook Operator with Ceph cluster working on that on-prem cluster
- PostgreSQL database using persistence provided by Ceph cluster,
Then steps would need to look somehow like this:
- CLI command to install PostgreSQL
- It should check pre-requisites and throw an error that it cannot be installed because there is persistence layer missing
- CLI command to search persistence layer
- It would provide some possibilities
- CLI command to install rook
- It should check pre-requisites and throw an error that it cannot be installed because there is Kubernetes cluster missing
- CLI command to search Kubernetes cluster
- It would provide some possibilities
- CLI command to install on-prem Kubernetes
- It should perform whole installation process
- CLI command to install rook
- It should perform whole installation process
- CLI command to install PostgreSQL
- It should perform whole installation process
This approach would mean following:
- We reuse most of terraform providers to provide infrastructure
- We reuse Kubernetes provider to deliver Kubernetes resources
- We provide “operator” applications to wrap ansible parts in terraform-provider consumable API (???)
- Separate wrapper application to instantiate “operator” applications and execute terraform
All that means that if we would like to install following stack:
- On-prem Kubernetes cluster
- Rook Operator with Ceph cluster working on that on-prem cluster
- PostgreSQL database using persistence provided by Ceph cluster,
Then steps would need to look somehow like this:
- Prepare terraform configuration setting up infrastructure containing 3 required elements
- CLI command to execute that configuration
- It would need to find that there is on-prem cluster provider which does not have where to connect, and it needs to instantiate “operator” container
- It instantiates “operator” container and exposes API
- It executes terraform script
- It terminates “operator” container
Kubernetes operators
This approach would mean following:
- To run anything, we need Kubernetes cluster of any kind (local Minikube is good as well)
- We provide Kubernetes CR’s to operate components
- We would reuse some existing operators
- We would need to create some operators on our own
- There would be need to separate mechanism to create “on-prem” Kubernetes clusters (might be operator too)
All that means that if we would like to install following stack:
- On-prem Kubernetes cluster
- Rook Operator with Ceph cluster working on that on-prem cluster
- PostgreSQL database using persistence provided by Ceph cluster,
Then steps would need to look somehow like this:
- Start Minikube instance on local node
- Provide CRD of on-prem Kubernetes operator
- Deploy on-prem Kubernetes operator
- Wait until new cluster is deployed
- Connect to it
- Deploy rook operator definition
- Deploy PostgreSQL operator definition
Comparision
| Question |
Dockerized custom modules (DCM) |
Terraform providers (TP) |
Kubernetes operators (KO) |
| How much work does it require to package lambdastack to first module? |
Customize entrypoint of current image to provide metadata information. |
Implement API server in current image to expose it to TP. |
Implement ansible operator to handle CR’s and (possibly?) run current image as tasks. |
| Sizes: |
3XL |
Too big to handle. We would need to implement just new modules that way. |
5XL |
| How much work does it require to package module CNS? |
From kubectl image, provide some parameters, provide CRD’s, provide CR’s |
Use (possibly?) terraform-provider-kubernetes. Prepare CRD’s, prepare CR’s. No operator required. |
Just deploy Rook CRD’s, operator, CR’s. |
| Sizes: |
XXL |
XL |
XL |
| How much work does it require to package module AKS/EKS? |
From terraform, provide some parameters, provide terraform scripts |
Prepare terraform scripts. No operator required. |
[there is something called rancher/terraform-controller and it tries to be what we need. It’s alpha] Use (possibly?) rancher terraform-controller operator, provide DO module with terraform scripts. |
| Sizes: |
XL |
L |
XXL |
| How would be dependencies handled? |
Not defined so far. It seems that using kind of “selectors” to check if modules are installed and in state “applied” or something like this. |
Standard terraform dependencies tree. It’s worth to remember that terraform dependencies sometimes work very weird and if you change one value it has to call multiple places. We would need to assess how much dependencies there should be in dependencies. |
It seems that embedding all Kubernetes resources into helm charts, and adding dependencies between them could solve a problem. |
| Sizes: |
XXL |
XL |
XXL |
| Would it be possible to install CNS module on LambdaStack Kubernetes in version 0.4.4? |
yes |
yes |
yes |
| If I want to install CNS, how would dependencies be provided? |
By selectors mechanism (that is proposition) |
By terraform tree |
By helm dependencies |
| Let’s assume that in version 0.8.0 of LambdaStack PostgreSQL is migrated to new component (managed not in lambdastack config). How would migration from 0.7.0 to 0.8.0 on existing environments be processed? |
Proposition is, that for this kind of operations we can create separate “image” to conduct just that upgrade operation. So for example ls-o0-08-upgrader. It would check that environment v0.7.x had PostgreSQL installed, then it would generate config for new PostgreSQL module, it would initialize that module and it would allow upgrade of lambdastack module to v0.8.x |
It doesn’t look like there is a way to do it automatically by terraform. You would need to add new PostgreSQL terraform configuration and import existing state into it, then remove PostgreSQL configuration from old module (while preventing it from deletion of resources). If you are advanced terraform user it still might be tricky. I’m not sure if we are able to handle it for user. |
We would need to implement whole functionality in operator. Basically very similar to DCM scenario, but triggered by CR change. |
| Sizes: |
XXL |
Unknown |
3XL |
| Where would module store it’s configuration? |
Locally in ~/.e/ directory. In future we can implement remote state (like terraform remote backend) |
All terraform options. |
As Kubernetes CR. |
| How would status of components be gathered by module? |
We would need to implement it. |
Standard terraform output and datasource mechanisms. |
Status is continuously updated by operator in CR so there it is. |
| Sizes: |
XL |
XS |
S |
| How would modules pass variables between each other? |
CLI wrapper should be aware that one module needs other module output and it should call module1 get-output and pass that json or part of it to module2 apply |
Standard terraform. |
Probably by Config resources. But not defined. |
| Sizes: |
XXL |
XS |
XL |
| How would upstream module notify downstream that something changed in it’s values? |
We would need to implement it. |
Standard terraform tree update. Too active changes in a tree should be considered here as in dependencies. |
It’s not clear. If upstream module can change downstream Config resource (what seems to be ridiculous idea) than it’s simple. Other way is that downstream periodically checks upstream Config for changes, but that introduces problems if we use existing operators. |
| Sizes: |
XXL |
XL |
XXL |
| Sizes summary: |
1 3XL, 5 XXL, 2 XL |
1 Too big, 1 Unknown, 3 XL, 1 L, 2 XS |
1 5XL, 1 3XL, 3 XXL, 2 XL, 1 S |
Conclusions
Strategic POV
DCM and KO are interesting. TP is too strict and not elastic enough.
Tactic POV
DCM has the smallest standard deviation when you look at task sizes. It indicates the smallest risk. TP is on the opposite side of list with the biggest estimations and some significant unknowns.
Fast gains
If we were to consider only cloud provided resources TP is the fastest way. Since we need to provide multiple different resources and work on-prem it is not that nice. KO approach looks like something interesting, but it might be hard at the beginning. DCM looks like simplest to implement with backward compatibility.
Risks
DCM has significant risk of “custom development”. KO has risks related to requirement to use operator-framework and its concept, since very beginning of lsc work. TP has huge risks related to on-prem operational overhead.
Final thoughts
Risks related to DCM are smallest and learning curve looks best. We would also be able to be backward compatible in relatively simple way.
DCM looks like desired approach.
6 -
Offline modes in modularised LambdaStack
Context
Due to ongoing modularization process and introduction of middleware modules we need to decide how modules would obtain required dependencies for “offline” mode.
This document will describe installation and upgrade modes and will discuss ways to implement whole process considered during design process.
Assumptions
Each module has access to the “/shared” directory. Most wanted way to use modules is via “e” command line app.
Installation modes
There are 2 main identified ways (each with 2 mutations) to install LambdaStack cluster.
- Online - it means that one machine in a cluster has access to public internet. We would call this machine repository machine, and that scenario would be named "Jump Host". A specific scenario in this group is when all machines have access to internet. We are not really interested in that scenario because in all scenarios we want all cluster machines to download required elements from repository machine. We would call this scenario "Full Online"
- Offline - it means that none of machines in a cluster have access to public internet. There are also two versions of this scenario. First version assumes that installation process is initialized on operators machine (i.e.: his/her laptop). We would call this scenario "Bastion v1". Second scenario is when all installation initialization process is executed directly from "Downloading Machine". We would call that scenario "Bastion v2".
Following diagrams present high-level overview of those 4 scenarios:




Key machines
Described in the previous section scenarios show that there is couple machine roles identified in installation process. Following list explains those roles in more details.
- Repository - key role in whole lifecycle process. This is central cluster machine containing all the dependencies, providing images repository for the cluster, etc.
- Cluster machine - common cluster member providing computational resources to middleware being installed on it. This machine has to be able to see Repository machine.
- Downloading machine - this is a temporary machine required to download OS packages for the cluster. This is known process in which we download OS packages on a machine with access to public internet, and then we transfer those packages to Repository machine on which they are accessible to all the cluster machines.
- Laptop - terminal machine for a human operator to work on. There is no formal requirement for this machine to exist or be part of process. All operations performed on that machine could be performed on Repository or Downloading machine.
Downloading
This section describes identified ways to provide dependencies to cluster. There is 6 identified ways. All of them are described in following subsections with pros and cons.
Option 1
Docker image for each module has all required binaries embedded in itself during build process.
Pros
- There is no “download requirements” step.
- Each module has all requirements ensured on build stage.
Cons
- Module image is heavy.
- Possible licensing issues.
- Unknown versions of OS packages.
Option 2
There is separate docker image with all required binaries for all modules embedded in itself during build process.
Pros
- There is no “download requirements” step.
- All requirements are stored in one image.
Cons
- Image would be extremely large.
- Possible licensing issues.
- Unknown versions of OS packages.
Option 3
There is separate “dependencies” image for each module containing just dependencies.
Pros
- There is no “download requirements” step.
- Module image itself is still relatively small.
- Requirements are ensured on build stage.
Cons
- “Dependencies” image is heavy.
- Possible licensing issues.
- Unknown versions of OS packages.
Option 4
Each module has “download requirements” step and downloads requirements to some directory.
Pros
- Module is responsible for downloading its requirements on its own.
- Already existing “export/import” CLI feature would be enough.
Cons
- Offline upgrade process might be hard.
- Each module would perform the download process a bit differently.
Option 5
Each module has “download requirements” step and downloads requirements to docker named volume.
Pros
- Module is responsible for downloading its requirements on its own.
- Generic docker volume practices could be used.
Cons
- Offline upgrade process might be hard.
- Each module would perform the download process a bit differently.
Option 6
Each module contains “requirements” section in its configuration, but there is one single module downloading requirements for all modules.
Pros
- Module is responsible for creation of BOM and single “downloader” container satisfies needs of all the modules.
- Centralised downloading process.
- Manageable offline installation process.
Cons
Options discussion
- Options 1, 2 and 3 are probably unelectable due to licenses of components and possibly big or even huge size of produced images.
- Main issue with options 1, 2 and 3 is that it would only work for containers and binaries but not OS packages as these are dependent on the targeted OS version and installation. This is something we cannot foresee or bundle for.
- Options 4 and 5 will introduce possibly a bit of a mess related to each module managing downloads on its own. Also upgrade process in offline mode might be problematic due to burden related to provide new versions for each module separately.
- Option 6 sounds like most flexible one.
Export
Its visible in offline scenarios that "export" process is as important as "download" process. For offline scenarios "export" has to cover following elements:
- downloaded images
- downloaded binaries
- downloaded OS packages
- defined modules images
- e command line app
- e environment configuration
All those elements have to be packaged to archive to be transferred to the clusters Repository machine.
Import
After all elements are packaged and transferred to Repository machine they have to be imported into Repository. It is current impression that repository module would be responsible for import operation.
Summary
In this document we provide high level definition how to approach offline installation and upgrade. Current understanding is:
- each module provide list of it's requirements
- separate module collects those and downloads required elements
- the same separate module exports all artefacts into archive
- after the archive is transferred, repository module imports its content